controlled argument generation
1.0.0
Repositori yang menyertainya untuk generasi argumen saraf yang dikendalikan aspek.
Kami mengandalkan argumen dalam kehidupan sehari -hari kami untuk memberikan pendapat kami dan mendasarkannya pada bukti, membuat mereka lebih meyakinkan pada gilirannya. Namun, menemukan dan merumuskan argumen bisa menjadi tantangan. Untuk mengatasi tantangan ini, kami melatih model bahasa (berdasarkan CTRL oleh Keskar et al. (2019)) untuk generasi argumen yang dapat dikontrol pada tingkat berbutir halus untuk menghasilkan argumen tingkat kalimat untuk topik, sikap, dan aspek tertentu. Kami mendefinisikan deteksi aspek argumen sebagai metode yang diperlukan untuk memungkinkan kontrol granular halus ini dan crowdsource dataset dengan 5.032 argumen yang dianotasi dengan aspek. Kami merilis dataset ini, serta data pelatihan untuk model pembuatan argumen, bobotnya, dan argumen yang dihasilkan dengan model.
Gambar berikut menunjukkan bagaimana model generasi argumen dilatih:
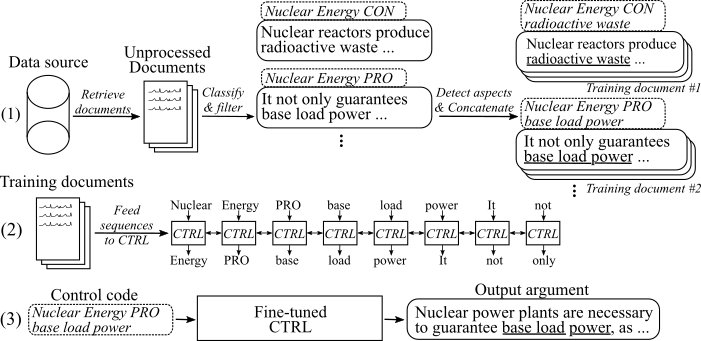
(1) Kami mengumpulkan beberapa juta dokumen untuk delapan topik berbeda dari dua sumber data besar. Semua kalimat diklasifikasikan ke dalam pro, con, dan non-argumen. Kami mendeteksi aspek semua argumen dengan model yang dilatih pada dataset baru dan argumen menggabungkan dengan topik, sikap, dan aspek yang sama ke dalam dokumen pelatihan. (2) Kami menggunakan data rahasia yang dikumpulkan untuk mengkondisikan model CTRL pada topik, sikap, dan aspek dari semua argumen yang dikumpulkan. (3) Pada inferensi, meneruskan kode kontrol [topik] [sikap] [aspek] akan menghasilkan argumen yang mengikuti perintah ini.
15. Mei 2020
Kami telah menambahkan kode untuk model generasi argumen saraf yang dikendalikan aspek dan deskripsi detaat tentang cara menggunakannya. Model dan kode memodifikasi pekerjaan oleh Keskar et al. (2019). Tautan ke bobot model yang disempurnakan dan data pelatihan dapat ditemukan di bagian unduhan.
8. Mei 2020
Dataset deteksi aspek argumen dapat diunduh dari sini ( argument_aspect_detection_v1.0.7z ). Dari sana, Anda juga dapat mengunduh argumen yang dihasilkan dengan model generasi argumen ( dihasilkan_arguments.7z ) dan data untuk mereproduksi penyesuaian model generasi argumen ( reddit_training_data.7z , cc_training_data.7z ).
Catatan : Karena alasan lisensi, file -file ini tidak dapat didistribusikan secara bebas. Mengklik salah satu file akan mengarahkan Anda ke formulir, di mana Anda harus meninggalkan nama dan email Anda. Setelah mengirimkan formulir, Anda akan segera menerima tautan unduhan.
Unduh set data dari sini. Anda dapat mengunduh file berikut:
Catatan : Karena alasan lisensi, file -file ini tidak dapat didistribusikan secara bebas. Mengklik salah satu file akan mengarahkan Anda ke formulir, di mana Anda harus meninggalkan nama dan email Anda. Setelah mengirimkan formulir, Anda akan segera menerima tautan unduhan.
Gunakan skrip/download_weights.sh untuk mengunduh bobot model. Script akan mengunduh bobot untuk model yang disesuaikan dengan komentar-reddit dan data crawl umum dan membuka ritsletingnya ke folder proyek utama.
