controlled argument generation
1.0.0
ที่เก็บข้อมูลสำหรับการสร้างอาร์กิวเมนต์ระบบประสาทที่ควบคุมโดยด้านกระดาษ
เราพึ่งพาข้อโต้แย้งในชีวิตประจำวันของเราเพื่อแสดงความคิดเห็นและยึดหลักฐานพวกเขาทำให้พวกเขาเชื่อมั่นมากขึ้นในทางกลับกัน อย่างไรก็ตามการค้นหาและการกำหนดข้อโต้แย้งอาจเป็นเรื่องที่ท้าทาย เพื่อจัดการกับความท้าทายนี้เราได้ฝึกอบรมรูปแบบภาษา (ขึ้นอยู่กับ CTRL โดย Keskar et al. (2019)) สำหรับการสร้างอาร์กิวเมนต์ที่สามารถควบคุมในระดับที่ละเอียดเพื่อสร้างข้อโต้แย้งระดับประโยคสำหรับหัวข้อท่าทางและแง่มุมที่กำหนด เรากำหนดมุมมองด้านอาร์กิวเมนต์เป็นวิธีที่จำเป็นในการอนุญาตให้มีการควบคุมอย่างละเอียดและ crowdsource ชุดข้อมูลที่มี 5,032 อาร์กิวเมนต์มีคำอธิบายประกอบด้วยแง่มุม เราปล่อยชุดข้อมูลนี้รวมถึงข้อมูลการฝึกอบรมสำหรับโมเดลการสร้างอาร์กิวเมนต์น้ำหนักและอาร์กิวเมนต์ที่สร้างขึ้นด้วยโมเดล
รูปต่อไปนี้แสดงให้เห็นว่ารูปแบบการสร้างอาร์กิวเมนต์ได้รับการฝึกฝนอย่างไร:
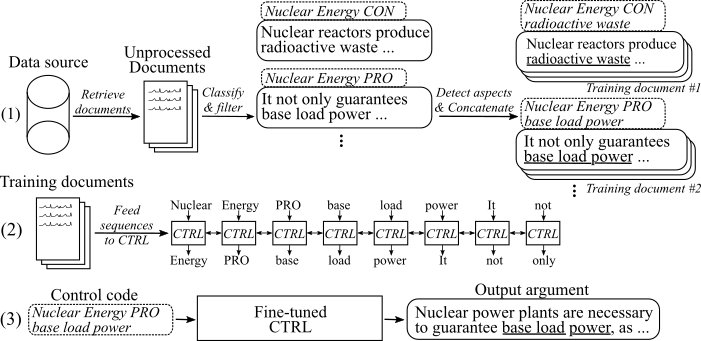
(1) เรารวบรวมเอกสารหลายล้านเอกสารสำหรับแปดหัวข้อที่แตกต่างกันจากแหล่งข้อมูลขนาดใหญ่สองแหล่ง ประโยคทั้งหมดถูกจัดประเภทเป็นโปร-และไม่ใช่ข้อโต้แย้ง เราตรวจพบแง่มุมของข้อโต้แย้งทั้งหมดด้วยแบบจำลองที่ได้รับการฝึกฝนในชุดข้อมูลใหม่และข้อโต้แย้งที่เชื่อมต่อกับหัวข้อท่าทางและแง่มุมเดียวกันในเอกสารการฝึกอบรม (2) เราใช้ข้อมูลที่จำแนกที่รวบรวมไว้เพื่อกำหนดเงื่อนไขโมเดล CTRL ในหัวข้อสถานการณ์และแง่มุมของข้อโต้แย้งที่รวบรวมทั้งหมด (3) ที่การอนุมานการผ่านรหัสควบคุม [หัวข้อ] [Stance] [มุมมอง] จะสร้างอาร์กิวเมนต์ที่ตามคำสั่งเหล่านี้
15. พฤษภาคม 2563
เราได้เพิ่มรหัสสำหรับโมเดลการสร้างอาร์กิวเมนต์ระบบประสาทที่ควบคุมโดยด้านและคำอธิบายของ Detailled เกี่ยวกับวิธีการใช้งาน โมเดลและรหัสแก้ไขงานโดย Keskar และคณะ (2019) ลิงค์ไปยังน้ำหนักรุ่นที่ปรับแต่งและข้อมูลการฝึกอบรมสามารถพบได้ในส่วนดาวน์โหลด
8. พฤษภาคม 2020
ชุดข้อมูล การตรวจจับอาร์กิวเมนต์ สามารถดาวน์โหลดได้จากที่นี่ ( argion_aspect_detection_v1.0.7z ) จากตรงนั้นคุณยังสามารถดาวน์โหลดอาร์กิวเมนต์ที่สร้างขึ้นด้วยโมเดลการสร้างอาร์กิวเมนต์ ( generated_arguments.7z ) และข้อมูลเพื่อสร้างการปรับแต่งแบบจำลองการสร้างอาร์กิวเมนต์ ( reddit_training_data.7z , cc_training_data.7z )
