controlled argument generation
1.0.0
Référentiel d'accompagnement pour la génération d'argument neuronale contrôlée par l'aspect papier.
Nous comptons sur des arguments dans notre vie quotidienne pour livrer nos opinions et les baser sur des preuves, ce qui les rend plus convaincants à leur tour. Cependant, la recherche et la formulation d'arguments peuvent être difficiles. Pour relever ce défi, nous avons formé un modèle de langue (basé sur le CTRL de Keskar et al. (2019)) pour la génération d'argument qui peut être contrôlé à un niveau fin pour générer des arguments au niveau de la phrase pour un sujet, une position et un aspect donné. Nous définissons la détection des aspects de l'argument comme une méthode nécessaire pour permettre à ce contrôle fin-canulaire et crowdsource un ensemble de données avec 5 032 arguments annotés avec des aspects. Nous publions cet ensemble de données, ainsi que les données de formation pour le modèle de génération d'argument, ses poids et les arguments générés avec le modèle.
La figure suivante montre comment le modèle de génération d'arguments a été formé:
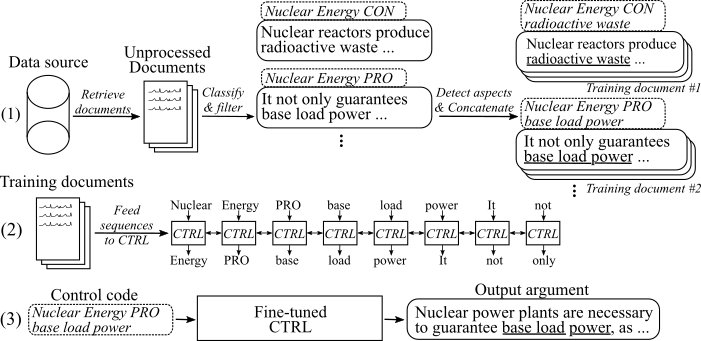
(1) Nous rassemblons plusieurs millions de documents pour huit sujets différents de deux grandes sources de données. Toutes les phrases sont classées en pro-, con- et non arguments. Nous détectons les aspects de tous les arguments avec un modèle formé sur un nouvel ensemble de données et concaténé les arguments avec le même sujet, la même position et l'aspect dans les documents de formation. (2) Nous utilisons les données classées collectées pour conditionner le modèle CTRL sur les sujets, les positions et les aspects de tous les arguments recueillis. (3) À l'inférence, passer le code de contrôle [sujet] [position] [Aspect] générera un argument qui suit ces commandes.
15. Mai 2020
Nous avons ajouté le code du modèle de génération d'argument neuronale contrôlée par l'aspect et des descriptions détrayantes sur la façon de l'utiliser. Le modèle et le code modifient les travaux de Keskar et al. (2019). Le lien vers les poids et les données de formation des modèles affinés se trouvent dans la section des téléchargements.
8. Mai 2020
L'ensemble de données de détection d'aspect d'argument peut être téléchargé à partir d'ici ( argument_aspect_dection_v1.0.7z ). À partir de là, vous pouvez également télécharger les arguments générés avec les modèles de génération d'argument ( générés_arguments.7z ) et les données pour reproduire le réglage fin du modèle de génération d'argument ( reddit_training_data.7z , CC_training_data.7z ).
Remarque : Pour des raisons de licence, ces fichiers ne peuvent pas être distribués librement. Cliquez sur l'un des fichiers vous redirigera vers un formulaire, où vous devez vous laisser nommer et envoyer un e-mail. Après avoir soumis le formulaire, vous recevrez un lien de téléchargement sous peu.
Téléchargez des ensembles de données à partir d'ici. Vous pouvez télécharger les fichiers suivants:
Remarque : Pour des raisons de licence, ces fichiers ne peuvent pas être distribués librement. Cliquez sur l'un des fichiers vous redirigera vers un formulaire, où vous devez vous laisser nommer et envoyer un e-mail. Après avoir soumis le formulaire, vous recevrez un lien de téléchargement sous peu.
