Die Evaluierung großer Sprachmodelle (LLMs) war schon immer eine zentrale Herausforderung im Bereich der Verarbeitung natürlicher Sprache. Herkömmliche manuelle Bewertungsmethoden sind zeit- und arbeitsintensiv und können der schnellen Entwicklung von LLM nicht gerecht werden. Zu diesem Zweck entwickelte das AI-Forschungsteam von Salesforce SFR-Judge, eine Bewertungsfamilie bestehend aus drei LLMs unterschiedlicher Größe, die schnellere und effizientere automatisierte Bewertungslösungen bieten soll. Der Herausgeber von Downcodes vermittelt Ihnen ein detailliertes Verständnis der Innovationen von SFR-Judge und wie es die Probleme bei der LLM-Bewertung löst.
Im Bereich der Verarbeitung natürlicher Sprache haben sich große Sprachmodelle (LLMs) rasant entwickelt und in vielen Bereichen erhebliche Fortschritte gemacht. Mit zunehmender Komplexität der Modelle wird es jedoch immer wichtiger, ihre Ergebnisse genau zu bewerten. Traditionell haben wir uns bei der Bewertung auf Menschen verlassen, aber dieser Ansatz ist zeitaufwändig und schwierig zu skalieren, um mit dem schnellen Tempo der Modellentwicklung Schritt zu halten.
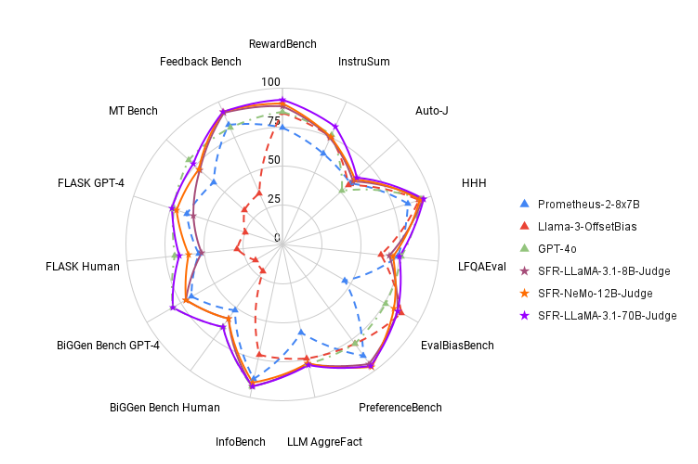
Um diese Situation zu ändern, hat das Salesforce AI-Forschungsteam SFR-Judge ins Leben gerufen, eine Bewertungsfamilie, die aus drei großen Sprachmodellen besteht. Diese Modelle verfügen über 8 Milliarden, 12 Milliarden bzw. 70 Milliarden Parameter und basieren auf Meta Llama3 und Mistral NeMO. SFR-Judge ist in der Lage, eine Vielzahl von Bewertungsaufgaben durchzuführen, darunter paarweise Vergleiche, Einzelbewertungen und binäre Klassifizierungsbewertungen, und soll Forschungsteams dabei helfen, die Leistung neuer Modelle schnell und effizient zu bewerten.
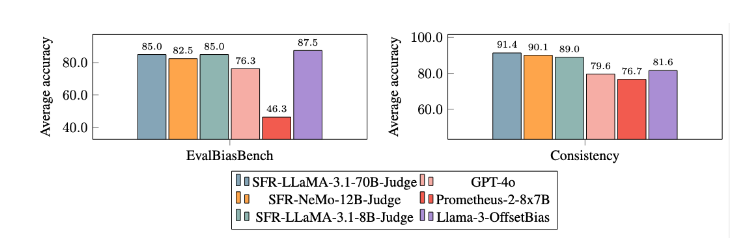
Herkömmliche LLM-Bewertungsmodelle weisen häufig einige Bias-Probleme auf, z. B. Positions-Bias und Längen-Bias, die sich auf ihre Beurteilung auswirken. Um diese Probleme zu überwinden, wendet SFR-Judge die DPO-Trainingsmethode (Direct Preference Optimization) an, die es dem Modell ermöglicht, aus positiven und negativen Beispielen zu lernen und dadurch seine Fähigkeit zum Verständnis der Bewertungsaufgabe zu verbessern, Verzerrungen zu reduzieren und die Konsistenz sicherzustellen des Urteils.
Beim Testen schnitt SFR-Judge bei 13 Benchmarks gut ab und übertraf viele bestehende Bewertungsmodelle, darunter auch einige private Modelle. Insbesondere in der RewardBench-Rangliste erreichte die Genauigkeit von SFR-Judge 92,7 %. Dies ist das erste und zweite Mal, dass ein generatives Bewertungsmodell die 90 %-Schwelle überschreitet, was seine hervorragende Leistung in Bewertungsmodellen unter Beweis stellt.
Die Trainingsmethode von SFR-Judge deckt drei verschiedene Datenformate ab. Die erste ist die „Gedankenkettenkritik“, die dem Modell hilft, eine strukturierte Analyse der Bewertungsantwort zu erstellen. Die zweite ist die „Standardbewertung“, die den Bewertungsprozess vereinfacht und eine direkte Rückmeldung darüber gibt, ob die Antwort den Standards entspricht. Schließlich hilft die „Antwortableitung“ dem Modell, die Merkmale qualitativ hochwertiger Antworten zu verstehen und seine Urteilsfähigkeit zu stärken. Die Kombination dieser drei Datenformate verbessert die Auswertungsmöglichkeiten von SFR-Judge erheblich.
Nach umfangreichen Experimenten schnitt das SFR-Judge-Modell bei der Reduzierung von Verzerrungen deutlich besser ab als andere Modelle. Im EvalBiasBench-Benchmark zeigten sie ein hohes Maß an paarweiser Reihenfolgenkonsistenz, was zeigt, dass die Urteile des Modells auch dann stabil bleiben, wenn sich die Antwortreihenfolge ändert. Dies macht SFR-Judge zu einer zuverlässigen automatisierten Bewertungslösung, die die Abhängigkeit von manuellen Anmerkungen verringert und eine skalierbarere Option für die Modellbewertung bietet.
Papiereingang: https://arxiv.org/abs/2409.14664
Highlight:
?Hohe Genauigkeit: SFR-Judge erzielte in 13 Benchmark-Tests die 10 besten Ergebnisse, insbesondere eine hohe Genauigkeit von 92,7 % bei RewardBench.
Verzerrungsminderung: Dieses Modell weist eine geringere Verzerrung auf als andere bewertete Modelle, insbesondere in Bezug auf Längen- und Positionsverzerrung.
Multifunktionale Anwendung: SFR-Judge unterstützt Paarvergleiche, Einzelbewertung und Zwei-Kategorien-Bewertung und kann an eine Vielzahl von Bewertungsszenarien angepasst werden.
Das Aufkommen von SFR-Judge bringt neue Hoffnung für die Bewertung großer Sprachmodelle. Seine hohe Genauigkeit, geringe Verzerrung und Vielseitigkeit machen es zu einem leistungsstarken automatisierten Bewertungstool. Diese Forschung liefert wichtige technische Unterstützung für die Entwicklung des LLM-Bereichs und zeigt auch, dass die LLM-Bewertung in Zukunft effizienter und zuverlässiger sein wird. Der Herausgeber von Downcodes freut sich auf weitere ähnliche Innovationen in der Zukunft!