Kode ini diuji dengan Python3.6 . Pasang semua persyaratan dengan
pip install -r requirements.txt
dan ikuti instruksi dalam readme asli saat penggunaan , langkah 1 dan 2 .
Berikut ini, kami menggambarkan tiga pendekatan untuk menggunakan model generasi argumen saraf yang dikendalikan aspek:
A. Gunakan model hanya untuk generasi
B. Gunakan data pelatihan yang tersedia untuk mereproduksi/menyempurnakan model
C. Gunakan data Anda sendiri untuk menyempurnakan model generasi argumen saraf yang dikendalikan aspek baru
Untuk menghasilkan argumen, silakan unduh bobot untuk model (unduh skrip di skrip/download_weights.sh ). Jalankan model melalui python generation.py --model_dir reddit_seqlen256_v1 untuk model yang dilatih pada data reddit-comments atau python generation.py --model_dir cc_seqlen256_v1 untuk model yang dilatih pada data badai umum. Setelah pemuatan selesai, ketik dalam kode kontrol, misalnya nuclear energy CON waste , untuk menghasilkan argumen yang mengikuti kode kontrol ini. Untuk mendapatkan hasil yang lebih baik untuk argumen yang dihasilkan pertama, Anda dapat mengakhiri kode kontrol dengan periode atau usus besar ("." Atau ":"). Untuk detail lebih lanjut, silakan merujuk ke kertas.
Catatan : Kode kontrol yang diizinkan untuk setiap topik dan sumber data dapat ditemukan di folder pelatihan_data .
Untuk menyempurnakan model seperti yang telah kami lakukan dalam pekerjaan kami, silakan ikuti langkah-langkah ini:
Unduh bobot terlatih dari kertas asli (ReadMe asli saat penggunaan , Langkah 3 ).
Download the training data (see Downloads section. You need the file reddit_training_data.7z or cc_training_data.7z . Depending on the source (cc or reddit), put the archives either into folder training_data/common-crawl-en/ or training_data/redditcomments-en/ and unzip via:
7za x [FILENAME].7z
Untuk mereproduksi dokumen pelatihan yang sama dari data pelatihan seperti yang kami gunakan untuk menyempurnakan, silakan gunakan skrip di pelatihan_utils/pipa/persiapan_documents_all.sh dan mengadaptasi parameter indeks . Bergantung pada perangkat keras Anda, pembuatan dokumen pelatihan dapat memakan waktu satu jam atau lebih untuk dihitung.
Terakhir, Tfrecords perlu dihasilkan dari semua dokumen pelatihan. Untuk melakukannya, silakan jalankan:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Folder] perlu menunjuk ke folder dokumen pelatihan, misalnya pelatihan_data/common-crawl-en/aborsi/final/ . Setelah menghasilkan, jumlah urutan pelatihan yang dihasilkan untuk topik khusus ini dicetak. Gunakan ini untuk menentukan jumlah langkah model harus dilatih. TFRECORD disimpan dalam folder pelatihan_utils .
Latih modelnya:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
Model mengambil TFRECORD yang dihasilkan secara otomatis dari folder pelatihan_utils . Harap dicatat bahwa bobot di [folder bobot] akan ditimpa. Untuk generasi dengan model yang baru disempurnakan, ikuti instruksi dalam " A. Gunakan model hanya untuk generasi ".
Untuk memudahkan proses mengumpulkan data pelatihan Anda sendiri, kami menambahkan implementasi pipa yang dijelaskan dalam publikasi kami (lihat I. Gunakan pipa kami (dengan API Argumentext)). Untuk memberi label kalimat sebagai argumen dan untuk mengidentifikasi sikap dan aspek mereka, kami menggunakan Argumentext-API. Atau, Anda juga dapat melatih model Anda sendiri (lihat II. Buat pipa Anda sendiri (tanpa Argumentext API)).
Silakan minta userid dan apikey untuk argumentext-api. Tulis ID dan kunci dalam konstanta masing -masing di pelatihan_utils/pipa/kredensial.py .