หมายเหตุ : เนื่องจากเหตุผลใบอนุญาตไฟล์เหล่านี้ไม่สามารถแจกจ่ายได้อย่างอิสระ การคลิกที่ไฟล์ใด ๆ จะเปลี่ยนเส้นทางคุณไปยังแบบฟอร์มซึ่งคุณต้องปล่อยให้ชื่อและอีเมลของคุณ หลังจากส่งแบบฟอร์มคุณจะได้รับลิงค์ดาวน์โหลดในไม่ช้า
ดาวน์โหลดชุดข้อมูลจากที่นี่ คุณสามารถดาวน์โหลดไฟล์ต่อไปนี้:
หมายเหตุ : เนื่องจากเหตุผลใบอนุญาตไฟล์เหล่านี้ไม่สามารถแจกจ่ายได้อย่างอิสระ การคลิกที่ไฟล์ใด ๆ จะเปลี่ยนเส้นทางคุณไปยังแบบฟอร์มซึ่งคุณต้องปล่อยให้ชื่อและอีเมลของคุณ หลังจากส่งแบบฟอร์มคุณจะได้รับลิงค์ดาวน์โหลดในไม่ช้า
ใช้ สคริปต์/download_weights.sh เพื่อดาวน์โหลดน้ำหนักรุ่น สคริปต์จะดาวน์โหลดน้ำหนักสำหรับโมเดลที่ปรับแต่งบน reddit-comments และข้อมูลการรวบรวมข้อมูลทั่วไปและปลดปล่อยพวกเขาลงในโฟลเดอร์โครงการหลัก
รหัสถูกทดสอบด้วย Python3.6 ติดตั้งข้อกำหนดทั้งหมดด้วย
pip install -r requirements.txt
และทำตามคำแนะนำใน readme ดั้งเดิมที่ การใช้งาน ขั้นตอนที่ 1 และ 2
ในต่อไปนี้เราอธิบายสามวิธีในการใช้รูปแบบการสร้างอาร์กิวเมนต์ประสาทที่ควบคุมโดยด้าน:
A. ใช้โมเดลสำหรับรุ่นเท่านั้น
B. ใช้ข้อมูลการฝึกอบรมที่มีอยู่เพื่อทำซ้ำ/ปรับแต่งโมเดล
C. ใช้ข้อมูลของคุณเองเพื่อปรับแต่งรูปแบบการสร้างอาร์กิวเมนต์ประสาทแบบใหม่
ในการสร้างอาร์กิวเมนต์โปรดดาวน์โหลดน้ำหนักสำหรับรุ่นก่อน (ดาวน์โหลดสคริปต์ที่ Scripts/download_weights.sh ) เรียกใช้โมเดลผ่าน python generation.py --model_dir reddit_seqlen256_v1 สำหรับรุ่นที่ผ่านการฝึกอบรมเกี่ยวกับข้อมูล reddit-comments หรือ python generation.py --model_dir cc_seqlen256_v1 สำหรับแบบจำลองที่ผ่านการฝึก หลังจากการโหลดเสร็จสมบูรณ์ให้พิมพ์รหัสควบคุมเช่น nuclear energy CON waste เพื่อสร้างอาร์กิวเมนต์ที่เป็นไปตามรหัสควบคุมนี้ เพื่อให้ได้ผลลัพธ์ที่ดีขึ้นสำหรับอาร์กิวเมนต์ที่สร้างขึ้นครั้งแรกคุณสามารถจบรหัสควบคุมด้วยระยะเวลาหรือลำไส้ใหญ่ ("." หรือ ":") สำหรับรายละเอียดเพิ่มเติมโปรดดูที่กระดาษ
หมายเหตุ : รหัสควบคุมที่อนุญาตสำหรับแต่ละหัวข้อและแหล่งข้อมูลสามารถพบได้ในโฟลเดอร์ Training_Data
เพื่อปรับแต่งโมเดลอย่างละเอียดตามที่เราได้ทำในงานของเราโปรดทำตามขั้นตอนเหล่านี้:
ดาวน์โหลดน้ำหนักที่ได้รับการฝึกอบรมล่วงหน้าจากกระดาษต้นฉบับ (readme ต้นฉบับที่ การใช้งาน ขั้นตอนที่ 3 )
ดาวน์โหลดข้อมูล การ ฝึกอบรม (ดูส่วนดาวน์โหลดคุณต้องใช้ไฟล์ reddit_training_data.7z หรือ cc_training_data.7z . redals.