Utilisez Scripts / Download_weights.sh pour télécharger les poids du modèle. Le script téléchargera les poids pour le modèle affiné sur Reddit-Comements et les données de Crawl et les décompressez dans le dossier principal du projet.
Le code a été testé avec Python3.6 . Installer toutes les exigences avec
pip install -r requirements.txt
et suivez les instructions dans le Readme original à l'usage , étape 1 et 2 .
Dans ce qui suit, nous décrivons trois approches pour utiliser le modèle de génération d'argument neuronale contrôlée par l'aspect:
A. Utiliser le modèle pour la génération uniquement
B. Utiliser les données de formation disponibles pour reproduire / affiner le modèle
C. Utilisez vos propres données pour affiner un nouveau modèle de génération d'arguments neuronaux contrôlés à l'aspect
Afin de générer des arguments, veuillez d'abord télécharger les poids pour les modèles (téléchargez le script sur scripts / téléchargement_onds.sh ). Exécutez le modèle via python generation.py --model_dir reddit_seqlen256_v1 pour le modèle formé sur les données Reddit-Comements ou python generation.py --model_dir cc_seqlen256_v1 pour le modèle formé sur les données du croucle commun. Une fois le chargement terminé, saisissez un code de contrôle, par exemple, nuclear energy CON waste , pour générer des arguments qui suivent ce code de contrôle. Pour obtenir de meilleurs résultats pour le premier argument généré, vous pouvez mettre fin au code de contrôle avec une période ou un côlon ("." Ou ":"). Pour plus de détails, veuillez vous référer au document.
Remarque : les codes de contrôle autorisés pour chaque sujet et la source de données peuvent être trouvés dans le dossier Training_data .
Pour affiner le modèle comme nous l'avons fait dans notre travail, veuillez suivre ces étapes:
Téléchargez les poids pré-formés à partir de l'article d'origine (Readme original à l'usage , étape 3 ).
Téléchargez les données de formation ( voir la section des téléchargements .
7za x [FILENAME].7z
Pour reproduire les mêmes documents de formation à partir des données de formation que nous avons utilisés pour le réglage fin, veuillez utiliser le script sur Training_Utils / Pipeline / Prepare_Documents_all.sh et adapter le paramètre d'index . Selon votre matériel, la génération de documents de formation peut prendre une heure ou plus à calculer.
Enfin, les tfrecords doivent être générés à partir de tous les documents de formation. Pour ce faire, veuillez courir:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Dossier] doit pointer vers le dossier des documents de formation, par exemple Training_Data / Common-Crawl-en / Abortion / Final / . Après génération, le nombre de séquences de formation générés pour ce sujet spécifique est imprimée. Utilisez-le pour déterminer le nombre d'étapes sur lesquelles le modèle doit être formé. Les tfrecords sont stockés dans Folder Training_Utils .
Former le modèle:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
Le modèle prend automatiquement les tfrecords générés à partir du dossier Training_Utils . Veuillez noter que les poids dans [le dossier de poids] seront écrasés. Pour la génération avec le modèle nouvellement réglé, suivez les instructions dans " A. Utiliser le modèle pour la génération uniquement ".
Pour faciliter le processus de collecte de vos propres données de formation, nous ajoutons notre implémentation du pipeline décrit dans notre publication (voir I. Utilisez notre pipeline (avec API ArgumentExt)). Pour étiqueter les phrases comme des arguments et pour identifier leurs positions et leurs aspects, nous utilisons l'argumentaire-API. Alternativement, vous pouvez également former vos propres modèles (voir II. Créez votre propre pipeline (sans API ArgumentExt)).
Veuillez demander un utilisateur et Apikey pour l'argumentaire-API. Écrivez à la fois l'ID et la clé dans les constantes respectives de Training_Utils / Pipeline / Credentials.py .
