controlled argument generation
1.0.0
伴随论文方面控制的神经论证产生的存储库。
我们依靠日常生活中的论点来表达我们的观点并以证据为基础,从而使它们更具说服力。但是,寻找和制定论点可能具有挑战性。为了应对这一挑战,我们培训了一个语言模型(基于Keskar等人的CTRL(2019)),以生成参数生成,该语言模型可以以细粒度的水平进行控制,以生成针对给定主题,立场和方面的句子级别的论点。我们将参数方面的检测定义为一种必要的方法,以允许这种细粒状控制和众包数据集,其中包含5,032个带有方面的参数。我们发布了该数据集以及参数生成模型的培训数据,其权重以及该模型生成的参数。
下图显示了如何训练参数生成模型:
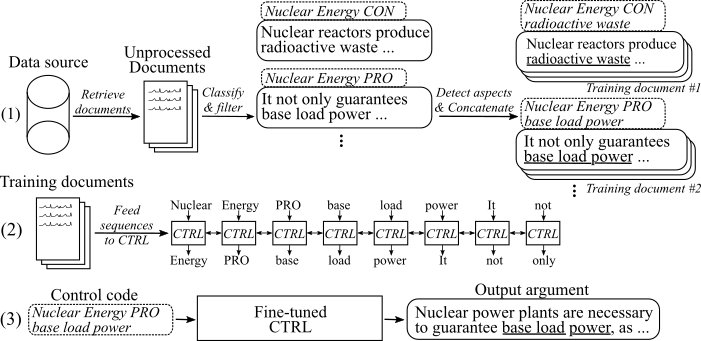
(1)我们收集了来自两个大数据源的八个不同主题的数百万个文档。所有句子都归类为亲,con和con-con和con-arguments。我们使用在新颖的数据集上训练的模型,并以相同的主题,立场和方面的培训来检测所有参数的各个方面。 (2)我们使用收集的分类数据来调节CTRL模型在所有收集的参数的主题,立场和方面。 (3)在推理中,传递控制代码[topip] [stance] [apcions]将生成一个遵循这些命令的参数。
15。2020年5月
我们已经为方面控制的神经参数生成模型添加了代码,并添加了有关如何使用它的描述。模型和代码修改了Keskar等人的作品。 (2019)。可以在“下载”部分中找到指向微调模型权重和培训数据的链接。
8. 2020年5月
参数方面检测数据集可以从此处下载( gonge_aspect_detection_v1.0.7z )。从那里,您还可以下载使用参数生成模型(生成的_arguments.7z )生成的参数和数据以重现参数生成模型的微调( reddit_training_data.7z , cc_training_data.7z )。
注意:由于许可原因,这些文件无法自由分发。单击任何文件都会将您重定向到表格,您必须在其中留下姓名和电子邮件。提交表格后,您将很快收到下载链接。
从这里下载数据集。您可以下载以下文件:
注意:由于许可原因,这些文件无法自由分发。单击任何文件都会将您重定向到表格,您必须在其中留下姓名和电子邮件。提交表格后,您将很快收到下载链接。
使用脚本/download_weights.sh下载模型权重。该脚本将在reddit-comments和common-crawl数据上进行微调的模型下载权重,并将其解压缩到主要项目文件夹中。
该代码用Python3.6测试。安装所有要求
pip install -r requirements.txt
并按照使用时的原始读数中的说明,步骤1和2 。
在下文中,我们描述了使用方面控制的神经论点生成模型的三种方法:
A.仅使用生成模型
B.使用可用的培训数据来复制/微调模型
C.使用您自己的数据微调一个新的方面控制神经论证生成模型
为了生成参数,请首先下载模型的权重(在脚本/download_weights.sh上下载脚本)。通过python generation.py --model_dir reddit_seqlen256_v1运行模型,用于在reddit-comments data或python generation.py --model_dir cc_seqlen256_v1上训练的型号,用于对型号进行了对Common-Crawl数据训练的模型。加载完成后,输入控制代码,例如nuclear energy CON waste ,以生成遵循此控制代码的参数。为了获得第一个生成的参数的更好结果,您可以用一个或结肠(“。”或“:”)结束控制代码。有关更多详细信息,请参阅论文。
注意:每个主题和数据源的允许的控制代码可以在triagn_data文件夹中找到。
为了像我们在工作中所做的那样微调模型,请按照以下步骤操作:
从原始纸张下载预先训练的权重(使用原始纸,第3步,第3步)。
下载培训数据(请参阅下载部分。您需要文件reddit_training_data.7z或cc_training_data.7z 。取决于源(CC或REDDIT),将档案放入文件夹trieftraine_data/ commun-crion-crawl-en/或triaghta crawl-en/或triagn_data/ triaad _data/ draining_data/ redditcomments-en/ and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and unzip- en and unzip a:
7za x [FILENAME].7z
要从我们用于微调的培训数据中复制相同的培训文档,请在triagn_utils/pipeline/progeine_documents_all.sh上使用脚本并调整索引参数。根据您的硬件,培训文件生成可能需要一个小时或更长时间才能计算。
最后,需要从所有培训文件中生成Tfrecords。为此,请运行:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[文件夹]需要指向培训文档的文件夹,例如训练_data/common-crawl-en/daportion/final/ 。生成后,印刷了为此特定主题生成的训练序列的数量。使用它来确定应训练模型的步骤数。 tfrecords存储在文件夹培训_utils中。
