controlled argument generation
1.0.0
Repositorio acompañante de la generación de argumentos neuronales controlados por el aspecto de papel.
Confiamos en los argumentos en nuestra vida diaria para entregar nuestras opiniones y basarlas en evidencia, haciéndolos más convincentes a su vez. Sin embargo, encontrar y formular argumentos puede ser un desafío. Para abordar este desafío, entrenamos un modelo de idioma (basado en el CTRL por Keskar et al. (2019)) para la generación de argumentos que se pueden controlar en un nivel de grano fino para generar argumentos a nivel de oración para un tema, postura y aspecto determinado. Definimos la detección de aspectos de argumentos como un método necesario para permitir este control granular y crowdsource un conjunto de datos con 5.032 argumentos anotados con aspectos. Lanzamos este conjunto de datos, así como los datos de capacitación para el modelo de generación de argumentos, sus pesos y los argumentos generados con el modelo.
La siguiente figura muestra cómo se entrenó el modelo de generación de argumentos:
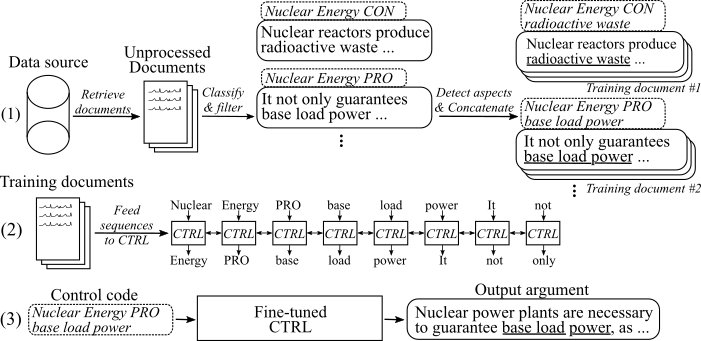
(1) Recopilamos varios millones de documentos para ocho temas diferentes de dos grandes fuentes de datos. Todas las oraciones se clasifican en Pro-, Con- y no argumentos. Detectamos aspectos de todos los argumentos con un modelo capacitado en un nuevo conjunto de datos y concatenan los argumentos con el mismo tema, postura y aspecto en documentos de capacitación. (2) Utilizamos los datos clasificados recopilados para condicionar el modelo CTRL sobre los temas, las posturas y los aspectos de todos los argumentos reunidos. (3) En inferencia, pasar el código de control [tema] [postura] [aspecto] generará un argumento que sigue estos comandos.
15. Mayo de 2020
Hemos agregado el código para el modelo de generación de argumentos neuronales controlados por aspectos y descripciones detalladas sobre cómo usarlo. El modelo y el código modifican el trabajo de Keskar et al. (2019). El enlace a los pesos del modelo y los datos de entrenamiento se pueden encontrar en la sección Descargas.
8. Mayo de 2020
El conjunto de datos de detección de aspecto del argumento se puede descargar desde aquí ( argumento_aspect_detection_v1.0.7z ). A partir de ahí, también puede descargar los argumentos generados con los modelos de generación de argumentos ( generados_argumentos.7z ) y los datos para reproducir el ajuste del modelo de generación de argumentos ( reddit_training_data.7z , cc_training_data.7z ).
Nota : Debido a las razones de la licencia, estos archivos no se pueden distribuir libremente. Al hacer clic en cualquiera de los archivos, lo redirigirá a un formulario, donde debe dejar su nombre y correo electrónico. Después de enviar el formulario, recibirá un enlace de descarga en breve.
Descargue conjuntos de datos desde aquí. Puede descargar los siguientes archivos:
Nota : Debido a las razones de la licencia, estos archivos no se pueden distribuir libremente. Al hacer clic en cualquiera de los archivos, lo redirigirá a un formulario, donde debe dejar su nombre y correo electrónico. Después de enviar el formulario, recibirá un enlace de descarga en breve.
Use scripts/download_wightss.sh para descargar los pesos del modelo. El script descargará los pesos para el modelo ajustado en los recursos de Reddit y los datos de rastreo común y los desabrochará en la carpeta del proyecto principal.
El código se probó con Python3.6 . Instalar todos los requisitos con
pip install -r requirements.txt
y siga las instrucciones en el ReadMe original en el uso , Paso 1 y 2 .
A continuación, describimos tres enfoques para usar el modelo de generación de argumentos neuronales controlados por el aspecto:
A. Use el modelo solo para la generación
B. Use los datos de entrenamiento disponibles para reproducir/ajustar el modelo
C. Use sus propios datos para ajustar un nuevo modelo de generación de argumentos neuronales controlados por el aspecto
Para generar argumentos, primero descargue los pesos para los modelos (descargue el script en scripts/download_weights.sh ). Ejecute el modelo a través de python generation.py --model_dir reddit_seqlen256_v1 para el modelo entrenado en datos Reddit-Comments o python generation.py --model_dir cc_seqlen256_v1 para el modelo entrenado en datos de acordamiento común. Después de que se complete la carga, escriba un código de control, por ejemplo nuclear energy CON waste , para generar argumentos que siguen este código de control. Para obtener mejores resultados para el primer argumento generado, puede finalizar el código de control con un período o colon ("." O ":"). Para obtener más detalles, consulte el documento.
Nota : Los códigos de control permitidos para cada tema y fuente de datos se pueden encontrar en la carpeta Training_Data .
Para ajustar el modelo como lo hemos hecho en nuestro trabajo, siga estos pasos:
Descargue los pesos previamente capacitados del artículo original (Readme original en el uso , paso 3 ).
