Оценка больших языковых моделей (LLM) всегда была ключевой проблемой в области обработки естественного языка. Традиционные методы ручной оценки отнимают много времени и труда и не могут справиться с быстрым развитием LLM. С этой целью исследовательская группа Salesforce по искусственному интеллекту разработала SFR-Judge, семейство оценок, состоящее из трех LLM разных размеров, предназначенное для предоставления более быстрых и эффективных решений для автоматизированной оценки. Редактор Downcodes даст вам более глубокое понимание инноваций SFR-Judge и того, как он решает проблемы оценки LLM.
В области обработки естественного языка быстро развиваются большие языковые модели (LLM), которые добились значительного прогресса во многих областях. Однако по мере усложнения моделей становится критически важным точно оценить их результаты. Традиционно мы полагались на людей для оценки, но этот подход требует много времени и его трудно масштабировать, чтобы идти в ногу с быстрыми темпами разработки моделей.
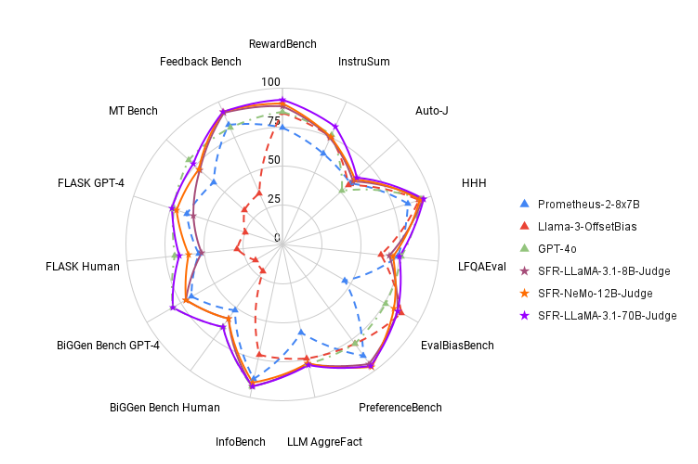
Чтобы изменить эту ситуацию, исследовательская группа Salesforce по искусственному интеллекту запустила SFR-Judge, семейство оценок, состоящее из трех крупных языковых моделей. Эти модели имеют 8 миллиардов, 12 миллиардов и 70 миллиардов параметров соответственно и построены на Meta Llama3 и Mistral NeMO. SFR-Judge способен выполнять различные задачи оценки, включая парные сравнения, одинарную оценку и оценку двоичной классификации, и предназначен для того, чтобы помочь исследовательским группам быстро и эффективно оценить производительность новых моделей.
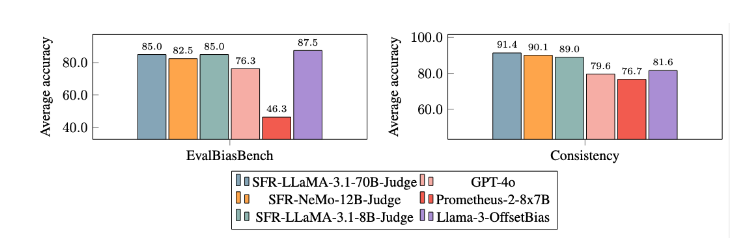
Традиционные модели оценки LLM часто имеют некоторые проблемы с предвзятостью, такие как смещение позиции и смещение длины, которые влияют на их суждения. Чтобы преодолеть эти проблемы, SFR-Judge применяет метод обучения прямой оптимизации предпочтений (DPO), который позволяет модели учиться на положительных и отрицательных примерах, тем самым улучшая ее способность понимать задачу оценки, уменьшая предвзятость и обеспечивая последовательность. суда.
При тестировании SFR-Judge показал хорошие результаты по 13 тестам, превзойдя многие существующие модели оценки, включая некоторые частные модели. В частности, в рейтинге RewardBench точность SFR-Judge достигла 92,7%. Это первый и второй раз, когда модель генеративной оценки превысила порог в 90%, продемонстрировав свою отличную производительность в моделях оценки.
Метод обучения SFR-Judge охватывает три различных формата данных. Первый — это «критика мыслительной цепочки», которая помогает модели провести структурированный анализ оценочной реакции. Второй вариант — «стандартная оценка», которая упрощает процесс оценки и обеспечивает прямую обратную связь о том, соответствует ли ответ стандартам. Наконец, «вывод ответов» помогает модели понять характеристики высококачественных ответов и усилить ее способность принимать решения. Комбинация этих трех форматов данных значительно улучшает возможности оценки SFR-Judge.
После обширных экспериментов модель SFR-Judge показала себя значительно лучше, чем другие модели, в снижении систематической ошибки. В тесте EvalBiasBench они продемонстрировали высокую степень согласованности попарного порядка, что показывает, что суждения модели остаются стабильными, даже если порядок ответов меняется. Это делает SFR-Judge надежным решением для автоматизированной оценки, уменьшающим зависимость от ручного аннотирования и предоставляющим более масштабируемый вариант для оценки модели.
Бумажный вход: https://arxiv.org/abs/2409.14664.
Выделять:
? Высокая точность: SFR-Judge показал 10 лучших результатов в 13 тестах производительности, особенно достигнув высокой точности 92,7% на RewardBench.
Смягчение смещения: эта модель демонстрирует меньшую предвзятость, чем другие оцениваемые модели, особенно с точки зрения смещения длины и положения.
Многофункциональное приложение: SFR-Judge поддерживает парные сравнения, одинарную оценку и оценку по двум категориям и может быть адаптирован к различным сценариям оценки.
Появление SFR-Judge дает новую надежду на оценку больших языковых моделей. Его высокая точность, низкая предвзятость и универсальность делают его мощным автоматизированным инструментом оценки. Это исследование обеспечивает важную техническую поддержку для развития области LLM, а также указывает на то, что оценка LLM будет более эффективной и надежной в будущем. Редактор Downcodes надеется на новые подобные нововведения в будущем!