Evaluasi model bahasa besar (LLM) selalu menjadi tantangan utama dalam bidang pemrosesan bahasa alami. Metode evaluasi manual tradisional memakan waktu dan tenaga, serta tidak dapat mengatasi pesatnya perkembangan LLM. Untuk mencapai tujuan ini, tim peneliti Salesforce AI mengembangkan SFR-Judge, rangkaian penilaian yang terdiri dari tiga LLM dengan ukuran berbeda, yang dirancang untuk memberikan solusi penilaian otomatis yang lebih cepat dan efisien. Editor Downcodes akan memberi Anda pemahaman mendalam tentang inovasi SFR-Judge dan bagaimana inovasi tersebut memecahkan masalah dalam penilaian LLM.
Di bidang pemrosesan bahasa alami, model bahasa besar (LLM) telah berkembang pesat dan mencapai kemajuan signifikan di banyak bidang. Namun, seiring bertambahnya kompleksitas model, evaluasi keluarannya secara akurat menjadi penting. Secara tradisional, kami mengandalkan manusia untuk melakukan evaluasi, namun pendekatan ini memakan waktu dan sulit untuk disesuaikan dengan pesatnya perkembangan model.
Untuk mengubah situasi ini, tim peneliti Salesforce AI meluncurkan SFR-Judge, sebuah rangkaian evaluasi yang terdiri dari tiga model bahasa besar. Model ini masing-masing memiliki 8 miliar, 12 miliar, dan 70 miliar parameter dan dibangun di atas Meta Llama3 dan Mistral NeMO. SFR-Judge mampu melakukan berbagai tugas evaluasi, termasuk perbandingan berpasangan, penilaian tunggal, dan evaluasi klasifikasi biner, dan dirancang untuk membantu tim peneliti mengevaluasi kinerja model baru dengan cepat dan efisien.
Model evaluasi LLM tradisional sering kali memiliki beberapa masalah bias, seperti bias posisi dan bias panjang, yang akan mempengaruhi penilaiannya. Untuk mengatasi masalah ini, SFR-Judge mengadopsi metode pelatihan Direct Preference Optimization (DPO), yang memungkinkan model belajar dari contoh positif dan negatif, sehingga meningkatkan kemampuannya untuk memahami tugas evaluasi, mengurangi bias, dan memastikan konsistensi. penghakiman.
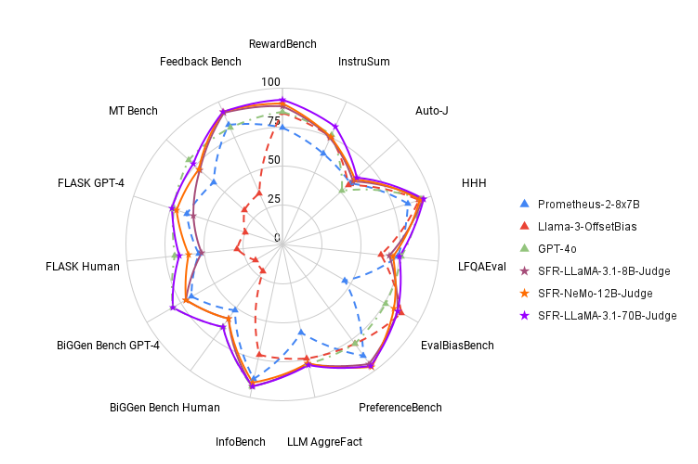
Dalam pengujian, SFR-Judge berkinerja baik pada 13 tolok ukur, mengungguli banyak model evaluasi yang ada, termasuk beberapa model swasta. Khususnya pada pemeringkatan RewardBench, akurasi SFR-Judge mencapai 92,7%. Ini adalah pertama dan kedua kalinya model evaluasi generatif melampaui ambang batas 90%, yang menunjukkan kinerjanya yang sangat baik dalam model evaluasi.
Metode pelatihan SFR-Judge mencakup tiga format data yang berbeda. Yang pertama adalah "kritik rantai pemikiran", yang membantu model menghasilkan analisis terstruktur mengenai respons penilaian. Yang kedua adalah “evaluasi standar”, yang menyederhanakan proses evaluasi dan memberikan umpan balik langsung mengenai apakah respons yang diberikan memenuhi standar. Terakhir, “turunan respons” membantu model memahami karakteristik respons berkualitas tinggi dan memperkuat kemampuan penilaiannya. Kombinasi ketiga format data ini sangat meningkatkan kemampuan evaluasi SFR-Judge.
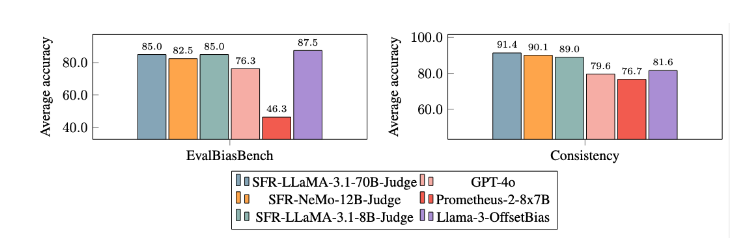
Setelah percobaan ekstensif, model SFR-Judge memiliki kinerja yang jauh lebih baik dibandingkan model lainnya dalam mengurangi bias. Dalam benchmark EvalBiasBench, mereka menunjukkan tingkat konsistensi urutan berpasangan yang tinggi, yang menunjukkan bahwa penilaian model tetap stabil meskipun urutan respons berubah. Hal ini menjadikan SFR-Judge sebagai solusi evaluasi otomatis yang andal, mengurangi ketergantungan pada anotasi manual, dan memberikan opsi yang lebih skalabel untuk evaluasi model.
Pintu masuk makalah: https://arxiv.org/abs/2409.14664
Menyorot:
? Akurasi tinggi: SFR-Judge mencapai 10 hasil terbaik dalam 13 tes benchmark, terutama mencapai akurasi tinggi sebesar 92,7% di RewardBench.
Mitigasi Bias: Model ini menunjukkan bias yang lebih rendah dibandingkan model lain yang dievaluasi, terutama dalam hal bias panjang dan posisi.
Aplikasi multifungsi: SFR-Judge mendukung perbandingan berpasangan, penilaian tunggal dan penilaian dua kategori, dan dapat disesuaikan dengan berbagai skenario penilaian.
Kemunculan SFR-Judge membawa harapan baru pada evaluasi model bahasa berukuran besar. Akurasinya yang tinggi, bias yang rendah, dan fleksibilitasnya menjadikannya alat evaluasi otomatis yang hebat. Penelitian ini memberikan dukungan teknis yang penting untuk pengembangan bidang LLM dan juga menunjukkan bahwa penilaian LLM akan lebih efisien dan dapat diandalkan di masa depan. Editor Downcodes menantikan lebih banyak inovasi serupa di masa depan!