The evaluation of large language models (LLMs) has always been a key challenge in the field of natural language processing. Traditional manual evaluation methods are time-consuming and labor-intensive, and cannot cope with the rapid development of LLM. To this end, the Salesforce AI research team developed SFR-Judge, an assessment family consisting of three LLMs of different sizes, designed to provide faster and more efficient automated assessment solutions. The editor of Downcodes will give you an in-depth understanding of the innovations of SFR-Judge and how it solves the problems in LLM assessment.
In the field of natural language processing, large language models (LLMs) have developed rapidly and have made significant progress in many fields. However, as models increase in complexity, it becomes critical to accurately evaluate their output. Traditionally, we have relied on humans for evaluation, but this approach is time-consuming and difficult to scale to keep up with the rapid pace of model development.
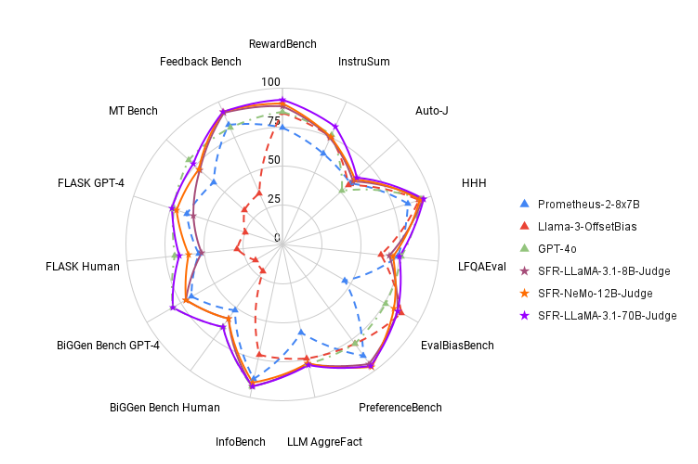
To change this situation, the Salesforce AI research team launched SFR-Judge, an evaluation family composed of three large language models. These models have 8 billion, 12 billion and 70 billion parameters respectively and are built on Meta Llama3 and Mistral NeMO. SFR-Judge is capable of performing a variety of evaluation tasks, including pairwise comparisons, single scoring, and binary classification evaluations, and is designed to help research teams quickly and efficiently evaluate the performance of new models.
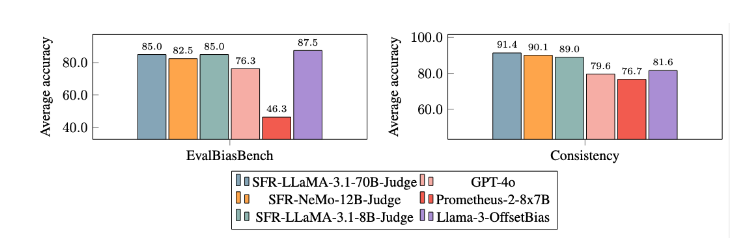
Traditional LLM evaluation models often have some bias problems, such as position bias and length bias, which will affect their judgment. In order to overcome these problems, SFR-Judge adopts the Direct Preference Optimization (DPO) training method, which allows the model to learn from positive and negative examples, thereby improving its ability to understand the evaluation task, reducing bias, and ensuring the consistency of judgment.
In testing, SFR-Judge performed well on 13 benchmarks, outperforming many existing evaluation models, including some private models. Especially on the RewardBench rankings, SFR-Judge's accuracy reached 92.7%. This is the first and second time that a generative evaluation model has exceeded the 90% threshold, demonstrating its excellent performance in evaluation models.
SFR-Judge’s training method covers three different data formats. The first is "thought chain criticism", which helps the model generate a structured analysis of the assessment response. The second is "standard evaluation", which simplifies the evaluation process and provides direct feedback on whether the response meets the standards. Finally, “response derivation” helps the model understand the characteristics of high-quality responses and strengthen its judgment capabilities. The combination of these three data formats greatly improves SFR-Judge's evaluation capabilities.
After extensive experiments, the SFR-Judge model performed significantly better than other models in reducing bias. In the EvalBiasBench benchmark, they demonstrated a high degree of pairwise order consistency, which shows that the model's judgments remain stable even if the response order changes. This makes SFR-Judge a reliable automated evaluation solution, reducing reliance on manual annotation and providing a more scalable option for model evaluation.
Paper entrance: https://arxiv.org/abs/2409.14664
Highlight:
? High accuracy: SFR-Judge achieved 10 best results in 13 benchmark tests, especially achieving a high accuracy of 92.7% on RewardBench.
Bias Mitigation: This model shows lower bias than other evaluated models, especially in terms of length and position bias.
Multifunctional application: SFR-Judge supports paired comparisons, single scoring and two-category assessment, and can be adapted to a variety of assessment scenarios.
The emergence of SFR-Judge brings new hope to the evaluation of large language models. Its high accuracy, low bias and versatility make it a powerful automated evaluation tool. This research provides important technical support for the development of the LLM field and also indicates that LLM assessment will be more efficient and reliable in the future. The editor of Downcodes looks forward to more similar innovations in the future!