A avaliação de grandes modelos de linguagem (LLMs) sempre foi um desafio fundamental no campo do processamento de linguagem natural. Os métodos tradicionais de avaliação manual são demorados e trabalhosos e não conseguem lidar com o rápido desenvolvimento do LLM. Para isso, a equipe de pesquisa da Salesforce AI desenvolveu o SFR-Judge, uma família de avaliação composta por três LLMs de tamanhos diferentes, projetada para fornecer soluções de avaliação automatizada mais rápidas e eficientes. O editor de Downcodes lhe dará uma compreensão aprofundada das inovações do SFR-Judge e como ele resolve os problemas na avaliação LLM.
No campo do processamento de linguagem natural, os grandes modelos de linguagem (LLMs) desenvolveram-se rapidamente e fizeram progressos significativos em muitos campos. No entanto, à medida que os modelos aumentam em complexidade, torna-se crítico avaliar com precisão os seus resultados. Tradicionalmente, contamos com humanos para avaliação, mas esta abordagem é demorada e difícil de escalar para acompanhar o ritmo rápido de desenvolvimento do modelo.
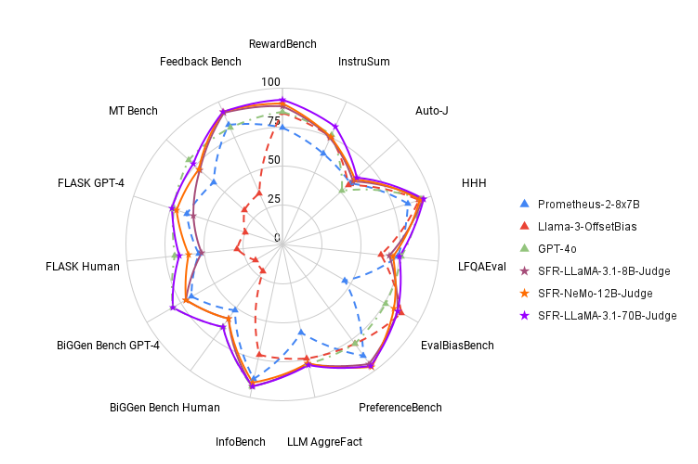
Para mudar esta situação, a equipe de pesquisa da Salesforce AI lançou o SFR-Judge, uma família de avaliação composta por três grandes modelos de linguagem. Esses modelos têm 8 bilhões, 12 bilhões e 70 bilhões de parâmetros respectivamente e são construídos em Meta Llama3 e Mistral NeMO. O SFR-Judge é capaz de realizar uma variedade de tarefas de avaliação, incluindo comparações pareadas, pontuação única e avaliações de classificação binária, e foi projetado para ajudar equipes de pesquisa a avaliar de forma rápida e eficiente o desempenho de novos modelos.
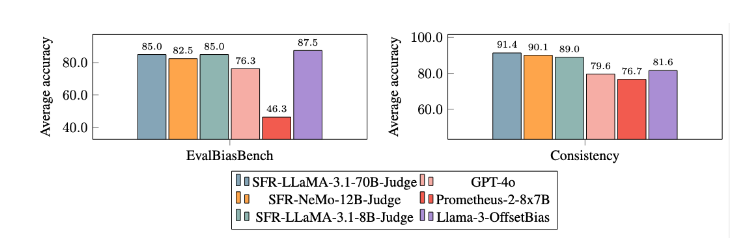
Os modelos tradicionais de avaliação LLM muitas vezes apresentam alguns problemas de viés, como viés de posição e viés de comprimento, que afetarão seu julgamento. Para superar esses problemas, o SFR-Judge adota o método de treinamento Direct Preference Optimization (DPO), que permite ao modelo aprender com exemplos positivos e negativos, melhorando assim sua capacidade de compreensão da tarefa de avaliação, reduzindo vieses e garantindo a consistência. de julgamento.
Nos testes, o SFR-Judge teve um bom desempenho em 13 benchmarks, superando muitos modelos de avaliação existentes, incluindo alguns modelos privados. Especialmente nas classificações do RewardBench, a precisão do SFR-Judge atingiu 92,7%. Esta é a primeira e segunda vez que um modelo de avaliação generativo excede o limite de 90%, demonstrando o seu excelente desempenho em modelos de avaliação.
O método de treinamento do SFR-Judge abrange três formatos de dados diferentes. A primeira é a “crítica da cadeia de pensamento”, que ajuda o modelo a gerar uma análise estruturada da resposta da avaliação. A segunda é a “avaliação padrão”, que simplifica o processo de avaliação e fornece feedback direto sobre se a resposta atende aos padrões. Finalmente, a “derivação de respostas” ajuda o modelo a compreender as características de respostas de alta qualidade e a fortalecer as suas capacidades de julgamento. A combinação destes três formatos de dados melhora muito as capacidades de avaliação do SFR-Judge.
Após extensos experimentos, o modelo SFR-Judge teve um desempenho significativamente melhor do que outros modelos na redução do viés. No benchmark EvalBiasBench, eles demonstraram um alto grau de consistência de ordem de pares, o que mostra que os julgamentos do modelo permanecem estáveis mesmo se a ordem de resposta mudar. Isso torna o SFR-Judge uma solução de avaliação automatizada confiável, reduzindo a dependência de anotações manuais e fornecendo uma opção mais escalável para avaliação de modelos.
Entrada de papel: https://arxiv.org/abs/2409.14664
Destaque:
? Alta precisão: o SFR-Judge obteve 10 melhores resultados em 13 testes de benchmark, alcançando especialmente uma alta precisão de 92,7% no RewardBench.
Mitigação de viés: Este modelo apresenta viés menor do que outros modelos avaliados, especialmente em termos de viés de comprimento e posição.
Aplicação multifuncional: o SFR-Judge suporta comparações pareadas, pontuação única e avaliação de duas categorias e pode ser adaptado a uma variedade de cenários de avaliação.
O surgimento do SFR-Judge traz uma nova esperança para a avaliação de grandes modelos linguísticos. Sua alta precisão, baixo viés e versatilidade fazem dele uma poderosa ferramenta de avaliação automatizada. Esta pesquisa fornece importante suporte técnico para o desenvolvimento da área de LLM e também indica que a avaliação de LLM será mais eficiente e confiável no futuro. O editor de Downcodes espera mais inovações semelhantes no futuro!