controlled argument generation
1.0.0
紙のアスペクト制御神経引数生成のための添付リポジトリ。
私たちは、日常生活の議論に頼って意見を伝え、証拠に基づいて、より説得力があります。ただし、議論を見つけることと策定は困難な場合があります。この課題に取り組むために、私たちは言語モデル(Keskar et al。(2019)によるCtrlに基づいて)を訓練しました。これは、特定のトピック、スタンス、および側面の文レベルの引数を生成するために細粒レベルで制御できる引数生成を生成します。引数のアスペクト検出を、この細かい粒状制御を許可し、5,032の引数がアスペクトに注釈が付けられたデータセットをクラウドソーシングするための必要な方法として定義します。このデータセットと、引数生成モデル、その重み、およびモデルで生成された引数のトレーニングデータをリリースします。
次の図は、引数生成モデルがどのようにトレーニングされたかを示しています。
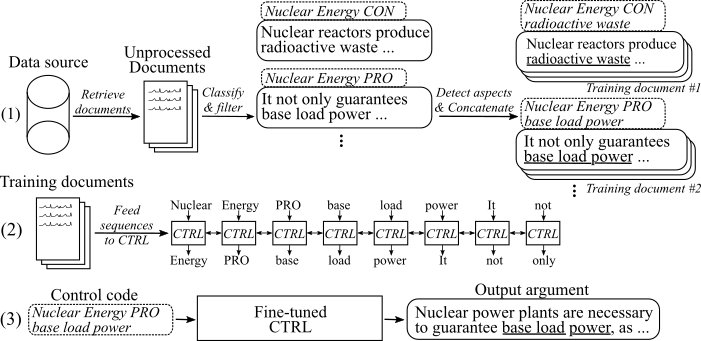
(1)2つの大規模なデータソースからの8つの異なるトピックについて、数百万のドキュメントを収集します。すべての文は、プロ、コングメント、および非アーグメントに分類されます。新しいデータセットで訓練されたモデルを使用して、すべての引数の側面を検出し、同じトピック、スタンス、およびトレーニングドキュメントの側面を持つ引数を連結します。 (2)収集された分類データを使用して、収集されたすべての議論のトピック、スタンス、および側面にCTRLモデルを条件付けます。 (3)推論では、コントロールコード[トピック] [Stance] [Aspect]を渡すと、これらのコマンドに従う引数が生成されます。
15。2020年5月
アスペクト制御されたニューラル引数生成モデルのコードを追加し、それを使用する方法について説明しました。モデルとコードは、Keskarらによる作業を変更します。 (2019)。微調整されたモデルの重みとトレーニングデータへのリンクは、ダウンロードセクションにあります。
8。2020年5月
引数アスペクト検出データセットは、ここからダウンロードできます( argump_aspect_detection_v1.0.7z )。そこから、引数生成モデル( Generated_arguments.7z )で生成された引数をダウンロードして、引数生成モデル( Reddit_training_data.7z 、 cc_training_data.7z )の微調整を再現することもできます。
注:ライセンスの理由により、これらのファイルを自由に配布することはできません。ファイルのいずれかをクリックすると、フォームにリダイレクトされ、名前とメールを残す必要があります。フォームを送信すると、まもなくダウンロードリンクが届きます。
ここからデータセットをダウンロードしてください。次のファイルをダウンロードできます。
注:ライセンスの理由により、これらのファイルを自由に配布することはできません。ファイルのいずれかをクリックすると、フォームにリダイレクトされ、名前とメールを残す必要があります。フォームを送信すると、まもなくダウンロードリンクが届きます。
スクリプト/download_weights.shを使用して、モデルの重みをダウンロードします。このスクリプトは、Reddit-CommentsとCommon-Crawlデータで微調整されたモデルの重みをダウンロードし、それらをメインプロジェクトフォルダーに解凍します。
コードはPython3.6でテストされました。すべての要件をにインストールします
pip install -r requirements.txt
元のREADMEの指示に従って、使用法のステップ1および2に従ってください。
以下では、アスペクト制御された神経引数生成モデルを使用するための3つのアプローチについて説明します。
A.生成のみにモデルを使用します
B.利用可能なトレーニングデータを使用して、モデルを再現/微調整します
C.独自のデータを使用して、新しいアスペクトコントロールされた神経引数生成モデルを微調整します
引数を生成するには、最初にモデルのWeightsをダウンロードしてください(スクリプト/download_weights.shでスクリプトをダウンロードしてください)。 python generation.py --model_dir reddit_seqlen256_v1 Reddit-Commentsデータまたはpython generation.py --model_dir cc_seqlen256_v1読み込みが完了した後、 nuclear energy CON wasteなどの制御コードを入力して、この制御コードに従う引数を生成します。最初に生成された引数のより良い結果を得るには、期間またはコロン( "。"または ":")でコントロールコードを終了できます。詳細については、論文を参照してください。
注:各トピックとデータソースの許可された制御コードは、 Training_Dataフォルダーにあります。
私たちの仕事で行ったようにモデルを微調整するために、次の手順に従ってください。
元の論文から事前に訓練されたウェイトをダウンロードします(使用状況の元のReadMe、ステップ3 )。
トレーニングデータをダウンロードします(ダウンロードセクションを参照してください。ファイルreddit_training_data.7zまたはcc_training_data.7zが必要です。ソース(ccまたはreddit)に応じて、アーカイブをフォルダートレーニング_data/ common-crawl-en/ or training_data/ redditcomments-en/ and unzip byに入れます。
7za x [FILENAME].7z
微調整に使用したのと同じトレーニングドキュメントをトレーニングデータから再現するには、 Training_utils/pipeline/prepare_documents_all.shでスクリプトを使用して、インデックスパラメーターを適応させてください。ハードウェアに応じて、トレーニングドキュメントの生成は計算に1時間以上かかる場合があります。
最後に、Trecordはすべてのトレーニング文書から生成する必要があります。そうするために、実行してください:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[フォルダー]トレーニングドキュメントのフォルダーを指す必要があります。たとえば、 Training_Data/Common-Crawl-en/corport/final/ 。生成後、この特定のトピックに対して生成されたトレーニングシーケンスの数が印刷されます。これを使用して、モデルのトレーニングを行う必要があるステップ数を決定します。 Trecordsは、フォルダーTraining_utilsに保存されます。