Dans une première étape, les documents de formation pour un sujet d'intérêt doivent être recueillis. ( Remarque: cette étape ne fait pas partie du code et doit être autonome ). Nous l'avons fait en téléchargeant un vidage de Common-Crawl et Reddit-Comements et en les indexant avec Elasticsearch. Le résultat doit être des documents stockés sur Training_data / [index_name] / [topic_name] / non propulsé / , où [index_name] est le nom de la source de données (par exemple Common-Crawl-en ) et [topic_name] est le sujet de recherche pour lequel les documents ont été recueillis (remplacer les espaces blancs). Chaque document est un File JSON distinct avec au moins la clé "Sense" qui contient une liste de phrases de ce document:
{
"sents": ["sentence #1", "sentence #2", ...]
}
L' argument_classification.py prend tous les documents recueillis pour un sujet donné et classe leurs phrases en pro- / con- / non arguments. La commande suivante démarre la classification:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Les non-arguments sont rejetés et les arguments classifiés finaux sont stockés dans des fichiers avec un maximum de 200 000 arguments chacun sur Training_data / [index_name] / [topic_name] / traité / .
L' aspect_dection.py analyse tous les arguments précédemment classés et détecte leurs aspects. La commande suivante démarre la détection d'aspect:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Tous les arguments avec leurs aspects sont ensuite stockés dans un seul fichier fusionné.jsonl sur Training_data / [index_name] / [topic_name] / traité /.
Le prépare_Documents.py ajoute tous les arguments qui ont le même sujet, position et (tige) à un document de formation:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[MAX_SENTS] Définit le nombre maximal d'arguments à utiliser (uniformément dévoué entre les arguments Pro et Con si possible) et [MIN_ASPPEPT_CLUSTER_SIZE] / [MAX_ASPECT_CLUSTER_SIZE] définit le nombre min / max d'arguments autorisés pour ajouter pour un seul document de formation. Les documents finaux sont stockés dans Folder Training_data / [index_name] / [topic_name] / final / . Le script préparent_all_documents.sh peut être utilisé pour automatiser le processus.
Enfin, pour créer des séquences de formation à partir des documents et commencer à affiner le modèle, veuillez télécharger nos poids affinés (voir la section de téléchargement) et suivre B. Utiliser les données de formation données pour reproduire / affiner le modèle, étapes 4-5.
Important : En plus des documents de formation, un fichier avec tous les codes de contrôle basés sur les documents de formation est créé sur Training_data / [index_name] / [topic_name] /generation_data/control_codes.jsonl . Ce fichier contient tous les codes de contrôle pour générer des arguments à partir d'une fois le réglage fin terminé.
Pour former un modèle de classification d'argument et de position, vous pouvez utiliser le corpus UKP et les modèles décrits dans la publication correspondante par Stab et al. (2018). Pour de meilleurs résultats, cependant, nous suggérons d'utiliser Bert (Devlin et al., 2019).
Pour former un modèle de détection d'aspect, veuillez télécharger notre ensemble de données de détection d'aspect d'argument (pour des raisons de licence, il est nécessaire de remplir le formulaire avec votre nom et votre e-mail). En tant que modèle, nous suggérons à Bert de HuggingFace pour le marquage de séquence.
Afin de préparer des documents de formation et d'adapter le modèle, vous pouvez utiliser la préparation_documents.py comme décrit dans I. Utilisez notre pipeline (avec API ArgumentExt), étape d. Si vous conservez vos données classifiées dans le format suivant:
Le fichier doit être nommé fusiond.jsonl et situé dans le répertoire Training_Data / [index_name] / [topic_name] / traité / , où [index_name] est la source de données à partir de l'endroit où les échantillons ont été recueillis et [topic_name] le nom de la requête de recherche respective pour ces données.
Chaque ligne représente un échantillon de formation dans le format suivant:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Si vous trouvez ce travail utile, veuillez citer la génération d'argument neuronale contrôlée par l'aspect de publication:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Personne de contact: Benjamin Schiller
https://www.ukp.tu-darmstadt.de/