7za x [FILENAME].7z
ในการทำซ้ำเอกสารการฝึกอบรมเดียวกันจากข้อมูลการฝึกอบรมในขณะที่เราใช้สำหรับการปรับแต่งโปรดใช้สคริปต์ที่ Training_utils/Pipeline/PREPEL_DOCUMENTS_ALL.SH และปรับพารามิเตอร์ ดัชนี การสร้างเอกสารการฝึกอบรมอาจใช้เวลาหนึ่งชั่วโมงหรือมากกว่านั้นในการคำนวณขึ้นอยู่กับฮาร์ดแวร์ของคุณ
สุดท้ายต้องสร้าง Tfrecords จากเอกสารการฝึกอบรมทั้งหมด ในการทำเช่นนั้นโปรดเรียกใช้:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[โฟลเดอร์] จำเป็นต้องชี้ไปที่โฟลเดอร์ของเอกสารการฝึกอบรมเช่น การฝึกอบรม _data/common-crawl-en/การทำแท้ง/สุดท้าย/ หลังจากสร้างจำนวนลำดับการฝึกอบรมที่สร้างขึ้นสำหรับหัวข้อเฉพาะนี้จะถูกพิมพ์ ใช้สิ่งนี้เพื่อกำหนดจำนวนขั้นตอนที่โมเดลควรได้รับการฝึกอบรม tfrecords จะถูกเก็บไว้ใน การฝึกอบรม โฟลเดอร์ _utils
ฝึกอบรมแบบจำลอง:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
โมเดลใช้ TFRECORDS ที่สร้างขึ้นโดยอัตโนมัติจากโฟลเดอร์ Training_UTILS โปรดทราบว่าน้ำหนักใน [โฟลเดอร์น้ำหนัก] จะถูกเขียนทับ สำหรับรุ่นที่มีโมเดลที่ปรับแต่งใหม่ให้ทำตามคำแนะนำใน " A. use model for Generation เท่านั้น "
เพื่อลดขั้นตอนการรวบรวมข้อมูลการฝึกอบรมของคุณเองเราเพิ่มการใช้งานไปป์ไลน์ของเราที่อธิบายไว้ในสิ่งพิมพ์ของเรา (ดู I. ใช้ไปป์ไลน์ของเรา ในการติดฉลากประโยคเป็นอาร์กิวเมนต์และเพื่อระบุสถานการณ์และแง่มุมของพวกเขาเราใช้ ArgumentExt-API หรือคุณสามารถฝึกอบรมโมเดลของคุณเอง (ดูที่ ii. สร้างไปป์ไลน์ของคุณเอง (โดยไม่ต้องโต้แย้ง API))
โปรดขอ userId และ Apikey สำหรับ argverText-API เขียนทั้ง ID และคีย์ในค่าคงที่ที่ การฝึกอบรม _utils/pipeline/credentials.py
เป็นขั้นตอนแรกต้องรวบรวมเอกสารการฝึกอบรมสำหรับหัวข้อที่น่าสนใจ ( หมายเหตุ: ขั้นตอนนี้ไม่ได้เป็นส่วนหนึ่งของรหัสและจะต้องมีการละทิ้งตัวเอง ) เราทำเช่นนั้นโดยการดาวน์โหลดการถ่ายโอนข้อมูลจาก Common-Crawl และ Reddit-comments และจัดทำดัชนีด้วย Elasticsearch ผลลัพธ์จะต้องเป็นเอกสารที่เก็บไว้ที่ training_data/[index_name]/[topic_name]/unprocess/ , โดยที่ [index_name] เป็นชื่อของแหล่งข้อมูล (เช่น Common-crawl-en ) และ [หัวข้อ _name] เป็นหัวข้อการค้นหาที่รวบรวมเอกสาร เอกสารแต่ละฉบับเป็นไฟล์ JSON แยกต่างหากโดยมีคีย์ "sents" อย่างน้อยซึ่งถือรายการประโยคจากเอกสารนี้:
{
"sents": ["sentence #1", "sentence #2", ...]
