La evaluación de grandes modelos de lenguaje (LLM) siempre ha sido un desafío clave en el campo del procesamiento del lenguaje natural. Los métodos tradicionales de evaluación manual requieren mucho tiempo y trabajo y no pueden hacer frente al rápido desarrollo de LLM. Con este fin, el equipo de investigación de IA de Salesforce desarrolló SFR-Judge, una familia de evaluación que consta de tres LLM de diferentes tamaños, diseñada para proporcionar soluciones de evaluación automatizadas más rápidas y eficientes. El editor de Downcodes le brindará una comprensión profunda de las innovaciones de SFR-Judge y cómo resuelve los problemas en la evaluación de LLM.
En el campo del procesamiento del lenguaje natural, los grandes modelos de lenguaje (LLM) se han desarrollado rápidamente y han logrado avances significativos en muchos campos. Sin embargo, a medida que los modelos aumentan en complejidad, se vuelve fundamental evaluar con precisión su resultado. Tradicionalmente, hemos dependido de humanos para la evaluación, pero este enfoque requiere mucho tiempo y es difícil de ampliar para seguir el rápido ritmo del desarrollo de modelos.
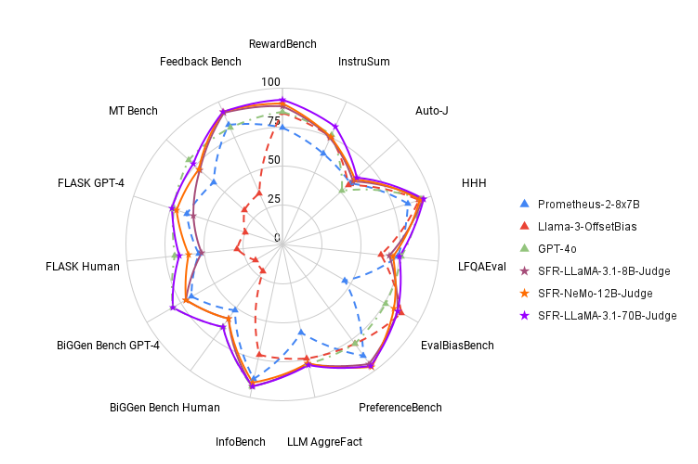
Para cambiar esta situación, el equipo de investigación de IA de Salesforce lanzó SFR-Judge, una familia de evaluación compuesta por tres grandes modelos de lenguaje. Estos modelos tienen 8 mil millones, 12 mil millones y 70 mil millones de parámetros respectivamente y están construidos sobre Meta Llama3 y Mistral NeMO. SFR-Judge es capaz de realizar una variedad de tareas de evaluación, incluidas comparaciones por pares, puntuación única y evaluaciones de clasificación binaria, y está diseñado para ayudar a los equipos de investigación a evaluar de forma rápida y eficiente el rendimiento de nuevos modelos.
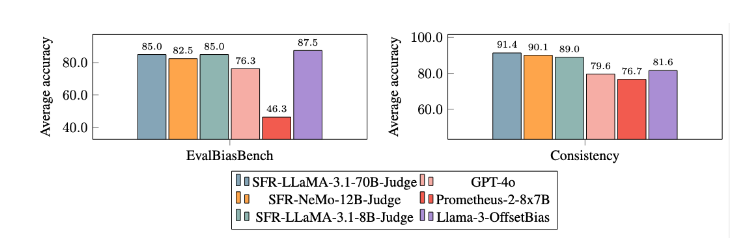
Los modelos de evaluación tradicionales de LLM a menudo tienen algunos problemas de sesgo, como el sesgo de posición y el sesgo de duración, que afectarán su juicio. Para superar estos problemas, SFR-Judge adopta el método de entrenamiento de Optimización de Preferencia Directa (DPO), que permite al modelo aprender de ejemplos positivos y negativos, mejorando así su capacidad para comprender la tarea de evaluación, reduciendo el sesgo y garantizando la coherencia. de juicio.
En las pruebas, SFR-Judge obtuvo buenos resultados en 13 puntos de referencia, superando a muchos modelos de evaluación existentes, incluidos algunos modelos privados. Especialmente en las clasificaciones de RewardBench, la precisión de SFR-Judge alcanzó el 92,7%. Esta es la primera y segunda vez que un modelo de evaluación generativa supera el umbral del 90%, lo que demuestra su excelente desempeño en los modelos de evaluación.
El método de formación de SFR-Judge cubre tres formatos de datos diferentes. La primera es la "crítica de la cadena de pensamiento", que ayuda al modelo a generar un análisis estructurado de la respuesta de la evaluación. La segunda es la "evaluación estándar", que simplifica el proceso de evaluación y proporciona retroalimentación directa sobre si la respuesta cumple con los estándares. Finalmente, la "derivación de respuestas" ayuda al modelo a comprender las características de las respuestas de alta calidad y fortalecer sus capacidades de juicio. La combinación de estos tres formatos de datos mejora enormemente las capacidades de evaluación de SFR-Judge.
Después de extensos experimentos, el modelo SFR-Judge funcionó significativamente mejor que otros modelos para reducir el sesgo. En el punto de referencia EvalBiasBench, demostraron un alto grado de coherencia del orden por pares, lo que muestra que los juicios del modelo permanecen estables incluso si cambia el orden de respuesta. Esto convierte a SFR-Judge en una solución de evaluación automatizada confiable, que reduce la dependencia de la anotación manual y brinda una opción más escalable para la evaluación de modelos.
Entrada del artículo: https://arxiv.org/abs/2409.14664
Destacar:
? Alta precisión: SFR-Judge logró los 10 mejores resultados en 13 pruebas comparativas, logrando especialmente una alta precisión del 92,7% en RewardBench.
Mitigación de sesgo: este modelo muestra un sesgo menor que otros modelos evaluados, especialmente en términos de sesgo de longitud y posición.
Aplicación multifuncional: SFR-Judge admite comparaciones por pares, puntuación única y evaluación de dos categorías, y puede adaptarse a una variedad de escenarios de evaluación.
La aparición de SFR-Judge trae nuevas esperanzas a la evaluación de modelos de lenguaje grandes. Su alta precisión, bajo sesgo y versatilidad lo convierten en una poderosa herramienta de evaluación automatizada. Esta investigación proporciona un importante apoyo técnico para el desarrollo del campo LLM y también indica que la evaluación LLM será más eficiente y confiable en el futuro. ¡El editor de Downcodes espera más innovaciones similares en el futuro!