L'évaluation de grands modèles de langage (LLM) a toujours été un défi clé dans le domaine du traitement du langage naturel. Les méthodes d'évaluation manuelles traditionnelles prennent du temps et demandent beaucoup de travail, et ne peuvent pas faire face au développement rapide du LLM. À cette fin, l'équipe de recherche Salesforce AI a développé SFR-Judge, une famille d'évaluation composée de trois LLM de tailles différentes, conçue pour fournir des solutions d'évaluation automatisées plus rapides et plus efficaces. L'éditeur de Downcodes vous donnera une compréhension approfondie des innovations de SFR-Judge et de la manière dont il résout les problèmes d'évaluation LLM.
Dans le domaine du traitement du langage naturel, les grands modèles de langage (LLM) se sont développés rapidement et ont fait des progrès significatifs dans de nombreux domaines. Cependant, à mesure que la complexité des modèles augmente, il devient essentiel d’évaluer avec précision leurs résultats. Traditionnellement, nous nous appuyons sur les humains pour l’évaluation, mais cette approche prend du temps et est difficile à mettre à l’échelle pour suivre le rythme rapide du développement des modèles.
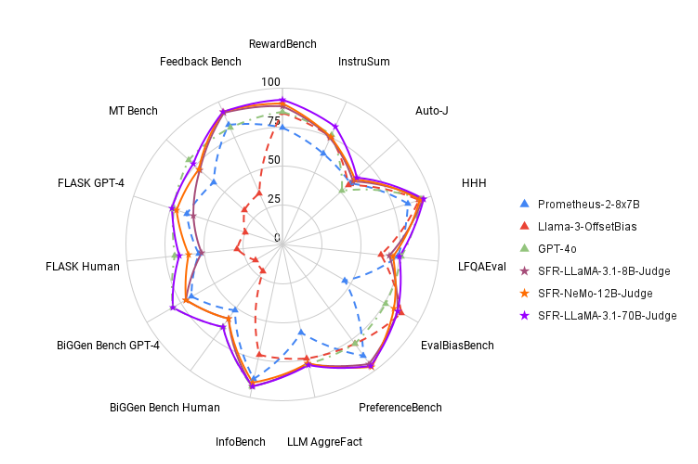
Pour changer cette situation, l'équipe de recherche Salesforce AI a lancé SFR-Judge, une famille d'évaluation composée de trois grands modèles de langage. Ces modèles comportent respectivement 8 milliards, 12 milliards et 70 milliards de paramètres et sont construits sur Meta Llama3 et Mistral NeMO. SFR-Judge est capable d'effectuer diverses tâches d'évaluation, notamment des comparaisons par paires, des évaluations de notation unique et de classification binaire, et est conçu pour aider les équipes de recherche à évaluer rapidement et efficacement les performances de nouveaux modèles.
Les modèles d'évaluation LLM traditionnels présentent souvent des problèmes de biais, tels que le biais de position et le biais de longueur, qui affecteront leur jugement. Afin de surmonter ces problèmes, SFR-Judge adopte la méthode de formation Direct Preference Optimization (DPO), qui permet au modèle d'apprendre à partir d'exemples positifs et négatifs, améliorant ainsi sa capacité à comprendre la tâche d'évaluation, réduisant les biais et assurant la cohérence. de jugement.
Lors des tests, SFR-Judge a obtenu de bons résultats sur 13 benchmarks, surpassant de nombreux modèles d'évaluation existants, y compris certains modèles privés. Notamment dans le classement RewardBench, la précision de SFR-Judge atteint 92,7%. C'est la première et la deuxième fois qu'un modèle d'évaluation générative dépasse le seuil de 90%, démontrant ainsi ses excellentes performances dans les modèles d'évaluation.
La méthode de formation de SFR-Judge couvre trois formats de données différents. La première est la « critique de la chaîne de pensée », qui aide le modèle à générer une analyse structurée de la réponse à l'évaluation. La seconde est « l'évaluation standard », qui simplifie le processus d'évaluation et fournit un retour d'information direct sur la conformité de la réponse aux normes. Enfin, la « dérivation des réponses » aide le modèle à comprendre les caractéristiques des réponses de haute qualité et à renforcer ses capacités de jugement. La combinaison de ces trois formats de données améliore grandement les capacités d'évaluation de SFR-Judge.
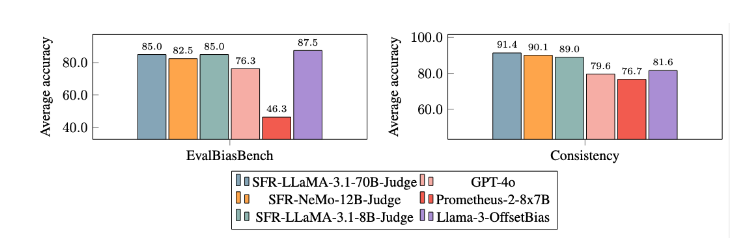
Après des expériences approfondies, le modèle SFR-Judge a obtenu des résultats nettement meilleurs que les autres modèles en termes de réduction des biais. Dans le benchmark EvalBiasBench, ils ont démontré un degré élevé de cohérence de l'ordre par paire, ce qui montre que les jugements du modèle restent stables même si l'ordre de réponse change. Cela fait de SFR-Judge une solution d’évaluation automatisée fiable, réduisant le recours aux annotations manuelles et offrant une option plus évolutive pour l’évaluation des modèles.
Entrée papier : https://arxiv.org/abs/2409.14664
Souligner:
? Haute précision : SFR-Judge a obtenu les 10 meilleurs résultats lors de 13 tests de référence, atteignant notamment une haute précision de 92,7% sur RewardBench.
Atténuation des biais : ce modèle présente un biais plus faible que les autres modèles évalués, notamment en termes de biais de longueur et de position.
Application multifonctionnelle : SFR-Judge prend en charge les comparaisons par paires, la notation unique et l'évaluation à deux catégories, et peut être adapté à une variété de scénarios d'évaluation.
L'émergence de SFR-Judge apporte un nouvel espoir à l'évaluation de grands modèles de langage. Sa grande précision, son faible biais et sa polyvalence en font un puissant outil d'évaluation automatisée. Cette recherche fournit un soutien technique important pour le développement du domaine LLM et indique également que l'évaluation LLM sera plus efficace et fiable à l'avenir. L’éditeur de Downcodes attend avec impatience d’autres innovations similaires à l’avenir !