controlled argument generation
1.0.0
Repositório que acompanha a geração de argumentos neurais controlados por aspectos em papel.
Contamos com argumentos em nossas vidas diárias para entregar nossas opiniões e baseá -las em evidências, tornando -as mais convincentes. No entanto, encontrar e formular argumentos pode ser um desafio. Para enfrentar esse desafio, treinamos um modelo de idioma (com base no CTRL de Keskar et al. (2019)) para a geração de argumentos que pode ser controlada em um nível de granulação fina para gerar argumentos no nível da sentença para um determinado tópico, postura e aspecto. Definimos a detecção de aspectos de argumento como um método necessário para permitir esse controle e crowdsource fino um conjunto de dados com 5.032 argumentos anotados com aspectos. Lançamos esse conjunto de dados, bem como os dados de treinamento para o modelo de geração de argumentos, seus pesos e os argumentos gerados com o modelo.
A figura a seguir mostra como o modelo de geração de argumentos foi treinado:
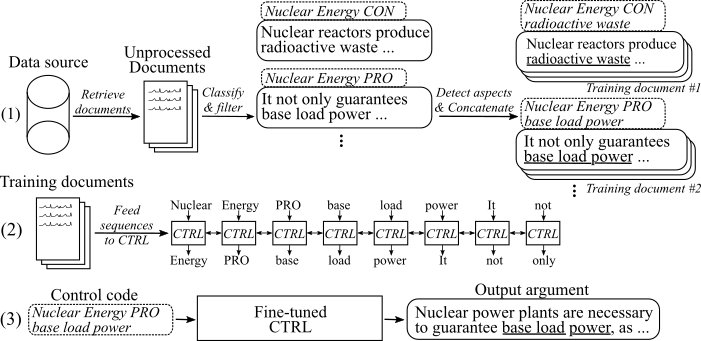
(1) Reunimos vários milhões de documentos para oito tópicos diferentes de duas grandes fontes de dados. Todas as frases são classificadas em pro-, con- e não-argumentos. Detectamos aspectos de todos os argumentos com um modelo treinado em um novo conjunto de dados e concatenamos argumentos com o mesmo tópico, postura e aspecto nos documentos de treinamento. (2) Usamos os dados classificados coletados para condicionar o modelo CTRL sobre os tópicos, posições e aspectos de todos os argumentos reunidos. (3) na inferência, a passagem do código de controle [tópico] [Stance] [aspecto] gerará um argumento que segue esses comandos.
15 de maio de 2020
Adicionamos o código para o modelo de geração de argumentos neurais controlados por aspectos e descrições de detectar como usá-lo. O modelo e o código modificam o trabalho de Keskar et al. (2019). O link para os pesos do modelo ajustado e os dados de treinamento pode ser encontrado na seção de downloads.
8 de maio de 2020
O conjunto de dados de detecção de aspecto do argumento pode ser baixado aqui ( argument_aspect_detection_v1.0.7z ). A partir daí, você também pode baixar os argumentos gerados com os modelos de geração de argumentos ( gerados_argudes.7z ) e os dados para reproduzir o ajuste fino do modelo de geração de argumentos ( reddit_training_data.7z , cc_training_data.7z ).
NOTA : Por motivos de licença, esses arquivos não podem ser distribuídos livremente. Clicar em qualquer um dos arquivos o redirecionará para um formulário, onde você deve deixar seu nome e e -mail. Depois de enviar o formulário, você receberá um link para download em breve.
Baixe conjuntos de dados daqui. Você pode baixar os seguintes arquivos:
NOTA : Por motivos de licença, esses arquivos não podem ser distribuídos livremente. Clicar em qualquer um dos arquivos o redirecionará para um formulário, onde você deve deixar seu nome e e -mail. Depois de enviar o formulário, você receberá um link para download em breve.
Use scripts/download_weights.sh para baixar os pesos do modelo. O script baixará os pesos para o modelo ajustado em complos do Reddit e dados de cravo comum e os descompõe na pasta principal do projeto.
O código foi testado com Python3.6 . Instale todos os requisitos com
pip install -r requirements.txt
e siga as instruções no ReadMe original no uso , as etapas 1 e 2 .
A seguir, descrevemos três abordagens para usar o modelo de geração de argumentos neurais controlados por aspectos:
A. Use o modelo apenas para geração
B. Use os dados de treinamento disponíveis para reproduzir/ajustar o modelo
C. Use seus próprios dados para ajustar um novo modelo de geração de argumentos neurais controlados por aspectos
Para gerar argumentos, primeiro faça o download dos pesos dos modelos (faça o download do script em scripts/download_weights.sh ). Execute o modelo via python generation.py --model_dir reddit_seqlen256_v1 para o modelo treinado em dados do Reddit-Compomments ou python generation.py --model_dir cc_seqlen256_v1 para o modelo treinado em dados comuns. Após a conclusão do carregamento, digite um código de controle, por exemplo nuclear energy CON waste , para gerar argumentos que seguem esse código de controle. Para obter melhores resultados para o primeiro argumento gerado, você pode encerrar o código de controle com um período ou cólon ("." Ou ":"). Para mais detalhes, consulte o artigo.
Nota : Os códigos de controle permitidos para cada tópico e fonte de dados podem ser encontrados na pasta Training_Data .
Para ajustar o modelo como fizemos em nosso trabalho, siga estas etapas:
Faça o download dos pesos pré-treinados do artigo original (Readme original no uso , Etapa 3 ).