}
การ โต้แย้ง _classification.py นำเอกสารทั้งหมดที่รวบรวมไว้สำหรับหัวข้อที่กำหนดและจัดประเภทประโยคของพวกเขาเป็นโปร-/con-/non-arguments คำสั่งต่อไปนี้เริ่มการจำแนกประเภท:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
ที่ไม่ได้รับการโต้แย้งจะถูกยกเลิกและอาร์กิวเมนต์ที่จำแนกขั้นสุดท้ายจะถูกเก็บไว้ในไฟล์ที่มีอาร์กิวเมนต์สูงสุด 200,000 ข้อแต่ละที่ การฝึกอบรม _data/[index_name]/[topic_name]/ประมวลผล/
APASION_DETECTION.PY แยกวิเคราะห์ข้อโต้แย้งที่จัดประเภทก่อนหน้านี้ทั้งหมดและตรวจจับแง่มุมของพวกเขา คำสั่งต่อไปนี้เริ่มการตรวจจับด้าน:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
อาร์กิวเมนต์ทั้งหมดที่มีแง่มุมของพวกเขาจะถูกเก็บไว้ในไฟล์เดียว ที่รวมเข้าด้วยกัน jsonl ที่ training_data /[index_name]/[topic_name]/ประมวลผล/
prepay_documents.py ผนวกข้อโต้แย้งทั้งหมดที่มีหัวข้อเดียวกันท่าทางและ (ลำต้น) ไปยังเอกสารการฝึกอบรม:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[MAX_SENTS] ตั้งค่าจำนวนอาร์กิวเมนต์สูงสุดที่จะใช้ (การเบี่ยงเบนอย่างสม่ำเสมอระหว่างอาร์กิวเมนต์ PRO และ CON ถ้าเป็นไปได้) และ [min_aspect_cluster_size]/[max_aspect_cluster_size] ตั้งค่าอาร์กิวเมนต์ขั้นต่ำ/สูงสุดเพื่อผนวกเอกสารการฝึกอบรมเดียว เอกสารสุดท้ายจะถูกเก็บไว้ใน Folder Training_data/[index_name]/[topic_name]/final/ สคริปต์ PREPAL_ALL_DOCUMENTS.SH สามารถใช้เพื่อทำให้กระบวนการอัตโนมัติ
ในที่สุดเพื่อสร้างลำดับการฝึกอบรมจากเอกสารและเริ่มปรับแต่งโมเดลได้โปรดดาวน์โหลดน้ำหนักที่ปรับแต่งของเรา (ดูส่วนดาวน์โหลด) และติดตาม B. ใช้ข้อมูลการฝึกอบรมที่ได้รับเพื่อทำซ้ำ/ปรับแต่งโมเดลขั้นตอนที่ 4-5
สำคัญ : นอกเหนือจากเอกสารการฝึกอบรมไฟล์ที่มีรหัสควบคุมทั้งหมดตามเอกสารการฝึกอบรมถูกสร้างขึ้นที่ การฝึกอบรม _data/[index_name]/[topic_name] /generation_data/control_codes.jsonl ไฟล์นี้มีรหัสควบคุมทั้งหมดเพื่อสร้างอาร์กิวเมนต์จากการปรับแต่งเสร็จแล้ว
ในการฝึกอบรมรูปแบบการโต้แย้งและการจำแนกท่าทางคุณสามารถใช้คลังข้อมูล UKP และแบบจำลองที่อธิบายไว้ในสิ่งพิมพ์ที่สอดคล้องกันโดย Stab et al (2018) อย่างไรก็ตามเพื่อผลลัพธ์ที่ดีกว่าเราขอแนะนำให้ใช้ Bert (Devlin et al., 2019)
ในการฝึกอบรมรูปแบบการตรวจจับด้านโปรดดาวน์โหลดชุดข้อมูลการตรวจจับอาร์กิวเมนต์ของเรา (เนื่องจากเหตุผลใบอนุญาตจำเป็นต้องกรอกชื่อและอีเมลของคุณ) ในฐานะนางแบบเราขอแนะนำ Bert จาก HuggingFace สำหรับการติดแท็กลำดับ
เพื่อเตรียมเอกสารการฝึกอบรมและปรับแต่งแบบจำลองคุณสามารถใช้ prepay_documents.py ตามที่อธิบายไว้ใน I. ใช้ไปป์ไลน์ของเรา (พร้อมอาร์กิวเมนต์ API), ขั้นตอน d หากคุณเก็บข้อมูลที่จำแนกไว้ในรูปแบบต่อไปนี้:
ไฟล์ควรได้รับการตั้งชื่อว่า merged.jsonl และอยู่ในไดเรกทอรี การฝึกอบรม _data/[index_name]/[topic_name]/ประมวลผล/ โดยที่ [index_name] เป็นแหล่งข้อมูลจากที่รวบรวมตัวอย่างและ [topic_name] ชื่อของตัวค้นหาการค้นหาที่เกี่ยวข้องสำหรับข้อมูลนี้
แต่ละบรรทัดแสดงตัวอย่างการฝึกอบรมในรูปแบบต่อไปนี้:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
หากคุณพบว่างานนี้มีประโยชน์โปรดอ้างถึงการสร้างข้อโต้แย้งทางประสาทที่ควบคุมโดยด้านสิ่งพิมพ์ของเรา:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
ผู้ติดต่อ: เบนจามินชิลเลอร์
https://www.ukp.tu-darmstadt.de/


