controlled argument generation
1.0.0
Begleitendes Repository für die Papieraspekt-kontrollierte neuronale Argumentationserzeugung.
Wir verlassen uns auf Argumente in unserem täglichen Leben, um unsere Meinungen abzugeben und sie auf Beweise zu stützen, was sie wiederum überzeugender machen. Es kann jedoch eine Herausforderung sein, Argumente zu finden und zu formulieren. Um diese Herausforderung anzugehen, haben wir ein Sprachmodell (basierend auf der Strg von Keskar et al. (2019)) für die Argumentation geschult, die auf feinkörniger Ebene kontrolliert werden kann, um Argumente auf Satzebene für ein bestimmtes Thema, Haltung und Aspekt zu generieren. Wir definieren die Erkennung von Argumentaspekten als eine notwendige Methode, um diese feine granuläre Kontrolle zu ermöglichen und einen Datensatz mit 5.032 Argumenten mit Aspekten zu ermöglichen. Wir veröffentlichen diesen Datensatz sowie die Trainingsdaten für das Argumentgenerierungsmodell, seine Gewichte und die mit dem Modell generierten Argumente.
Die folgende Abbildung zeigt, wie das Modell der Argumentationserzeugung geschult wurde:
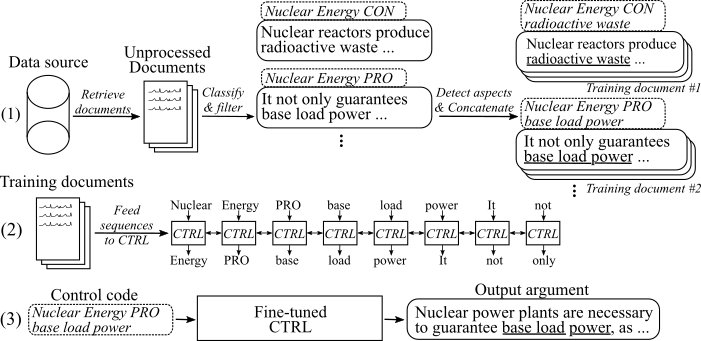
(1) Wir sammeln mehrere Millionen Dokumente für acht verschiedene Themen aus zwei großen Datenquellen. Alle Sätze werden in Pro-, Konsum- und Nicht-Argumente eingeteilt. Wir erkennen Aspekte aller Argumente mit einem Modell, das auf einem neuartigen Datensatz ausgebildet ist, und verkettet Argumente mit demselben Thema, der gleichen Haltung und dem gleichen Aspekt in Trainingsdokumente. (2) Wir verwenden die gesammelten klassifizierten Daten, um das Strg -Modell zu den Themen, Stellen und Aspekten aller gesammelten Argumente zu stennen. (3) Bei Inferenz erzeugt das Übergeben des Kontrollcode [Thema] [STANCE] [Aspekt] ein Argument, das diesen Befehlen folgt.
15. Mai 2020
Wir haben den Code für das von Aspekt kontrollierte Modell der neuronalen Argumentationserzeugung und den detaillierten Beschreibungen zum Gebrauch hinzugefügt. Das Modell und der Code verändern die Arbeit von Keskar et al. (2019). Der Link zu den fein abgestimmten Modellgewichten und Trainingsdaten finden Sie im Abschnitt Downloads.
8. Mai 2020
Der Argument -Aspekt -Erkennungsdatensatz kann von hier heruntergeladen werden ( Argument_aspect_detion_v1.0.7z ). Von dort aus können Sie auch die Argumente herunterladen, die mit den Argumentgenerierungsmodellen ( generated_arguments.7z ) und den Daten generiert wurden, um die Feinabstimmung des Argument-Erzeugungsmodells ( reddit_training_data.7z , cc_training_data.7z ) zu reproduzieren.
Hinweis : Aus Lizenzgründen können diese Dateien nicht frei verteilt werden. Wenn Sie auf eine der Dateien klicken, werden Sie in ein Formular umgeleitet, in dem Sie Ihren Namen und eine E -Mail hinterlassen müssen. Nach dem Einreichen des Formulars erhalten Sie in Kürze einen Download -Link.
Laden Sie hier Datensätze herunter. Sie können die folgenden Dateien herunterladen:
Hinweis : Aus Lizenzgründen können diese Dateien nicht frei verteilt werden. Wenn Sie auf eine der Dateien klicken, werden Sie in ein Formular umgeleitet, in dem Sie Ihren Namen und eine E -Mail hinterlassen müssen. Nach dem Einreichen des Formulars erhalten Sie in Kürze einen Download -Link.
