لقد كان تقييم نماذج اللغة الكبيرة (LLMs) دائمًا تحديًا رئيسيًا في مجال معالجة اللغة الطبيعية. تستغرق طرق التقييم اليدوية التقليدية وقتًا طويلاً وتتطلب عمالة مكثفة، ولا يمكنها مواكبة التطور السريع لماجستير القانون. ولتحقيق هذه الغاية، قام فريق أبحاث Salesforce AI بتطوير SFR-Judge، وهي عائلة تقييم تتكون من ثلاثة ماجستير في القانون بأحجام مختلفة، مصممة لتوفير حلول تقييم آلية أسرع وأكثر كفاءة. سيمنحك محرر Downcodes فهمًا متعمقًا لابتكارات SFR-Judge وكيف يحل المشكلات في تقييم LLM.
في مجال معالجة اللغة الطبيعية، تطورت نماذج اللغة الكبيرة (LLMs) بسرعة وحققت تقدمًا كبيرًا في العديد من المجالات. ومع ذلك، مع زيادة تعقيد النماذج، يصبح من الأهمية بمكان تقييم مخرجاتها بدقة. تقليديًا، اعتمدنا على البشر للتقييم، لكن هذا النهج يستغرق وقتًا طويلاً ويصعب توسيع نطاقه لمواكبة الوتيرة السريعة لتطوير النموذج.
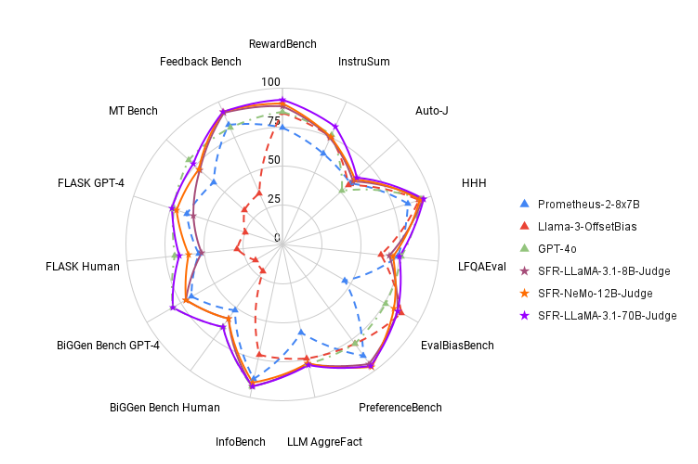
ولتغيير هذا الوضع، أطلق فريق أبحاث Salesforce AI SFR-Judge، وهي عائلة تقييم تتكون من ثلاثة نماذج لغوية كبيرة. تحتوي هذه النماذج على 8 مليارات و12 مليار و70 مليار معلمة على التوالي، وهي مبنية على Meta Llama3 وMistral NeMO. SFR-Judge قادر على أداء مجموعة متنوعة من مهام التقييم، بما في ذلك المقارنات الزوجية، والتسجيل الفردي، وتقييمات التصنيف الثنائية، وهو مصمم لمساعدة فرق البحث على تقييم أداء النماذج الجديدة بسرعة وكفاءة.
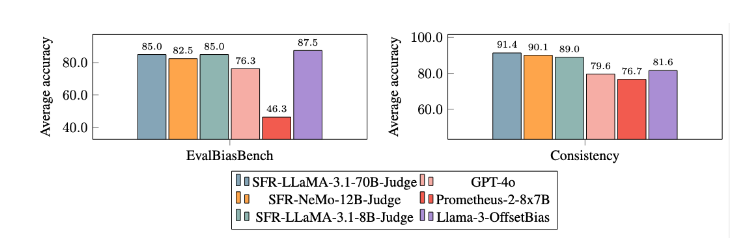
غالبًا ما تواجه نماذج تقييم LLM التقليدية بعض مشكلات التحيز، مثل تحيز الموضع وتحيز الطول، مما سيؤثر على حكمهم. ومن أجل التغلب على هذه المشكلات، يعتمد SFR-Judge أسلوب التدريب على تحسين التفضيل المباشر (DPO)، والذي يسمح للنموذج بالتعلم من الأمثلة الإيجابية والسلبية، وبالتالي تحسين قدرته على فهم مهمة التقييم، وتقليل التحيز، وضمان الاتساق من الحكم.
في الاختبار، كان أداء SFR-Judge جيدًا في 13 معيارًا، متفوقًا على العديد من نماذج التقييم الحالية، بما في ذلك بعض النماذج الخاصة. في تصنيفات RewardBench، وصلت دقة SFR-Judge إلى 92.7%، وهذه هي المرة الأولى والثانية التي يتجاوز فيها نموذج التقييم التوليدي عتبة 90%، مما يدل على أدائه الممتاز في نماذج التقييم.
تغطي طريقة تدريب SFR-Judge ثلاثة تنسيقات مختلفة للبيانات. الأول هو "نقد سلسلة الأفكار"، الذي يساعد النموذج على توليد تحليل منظم لاستجابة التقييم. والثاني هو "التقييم القياسي"، الذي يبسط عملية التقييم ويقدم تعليقات مباشرة حول ما إذا كانت الاستجابة تستوفي المعايير. وأخيرًا، يساعد "اشتقاق الاستجابة" النموذج على فهم خصائص الاستجابات عالية الجودة وتعزيز قدراته على الحكم. يؤدي الجمع بين تنسيقات البيانات الثلاثة هذه إلى تحسين قدرات تقييم SFR-Judge بشكل كبير.
وبعد تجارب مكثفة، كان أداء نموذج SFR-Judge أفضل بكثير من النماذج الأخرى في تقليل التحيز. في معيار EvalBiasBench، أظهروا درجة عالية من اتساق الترتيب الزوجي، مما يدل على أن أحكام النموذج تظل مستقرة حتى لو تغير ترتيب الاستجابة. وهذا يجعل SFR-Judge حلاً موثوقًا للتقييم الآلي، مما يقلل الاعتماد على التعليقات التوضيحية اليدوية ويوفر خيارًا أكثر قابلية للتطوير لتقييم النموذج.
المدخل الورقي: https://arxiv.org/abs/2409.14664
تسليط الضوء على:
دقة عالية: حقق SFR-Judge أفضل 10 نتائج في 13 اختبارًا معياريًا، خاصة تحقيق دقة عالية تبلغ 92.7% على RewardBench.
تخفيف التحيز: يُظهر هذا النموذج انحيازًا أقل من النماذج الأخرى التي تم تقييمها، خاصة من حيث انحياز الطول والموضع.
تطبيق متعدد الوظائف: يدعم SFR-Judge المقارنات المزدوجة والتسجيل الفردي والتقييم من فئتين، ويمكن تكييفه مع مجموعة متنوعة من سيناريوهات التقييم.
إن ظهور SFR-Judge يجلب أملًا جديدًا لتقييم نماذج اللغات الكبيرة، حيث إن دقته العالية وانحيازه المنخفض وتعدد استخداماته تجعله أداة تقييم آلية قوية. يوفر هذا البحث دعمًا فنيًا مهمًا لتطوير مجال LLM ويشير أيضًا إلى أن تقييم LLM سيكون أكثر كفاءة وموثوقية في المستقبل. يتطلع محرر Downcodes إلى المزيد من الابتكارات المماثلة في المستقبل!