LLM(대형 언어 모델)의 평가는 자연어 처리 분야에서 항상 중요한 과제였습니다. 기존의 수동 평가 방법은 시간이 많이 걸리고 노동 집약적이며 LLM의 급속한 발전에 대처할 수 없습니다. 이를 위해 Salesforce AI 연구팀은 더 빠르고 효율적인 자동 평가 솔루션을 제공하도록 설계된 다양한 크기의 3개 LLM으로 구성된 평가 제품군인 SFR-Judge를 개발했습니다. Downcodes의 편집자는 SFR-Judge의 혁신과 이것이 LLM 평가의 문제를 해결하는 방법에 대한 심층적인 이해를 제공합니다.
자연어 처리 분야에서는 LLM(대형 언어 모델)이 급속도로 발전했으며 많은 분야에서 상당한 발전을 이루었습니다. 그러나 모델이 복잡해짐에 따라 결과를 정확하게 평가하는 것이 중요해졌습니다. 전통적으로 우리는 평가를 인간에게 의존해 왔지만 이 접근 방식은 시간이 많이 걸리고 빠른 모델 개발 속도를 따라잡기 위해 확장하기가 어렵습니다.
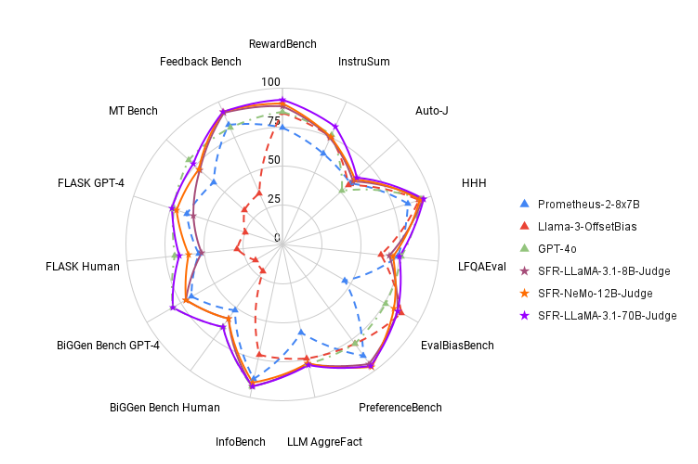
이러한 상황을 바꾸기 위해 Salesforce AI 연구팀은 세 가지 대규모 언어 모델로 구성된 평가 제품군인 SFR-Judge를 출시했습니다. 이 모델에는 각각 80억, 120억, 700억 개의 매개변수가 있으며 Meta Llama3 및 Mistral NeMO를 기반으로 구축되었습니다. SFR-Judge는 쌍별 비교, 단일 채점, 이진 분류 평가 등 다양한 평가 작업을 수행할 수 있으며, 연구팀이 새로운 모델의 성능을 빠르고 효율적으로 평가할 수 있도록 설계되었습니다.
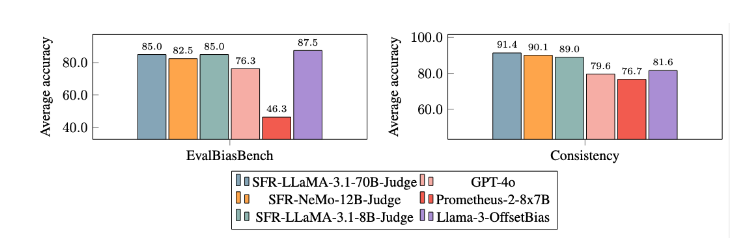
전통적인 LLM 평가 모델에는 위치 편향, 길이 편향과 같은 편향 문제가 있어 판단에 영향을 미치는 경우가 많습니다. 이러한 문제를 극복하기 위해 SFR-Judge는 모델이 긍정적인 사례와 부정적인 사례로부터 학습할 수 있도록 하는 DPO(Direct Preference Optimization) 교육 방법을 채택하여 평가 작업에 대한 이해력을 향상시키고 편향을 줄이고 일관성을 보장합니다. 판단의.
테스트에서 SFR-Judge는 13개 벤치마크에서 좋은 성능을 발휘하여 일부 개인 모델을 포함한 많은 기존 평가 모델을 능가했습니다. 특히 RewardBench 순위에서는 SFR-Judge의 정확도가 92.7%에 달해 생성 평가 모델이 처음과 두 번째로 90% 임계값을 초과하며 평가 모델에서 뛰어난 성능을 입증했습니다.
SFR-Judge의 훈련 방법은 세 가지 다른 데이터 형식을 다룹니다. 첫 번째는 모델이 평가 응답에 대한 구조화된 분석을 생성하는 데 도움이 되는 "사고 사슬 비판"입니다. 두 번째는 '표준 평가'로, 평가 과정을 단순화하고 응답이 기준을 충족하는지에 대한 직접적인 피드백을 제공합니다. 마지막으로 '응답 도출'은 모델이 고품질 응답의 특성을 이해하고 판단 능력을 강화하는 데 도움이 됩니다. 이 세 가지 데이터 형식의 조합은 SFR-Judge의 평가 기능을 크게 향상시킵니다.
광범위한 실험 후에 SFR-Judge 모델은 편향을 줄이는 데 있어 다른 모델보다 훨씬 더 나은 성능을 보였습니다. EvalBiasBench 벤치마크에서는 높은 수준의 쌍별 순서 일관성을 보여 주었는데, 이는 응답 순서가 변경되더라도 모델의 판단이 안정적으로 유지된다는 것을 보여줍니다. 이를 통해 SFR-Judge는 신뢰할 수 있는 자동 평가 솔루션이 되어 수동 주석에 대한 의존도를 줄이고 모델 평가를 위한 보다 확장 가능한 옵션을 제공합니다.
논문 입구: https://arxiv.org/abs/2409.14664
가장 밝은 부분:
? 높은 정확도: SFR-Judge는 13개의 벤치마크 테스트에서 10개의 최고 결과를 달성했으며, 특히 RewardBench에서 92.7%의 높은 정확도를 달성했습니다.
바이어스 완화: 이 모델은 특히 길이 및 위치 바이어스 측면에서 평가된 다른 모델보다 낮은 바이어스를 보여줍니다.
다기능 애플리케이션: SFR-Judge는 쌍 비교, 단일 채점 및 2개 범주 평가를 지원하며 다양한 평가 시나리오에 적용할 수 있습니다.
SFR-Judge의 출현은 높은 정확성, 낮은 편향 및 다양성으로 인해 대규모 언어 모델 평가에 새로운 희망을 가져왔습니다. 이 연구는 LLM 분야의 발전을 위한 중요한 기술 지원을 제공하며 LLM 평가가 향후 더욱 효율적이고 신뢰할 수 있음을 나타냅니다. Downcodes의 편집자는 앞으로도 더욱 유사한 혁신을 기대합니다!