Verwenden Sie Skripte/download_wways.sh, um die Modellgewichte herunterzuladen. Das Skript lädt die Gewichte für das Modell herunter, das auf Reddit-Comments und Common-Crawl-Daten abgestimmt ist und sie in den Hauptprojektordner entpackt.
Der Code wurde mit Python3.6 getestet. Installieren Sie alle Anforderungen mit
pip install -r requirements.txt
und befolgen Sie die Anweisungen im ursprünglichen Readme bei der Verwendung , Schritt 1 und 2 .
Im Folgenden beschreiben wir drei Ansätze, um das von Aspekt kontrollierte Modell der neuronalen Argumentation zu verwenden:
A. Verwenden Sie nur das Modell für die Generation
B. Verwenden Sie verfügbare Trainingsdaten, um das Modell zu reproduzieren/zu optimieren
C. verwenden
Um Argumente zu generieren, laden Sie bitte zunächst die Gewichte für die Modelle herunter (das Skript bei Skripten/Download_Weights.sh herunterladen). Führen Sie das Modell über python generation.py --model_dir reddit_seqlen256_v1 python generation.py --model_dir cc_seqlen256_v1 . Geben Sie nach Abschluss des Ladens einen Kontrollcode ein, nuclear energy CON waste . Um bessere Ergebnisse für das erste generierte Argument zu erzielen, können Sie den Kontrollcode mit einer Periode oder einem Dickdarm beenden (". Oder": "). Weitere Informationen finden Sie in der Zeitung.
HINWEIS : Erlaubte Steuercodes für jedes Thema und die Datenquelle finden Sie im Ordner "Training_Data" .
Um das Modell wie in unserer Arbeit zu optimieren, befolgen Sie die folgenden Schritte:
Laden Sie die vorgeborenen Gewichte aus dem Originalpapier herunter (Original Readme bei Verwendung , Schritt 3 ).
Laden Sie die Trainingsdaten herunter (siehe Abschnitt Downloads. Sie benötigen die Datei reddit_training_data.7z oder cc_training_data.7z . Abhängig von der Quelle (CC oder Reddit) geben Sie die Archive entweder in Ordner Training_Data/ Common-Crawl-EN/ oder Training_Data/ redditcomportment-n/ und unZiPIP-VIP:
7za x [FILENAME].7z
Um dieselben Trainingsdokumente aus den Trainingsdaten zu reproduzieren, wie wir für die Feinabstimmung verwendet wurden, verwenden Sie das Skript unter Training_utils/Pipeline/prepe_documents_all.sh und passen Sie den Indexparameter an. Abhängig von Ihrer Hardware kann die Erzeugung von Trainingsdokumenten eine Stunde oder länger dauern.
Zuletzt müssen TFFRECORDS aus allen Trainingsdokumenten generiert werden. Um dies zu tun, rennen Sie bitte:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Ordner] muss auf den Ordner der Trainingsdokumente, z. B. Training_Data/Common-Crawl-en/Abtreibung/Final/ . Nach der Erstellung wird die Anzahl der für dieses spezifischen Thema generierten Trainingssequenzen gedruckt. Verwenden Sie dies, um die Anzahl der Schritte zu bestimmen, auf denen das Modell trainiert werden sollte. Die TFFRECORDS werden in Ordner Training_utils gespeichert.
Trainieren Sie das Modell:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
Das Modell nimmt die generierten TFRecords automatisch aus dem Ordner "Training_utils" . Bitte beachten Sie, dass die Gewichte im [Gewichtsordner] überschrieben werden. Für die Generation mit dem neu fein abgestimmten Modell folgen Sie den Anweisungen in " A. Modell verwenden nur für die Generation ".
Um den Prozess des Sammelns Ihrer eigenen Trainingsdaten zu erleichtern, fügen wir unsere Umsetzung der in unserer Veröffentlichung beschriebenen Pipeline hinzu (siehe I. Nutze unserer Pipeline (mit Argumentext -API)). Um Sätze als Argumente zu kennzeichnen und ihre Haltung und Aspekte zu identifizieren, verwenden wir den Argumentext-API. Alternativ können Sie auch Ihre eigenen Modelle trainieren (siehe ii. Erstellen Sie Ihre eigene Pipeline (ohne Argumentext -API)).
Bitte fordern Sie eine BenutzerID und Apikey für das Argumentext-api an. Schreiben Sie sowohl ID als auch Schlüssel in den jeweiligen Konstanten unter Training_utils/Pipeline/Anmeldeinformationen.py .