Sebagai langkah pertama, dokumen pelatihan untuk topik yang menarik perlu dikumpulkan. ( Catatan: Langkah ini bukan bagian dari kode dan harus diimplent sendiri ). Kami melakukannya dengan mengunduh dump dari common-crawl dan reddit-datang dan mengindeksnya dengan Elasticsearch. Hasilnya perlu dokumen yang disimpan di pelatihan_data/[index_name]/[topic_name]/tidak diproses/ , di mana [index_name] adalah nama sumber data (misalnya common-crawl-en) dan [Topic_name] adalah topik pencarian yang dikumpulkan oleh dokumen (ganti whitespaces di whitespaces di [Index_Name] dan Topik yang dikumpulkan oleh Dokumen (REPAGA RACHESPACE DI [INDEX_NAME] dan Topik yang dikumpulkan (NNCERS NAMA DAN REPACI WHITESPACE DI [INDEX_NAME] dan Topik yang dikumpulkan (REPACERESPACES DI [INDEX_NAME] dan Topik yang dikumpulkan (NNCERSNES DI INDEX_NAME). Setiap dokumen adalah file JSON terpisah dengan setidaknya "Sents" kunci yang memegang daftar kalimat dari dokumen ini:
{
"sents": ["sentence #1", "sentence #2", ...]
}
Argument_classification.py mengambil semua dokumen yang dikumpulkan untuk topik yang diberikan dan mengklasifikasikan kalimat mereka menjadi pro-/con/non-argumen. Perintah berikut memulai klasifikasi:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Non-argumen dibuang dan argumen rahasia akhir disimpan ke dalam file dengan maksimum 200.000 argumen masing-masing di pelatihan_data/[index_name]/[topic_name]/diproses/ .
Aspek_detection.py parse semua argumen yang sebelumnya diklasifikasikan dan mendeteksi aspek mereka. Perintah berikut memulai deteksi aspek:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Semua argumen dengan aspek mereka kemudian disimpan ke dalam satu file gabungan.jsonl di pelatihan_data /[index_name]/[topic_name]/diproses/.
The Prepar_Documents.py menambahkan semua argumen yang memiliki topik, sikap, dan aspek (berasal) yang sama dengan dokumen pelatihan:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[MAX_SENTS] Menetapkan jumlah maksimum argumen untuk digunakan (meresap secara merata antara argumen Pro dan CON jika memungkinkan) dan [min_aspect_cluster_size]/[max_aspect_cluster_size] menetapkan jumlah argumen min/maks yang diizinkan untuk ditambahkan untuk satu dokumen pelatihan tunggal. Dokumen akhir disimpan di folder pelatihan_data/[index_name]/[topic_name]/final/ . Script prepar_all_documents.sh dapat digunakan untuk mengotomatisasi proses.
Akhirnya, untuk membuat urutan pelatihan dari dokumen dan mulai menyempurnakan model, silakan unduh bobot fine-tuned kami (lihat bagian unduhan) dan ikuti B. Gunakan data pelatihan yang diberikan untuk mereproduksi/menyempurnakan model, langkah 4-5.
Penting : Selain dokumen pelatihan, file dengan semua kode kontrol berdasarkan dokumen pelatihan dibuat di pelatihan_data/[index_name]/[topic_name] /generation_data/control_codes.jsonl . File ini menyimpan semua kode kontrol untuk menghasilkan argumen dari setelah penyempurnaan telah selesai.
Untuk melatih model klasifikasi argumen dan sikap, Anda dapat menggunakan corpus UKP dan model yang dijelaskan dalam publikasi yang sesuai oleh Stab et al. (2018). Namun, untuk hasil yang lebih baik, kami menyarankan untuk menggunakan Bert (Devlin et al., 2019).
Untuk melatih model deteksi aspek, silakan unduh dataset deteksi aspek argumen kami (karena alasan lisensi, perlu untuk mengisi formulir dengan nama dan email Anda). Sebagai model, kami menyarankan Bert dari Huggingface untuk penandaan urutan.
Untuk menyiapkan dokumen pelatihan dan menyempurnakan model, Anda dapat menggunakan prepar_documents.py seperti yang dijelaskan dalam I. Gunakan pipa kami (dengan API Argumentext), langkah d. Jika Anda menyimpan data rahasia Anda dalam format berikut:
File harus dinamai gabungan.jsonl dan terletak di direktori pelatihan_data/[index_name]/[topic_name]/diproses/ , di mana [index_name] adalah sumber data dari tempat sampel dikumpulkan dan [topic_name] nama masing -masing permintaan pencarian untuk data ini.
Setiap baris mewakili sampel pelatihan dalam format berikut:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Jika Anda menemukan pekerjaan ini bermanfaat, silakan kutip generasi argumen saraf yang dikendalikan aspek publikasi kami:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Kontak Orang: Benjamin Schiller
https://www.ukp.tu-darmstadt.de/