训练模型:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
该模型将自动从traine_utils文件夹中自动采用生成的tfrecords。请注意,[权夹]中的权重将被覆盖。对于新的微调模型的生成,请按照“ A.仅使用生成模型”中的说明。
为了简化收集您自己的培训数据的过程,我们添加了出版物中描述的管道的实现(请参阅I。使用我们的管道(使用grigentext api))。为了将句子标记为参数并确定其立场和方面,我们使用grigentext-api。另外,您也可以训练自己的模型(请参阅II。创建自己的管道(无参数api))。
请向grongeext-api请求用户ID和apikey。在triagh_utils/pipeline/recertentials.py上的各个常数中同时编写ID和键。
作为第一步,需要收集有关感兴趣主题的培训文件。 (注意:此步骤不是代码的一部分,必须是自我实施的)。我们这样做是通过从Common-Crawl和Reddit-Comments下载转储,并用Elasticsearch索引它们。结果需要是存储在triagh_data/[index_name]/[topic_name]/noopcoressed/的文档,其中[index_name]是数据源的名称(例如,common-crawl-en)的名称(例如common-crood-crawl-en )和[toge_name]是在哪些文档中收集了哪些文档的搜索主题(替换了pisition epienct ofient ofiped equient equient_name_name]和[index_name]和[index_name]和[index_name]和[index_name]和[]和[]。每个文档是一个单独的JSON文件,至少具有密钥“ Sents”,其中包含此文档中的句子列表:
{
"sents": ["sentence #1", "sentence #2", ...]
}
参数_classification.py将收集的所有文档用于给定主题,并将其句子分类为pro-/con-/con-/non-arguments。以下命令开始分类:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
丢弃了非差异,最终的分类参数存储在文件中,每个参数最多为200,000个参数。
exch_detection.py解析所有先前分类的参数并检测其方面。以下命令开始方面检测:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
然后将所有及其各个方面的参数存储到一个合并的单个文件中。
prepary_documents.py附加了所有具有相同主题,立场和(茎)方面的参数:培训文档:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[max_sents]设置要使用的最大参数数(如果可能的话,在pro和con参数之间均匀分布)和[min_aspect_cluster_size]/[max_aspect_cluster_size]设置一个允许的参数以附加到单个培训文档。最终文档存储在文件夹triench_data/[index_name]/[topic_name]/final/ 。脚本preeg_all_documents.sh可用于自动化该过程。
最后,要从文档中创建培训序列并开始对模型进行微调,请下载我们的微调权重(请参阅下载部分)并遵循B。使用给定的培训数据复制/微调模型,步骤4-5。
重要的是:除了培训文档外,在triagn_data/[index_name]/[topic_name]/generation_data/control_codes.jsonl上创建了具有所有基于培训文档的所有控制代码的文件。该文件保留所有控制代码以生成从微调完成后生成参数。
为了培训一个论点和立场分类模型,您可以使用Stab等人的UKP语料库和相应出版物中描述的模型。 (2018)。但是,为了更好的结果,我们建议使用Bert(Devlin等,2019)。
要培训方面检测模型,请下载我们的参数方面检测数据集(由于许可原因,有必要用您的姓名和电子邮件填写表格)。作为一个模型,我们建议从拥抱面上的BERT进行序列标记。
为了准备培训文档并微调模型,您可以使用I.使用我们的管道(带有gromentext api)的prepar_documents.py ,步骤d。如果您以以下格式保留分类数据:
该文件应命名为合并。JSONL并位于目录trienchory_data/[index_name]/[topic_name]/processed/ ,其中[index_name]是收集样本的数据源,[topic_name]相应的搜索查询的名称。
每行代表以下格式的训练样本:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
如果您觉得这项工作有帮助,请引用我们的出版物方面控制神经论证的产生:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
联系人:本杰明·席勒(Benjamin Schiller)
https://www.ukp.tu-darmstadt.de/