Als erster Schritt müssen Schulungsdokumente für ein Thema von Interesse gesammelt werden. ( Hinweis: Dieser Schritt ist nicht Teil des Codes und muss selbst implentiert sein ). Wir haben dies geschafft, indem wir einen Müllkippe von Common-Crawl- und Reddit-Comments heruntergeladen und mit Elasticsearch indexiert haben. Das Ergebnis muss Dokumente sein, die bei Training_data/[index_name]/[topic_name]/unverarbeitet gespeichert werden, wobei [index_name] der Name der Datenquelle ist (z . Jedes Dokument ist ein separates JSON-File mit mindestens den Schlüssel "Sents", das eine Liste von Sätzen aus diesem Dokument enthält:
{
"sents": ["sentence #1", "sentence #2", ...]
}
Das Argument_Classification.py enthält alle für ein bestimmtes Thema gesammelten Dokumente und klassifiziert ihre Sätze in Pro-/Kon-/Nicht-Argumente. Der folgende Befehl startet die Klassifizierung:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Nicht-Argumente werden verworfen und die endgültigen klassifizierten Argumente werden in Dateien mit maximal 200.000 Argumenten gespeichert .
Der Aspekt_Detction.py analysiert alle zuvor klassifizierten Argumente und erkennt ihre Aspekte. Der folgende Befehl startet die Aspekterkennung:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Alle Argumente mit ihren Aspekten werden dann in eine einzelne Datei merged.jsonl unter Training_data /[index_name]/[topic_name]/verarbeitet/gespeichert.
Die prepe_documents.py wendet alle Argumente an, die den gleichen Thema, die gleiche Haltung und (Stemmed) in einem Trainingsdokument aufweisen:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[MAX_SENTS] legt die maximale Anzahl von Argumenten fest (gleichmäßig zwischen Pro und Con Argumenten zwischen Pro und Con Argumenten) und [min_aspespep_cluster_size]/[max_aspect_cluster_size] legt die min/max -Anzahl der zulässigen Argumente fest, die für ein einzelnes Trainingsdokument angelangt sind. Die endgültigen Dokumente werden in Ordner Training_Data/[index_name]/[topic_name]/final/ gespeichert. Das Skript prepe_all_documents.sh kann verwendet werden, um den Prozess zu automatisieren.
Um Schulungssequenzen aus den Dokumenten zu erstellen und das Modell mit der Feinabstimmung zu beginnen, laden Sie bitte unsere feinen Gewichte herunter (siehe Download-Abschnitt) und folgen Sie. Verwenden Sie die gegebenen Schulungsdaten, um das Modell zu reproduzieren/zu optimieren, Schritte 4-5.
Wichtig : Zusätzlich zu den Schulungsdokumenten wird eine Datei mit allen Kontrollcodes basierend auf den Schulungsdokumenten unter Training_Data/[index_name]/[topic_name] /generation_data/control_codes.jsonl erstellt. Diese Datei enthält alle Kontrollcodes, um Argumente nach Abschluss der Feinabstimmung zu generieren.
Um ein Argument- und Standklassifizierungsmodell auszubilden, können Sie den UKP -Korpus und die in der entsprechenden Veröffentlichung von Stab et al. (2018). Für bessere Ergebnisse schlagen wir jedoch vor, Bert zu verwenden (Devlin et al., 2019).
Um ein Aspekterkennungsmodell auszubilden, laden Sie bitte unseren Argument -Aspekt -Erkennungsdatensatz herunter (aus Lizenzgründen müssen das Formular mit Ihrem Namen und Ihrer E -Mail füllen). Als Modell empfehlen wir Bert vom Umarmungsface zum Sequenz -Tagging.
Um Schulungsdokumente vorzubereiten und das Modell zu optimieren, können Sie die in I. beschriebene Prepe_documents.py verwenden. Verwenden Sie unsere Pipeline (mit Argumentext-API), Schritt d. Wenn Sie Ihre klassifizierten Daten im folgenden Format aufbewahren:
Die Datei sollte merged.jsonl genannt werden und sich im Verzeichnistraining_Data/[index_name]/[topic_name]/verarbeitet/ , wobei [index_name] die Datenquelle aus der gesammelten Abtemperatur und [topic_name] Der Name der jeweiligen Suchanfrage für diese Daten ist.
Jede Zeile repräsentiert eine Trainingsprobe im folgenden Format:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Wenn Sie diese Arbeit hilfreich finden, zitieren Sie bitte unsere Veröffentlichungsaspekt-kontrollierte neuronale Argumentationserzeugung:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Kontaktperson: Benjamin Schiller
https://www.ukp.tu-darmstadt.de/