モデルのトレーニング:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
このモデルは、 Training_utilsフォルダーから生成されたtrecordを自動的に取得します。 [Weightsフォルダー]の重みが上書きされることに注意してください。新しく微調整されたモデルを使用した生成については、「 A.生成のみを使用する」の指示に従ってください。
独自のトレーニングデータを収集するプロセスを容易にするために、出版物に記載されているパイプラインの実装を追加します(I.を参照(Argumentext APIを使用)を参照)。文章を引数としてラベル付けし、それらのスタンスと側面を特定するために、argumpedext-apiを使用します。または、独自のモデルをトレーニングすることもできます(IIを参照してください。独自のパイプラインを作成します(Argumentext APIなし))。
argumentext-apiについては、useridとapikeyをリクエストしてください。 training_utils/pipeline/credentials.pyで、それぞれの定数にIDとキーの両方を書き込みます。
最初のステップとして、関心のあるトピックのトレーニング文書を収集する必要があります。 (注:このステップはコードの一部ではなく、自己包括的でなければなりません)。 Common-CrawlとReddit-Commentsからダンプをダウンロードし、ElasticSearchでインデックスを作成することでそうしました。結果は、training_data/[index_name]/[topic_name]/unprocessed/に保存されているドキュメントである必要があります。ここで、[index_name]はデータソースの名前です(例: Common-crawl-en )および[Topic_name]は、[index_name]と[index_name]と[index_name]のホワイトスペースを置き換える)の検索トピックです。各ドキュメントは、少なくともこのドキュメントからの文のリストを保持する重要な「セント」を備えた別のJSONファイルです。
{
"sents": ["sentence #1", "sentence #2", ...]
}
argument_classification.pyは、特定のトピックのために収集されたすべてのドキュメントを取得し、その文章をpro-/con-/non argumentsに分類します。次のコマンドは分類を開始します。
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
非アーグメントは廃棄され、最終的な分類された引数は、それぞれTraining_data/[index_name]/[topic_name]/processed/で最大20万の引数を持つファイルに保存されます。
Aspect_detection.pyは、以前に分類されたすべての引数をすべて解析し、その側面を検出します。次のコマンドは、アスペクト検出を開始します。
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
次に、その側面とのすべての引数は、 training_data /[index_name]/[topic_name]/processed/で1つのファイルmerged.jsonlに保存されます。
prepare_documents.pyは、トレーニングドキュメントに同じトピック、スタンス、および(STEMMED)側面を持つすべての引数を追加します。
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[MAX_SENTS]は、使用する引数の最大数を設定します(可能であれば、プロとCONの引数の間で均等に分割されます)と[min_aspect_cluster_size]/[max_aspect_cluster_size]は、単一のトレーニング文書に追加するために許可された引数のmin/max数を設定します。最終ドキュメントは、フォルダーTraining_data/[index_name]/[topic_name]/final/に保存されます。スクリプトprepare_all_documents.shを使用してプロセスを自動化できます。
最後に、ドキュメントからトレーニングシーケンスを作成し、モデルの微調整を開始するには、微調整されたウェイト(ダウンロードセクションを参照)をダウンロードし、Bをフォローしてください。
重要:トレーニングドキュメントに加えて、トレーニングドキュメントに基づいたすべての制御コードを含むファイルは、training_data/[index_name]/[topic_name] /generation_data/control_codes.jsonlで作成されます。このファイルは、微調整が終了した後から引数を生成するためにすべての制御コードを保持します。
議論とスタンス分類モデルを訓練するには、UKPコーパスと、Stab et al。 (2018)。ただし、より良い結果を得るには、Bertを使用することをお勧めします(Devlin et al。、2019)。
アスペクト検出モデルをトレーニングするには、引数アスペクト検出データセットをダウンロードしてください(ライセンスの理由により、フォームに名前とメールで入力する必要があります)。モデルとして、シーケンスタグ付けについてはHuggingfaceのBertをお勧めします。
トレーニングドキュメントを準備してモデルを微調整するには、I。で説明されているようにprepare_documents.pyを使用できます。分類されたデータを次の形式で保持している場合:
ファイルはmerged.jsonlに名前を付け、ディレクトリトレーニング_data/[index_name]/[topic_name]/processed/に命名する必要があります。ここで、[index_name]はサンプルが収集された場所であり、[topic_name]このデータのそれぞれの検索クエリの名前です。
各行は、次の形式でトレーニングサンプルを表します。
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
この作品が役立つと思われる場合は、出版物のアスペクトコントロールされた神経引数生成を引用してください。
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
連絡先:ベンジャミンシラー
https://www.ukp.tu-darmstadt.de/