Descargue los datos de capacitación (consulte la sección Descargas. Necesita el archivo reddit_training_data.7z o cc_training_data.7z . Dependiendo de la fuente (cc o reddit), coloque los archivos en carpeta_data / común-crawl-en/ o entrenador_data/ redditcompments-en/ y unzip vía::
7za x [FILENAME].7z
Para reproducir los mismos documentos de capacitación de los datos de capacitación que utilizamos para el ajuste fino, use el script en Training_utils/Pipeline/prepare_documents_all.sh y adapte el parámetro de índice . Dependiendo de su hardware, la generación de documentos de entrenamiento puede tardar una hora o más en calcularse.
Por último, los TFRecords deben generarse a partir de todos los documentos de capacitación. Para hacerlo, corre:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Carpeta] debe señalar la carpeta de los documentos de entrenamiento, por ejemplo, entrenamiento_data/común-crawl-en/aborto/final/ . Después de generar, se imprime el número de secuencias de entrenamiento generadas para este tema específico. Use esto para determinar la cantidad de pasos en los que debe ser entrenado. Los TFRecords se almacenan en carpetas Training_utils .
Entrena el modelo:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
El modelo toma los TFRecords generados automáticamente desde la carpeta Training_utils . Tenga en cuenta que los pesos en [carpeta de pesas] se sobrescribirán. Para la generación con el modelo recién ajustado, siga las instrucciones en " A. Modelo de uso solo para generación ".
Para aliviar el proceso de recopilar sus propios datos de capacitación, agregamos nuestra implementación de la tubería descrita en nuestra publicación (ver I. Use nuestra tubería (con API de texto argumento)). Para etiquetar las oraciones como argumentos e identificar sus posturas y aspectos, utilizamos el Text-API. Alternativamente, también puede entrenar sus propios modelos (ver II. Cree su propia tubería (sin API de texto argumentado)).
Solicite un ID de usuario y apikey para el argumentExt-API. Escriba tanto ID como clave en las constantes respectivas en Training_utils/Pipeline/Credentials.py .
Como primer paso, se deben reunir documentos de capacitación para un tema de interés. ( Nota: este paso no es parte del código y debe ser autoimpled ). Lo hicimos descargando un volcado de Common-Trawl y Reddit-Comments e indexándolos con Elasticsearch. El resultado debe ser documentos que se almacenen en Training_Data/[index_name]/[topic_name]/sin procesar/ , donde [index_name] es el nombre de la fuente de datos ( p. Ej. Cada documento es un archivo JSON separado con al menos la clave "Sents" que contiene una lista de oraciones de este documento:
{
"sents": ["sentence #1", "sentence #2", ...]
}
El argumento_classification.py toma todos los documentos reunidos para un tema determinado y clasifica sus oraciones en pro-/con-/no argumentos. El siguiente comando inicia la clasificación:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Los no argumentos se descartan y los argumentos clasificados finales se almacenan en archivos con un máximo de 200,000 argumentos cada uno en Training_Data/[index_name]/[topic_name]/procesado/ .
El aspecto_detection.py analiza todos los argumentos previamente clasificados y detecta sus aspectos. El siguiente comando inicia la detección de aspecto:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Todos los argumentos con sus aspectos se almacenan en un solo archivo fusionado.jsonl en entrenador_data /[index_name]/[topic_name]/procesado/.
El prepare_documents.py agrega todos los argumentos que tienen el mismo tema, postura y aspecto (de) a un documento de capacitación:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[Max_sents] establece el número máximo de argumentos a usar (de manera uniforme entre los argumentos de Pro y Con si es posible) y [min_aspect_cluster_size]/[max_aspect_cluster_size] establece el número min/max de argumentos permitidos para solicitar un documento de entrenamiento único. Los documentos finales se almacenan en carpeta entrenador_data/[index_name]/[topic_name]/final/ . El script prepare_all_documents.sh se puede usar para automatizar el proceso.
Finalmente, para crear secuencias de entrenamiento de los documentos y comenzar a ajustar el modelo, descargue nuestros pesos ajustados (consulte la sección de descarga) y siga B. Use datos de entrenamiento dados para reproducir/ajustar el modelo, los pasos 4-5.
IMPORTANTE : Además de los documentos de capacitación, se crea un archivo con todos los códigos de control basados en los documentos de capacitación en Training_Data/[index_name]/[topic_name] /generation_data/control_codes.jsonl . Este archivo contiene todos los códigos de control para generar argumentos de después de que haya terminado el ajuste.
Para capacitar un modelo de clasificación de argumentos y posiciones, puede usar el Corpus UKP y los modelos descritos en la publicación correspondiente de Stab et al. (2018). Sin embargo, para obtener mejores resultados, sugerimos usar Bert (Devlin et al., 2019).
Para capacitar un modelo de detección de aspecto, descargue nuestro conjunto de datos de detección de aspectos de argumento (debido a razones de licencia, es necesario llenar el formulario con su nombre y correo electrónico). Como modelo, sugerimos Bert de Huggingface para el etiquetado de secuencia.
Para preparar documentos de capacitación y ajustar el modelo, puede usar prepare_documents.py como se describe en I. Use nuestra tubería (con API de texto argumentado), paso d. Si mantiene sus datos clasificados en el siguiente formato:
El archivo debe nombrarse fused.jsonl y ubicado en el directorio training_data/[index_name]/[topic_name]/procesado/ , donde [index_name] es la fuente de datos desde donde se recopilaron las muestras y [topic_name] el nombre de la consulta de búsqueda respectiva para estos datos.
Cada línea representa una muestra de entrenamiento en el siguiente formato:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Si encuentra útil este trabajo, cite nuestra generación de argumentos neuronales controlados por el aspecto de la publicación:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Persona de contacto: Benjamin Schiller
https://www.ukp.tu-darmstadt.de/