Faça o download dos dados de treinamento (consulte a seção de downloads. Você precisa do arquivo reddit_training_data.7z ou cc_traning_data.7z . Dependendo da fonte (CC ou Reddit), coloque os arquivos em pastas Treinamento_data/ Common-Crawl-en/ ou Treination_data/ RedditCommments-in/ e Unzing via: un:
7za x [FILENAME].7z
Para reproduzir os mesmos documentos de treinamento dos dados de treinamento que usamos para ajustar fino, use o script em treinamento em treinamento/pipeline/prepare_documents_all.sh e adapte o parâmetro de índice . Dependendo do seu hardware, a geração de documentos de treinamento pode levar uma hora ou mais para calcular.
Por fim, os tfrcords precisam ser gerados a partir de todos os documentos de treinamento. Para fazer isso, corra:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Pasta] precisa apontar para a pasta dos documentos de treinamento, por exemplo , treinamento_data/Common-Crawl-en/abortion/final/ . Após a geração, o número de sequências de treinamento geradas para esse tópico específico é impresso. Use isso para determinar o número de etapas em que o modelo deve ser treinado. Os TfRecords são armazenados em pastas treinamento_utils .
Treine o modelo:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
O modelo pega os TfRecords gerados automaticamente a partir da pasta Training_utils . Observe que os pesos na pasta [pesos] serão substituídos. Para geração com o modelo recém-ajustado, siga as instruções em " A. Use o modelo apenas para geração ".
Para facilitar o processo de coleta de seus próprios dados de treinamento, adicionamos nossa implementação do pipeline descrito em nossa publicação (consulte I. Use nosso pipeline (com a API ArgumentExt)). Para rotular frases como argumentos e identificar suas posturas e aspectos, usamos o argumentoxt-api. Como alternativa, você também pode treinar seus próprios modelos (consulte II. Crie seu próprio pipeline (sem a API do ArgumentExt)).
Solicite um UserID e APIKEY para o ArgumentExt-api. Escreva o ID e a chave nas respectivas constantes em treinamento_utils/pipeline/credenciais.py .
Como primeiro passo, os documentos de treinamento para um tópico de interesse precisam ser coletados. ( Nota: esta etapa não faz parte do código e precisa ser auto-implementada ). Fizemos isso baixando um dump da Common-Crawt e Reddit-Commments e indexando-os com o Elasticsearch. The outcome needs to be documents that are stored at training_data/[INDEX_NAME]/[TOPIC_NAME]/unprocessed/ , where [INDEX_NAME] is the name of the data source (eg common-crawl-en ) and [TOPIC_NAME] is the search topic for which documents were gathered (replace whitespaces in the [INDEX_NAME] and [TOPIC_NAME] with underscores). Cada documento é um arquivo JSON separado, com pelo menos os principais "Sents", que contém uma lista de frases deste documento:
{
"sents": ["sentence #1", "sentence #2", ...]
}
O argument_classification.py leva todos os documentos coletados para um determinado tópico e classifica suas frases em pro//não-argumentos. O comando a seguir inicia a classificação:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Os não-argumentos são descartados e os argumentos classificados finais são armazenados em arquivos com no máximo 200.000 argumentos cada um em treinamento_data/[index_name]/[tópico_name]/processado/ .
O aspecto_detection.py analisa todos os argumentos classificados anteriormente e detecta seus aspectos. O comando a seguir inicia a detecção de aspecto:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Todos os argumentos com seus aspectos são armazenados em um único arquivo mesclado.jsonl em treinamento_data /[index_name]/[tópico_name]/processado/.
O prepare_documents.py anexa todos os argumentos que têm o mesmo tópico, postura e aspecto (Stemed) a um documento de treinamento:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[Max_sents] define o número máximo de argumentos a serem usados (uniformemente desenvolvido entre os argumentos pro e o CON, se possível) e [min_aspect_cluster_size]/[max_aspect_cluster_size] define o número min/max de argumentos permitidos para anexar um único documento de treinamento. Os documentos finais são armazenados na pasta treinamento_data/[index_name]/[tópico_name]/final/ . O script prepare_all_documents.sh pode ser usado para automatizar o processo.
Finalmente, para criar sequências de treinamento a partir dos documentos e iniciar o ajuste fina do modelo, faça o download de nossos pesos ajustados (consulte a seção de download) e siga B. Use dados dados de treinamento para reproduzir/ajustar o modelo, etapas 4-5.
IMPORTANTE : Além dos documentos de treinamento, um arquivo com todos os códigos de controle com base nos documentos de treinamento é criado em treinamento_data/[index_name]/[tópico_name] /generation_data/control_codes.jsonl . Esse arquivo mantém todos os códigos de controle para gerar argumentos após o término do ajuste fino.
Para treinar um modelo de argumento e classificação de postura, você pode usar o corpus UKP e os modelos descritos na publicação correspondente de Stab et al. (2018). Para melhores resultados, no entanto, sugerimos usar Bert (Devlin et al., 2019).
Para treinar um modelo de detecção de aspecto, faça o download do nosso conjunto de dados de detecção de aspectos de argumento (devido a motivos de licença, é necessário preencher o formulário com seu nome e email). Como modelo, sugerimos Bert de Huggingface para marcação de sequência.
Para preparar documentos de treinamento e ajustar o modelo, você pode usar o prepare_documents.py , conforme descrito em I. Use nosso pipeline (com a API ArgumentExt), Etapa d. Se você mantiver seus dados classificados no seguinte formato:
O arquivo deve ser nomeado MERGED.JSONL e localizado no diretório Treinamento_data/[index_name]/[tópico_name]/processado/ , onde [index_name] é a fonte de dados de onde as amostras foram coletadas e [tópicos_name] o nome da respectiva consulta de pesquisa para esses dados.
Cada linha representa uma amostra de treinamento no seguinte formato:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Se você achar esse trabalho útil, cite nossa publicação com geração de argumentos neurais controlados por aspectos:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Pessoa de contato: Benjamin Schiller
https://www.ukp.tu-carmstadt.de/


