controlled argument generation
1.0.0
Сопровождающее хранилище для бумажного, контролируемого аспектом, генерация нейронных аргументов.
Мы полагаемся на аргументы в нашей повседневной жизни, чтобы выдать наше мнение и основывать их на доказательствах, что делает их более убедительными. Однако поиск и формулирование аргументов может быть сложным. Чтобы решить эту проблему, мы обучили языковую модель (на основе CTRL Keskar et al. (2019)) для генерации аргументов, которую можно контролировать на мелкозернистом уровне для создания аргументов на уровне предложений для данной темы, позиции и аспекта. Мы определяем обнаружение аспектов аргумента как необходимый метод, позволяющий этому управлению тонким гранатом и краудсорсинга набора данных с 5 032 аргументами, аннотированными с аспектами. Мы выпускаем этот набор данных, а также учебные данные для модели генерации аргументов, его весов и аргументов, сгенерированных с моделью.
На следующем рисунке показано, как была обучена модель генерации аргументов:
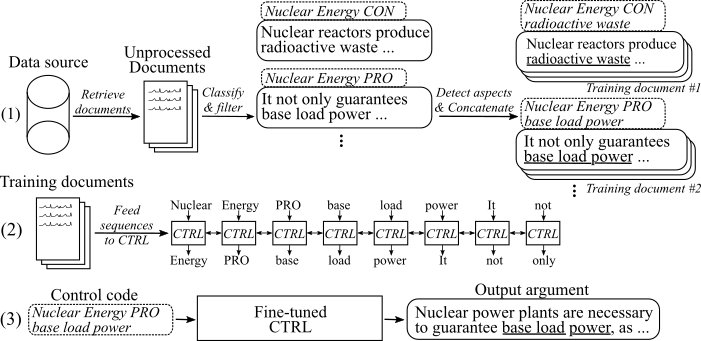
(1) Мы собираем несколько миллионов документов на восемь различных тем из двух больших источников данных. Все предложения классифицируются на про-, коннусовые и не аргументы. Мы обнаруживаем аспекты всех аргументов с моделью, обученной новым набором данных, и объединять аргументы с той же темой, позицией и аспектом в учебные документы. (2) Мы используем собранные классифицированные данные для обучения модели CTRL по темам, позициям и аспектам всех собранных аргументов. (3) При выводе, передавая код управления [Тема] [Стэйс] [Аспект] будет генерировать аргумент, который следует за этими командами.
15. май 2020
Мы добавили код для модели генерации нейронных аргументов, контролируемых аспектами, и определяли описания о том, как его использовать. Модель и код изменяют работу Keskar et al. (2019). Ссылка на тонко настроенные веса модели и учебные данные можно найти в разделе загрузки.
8. мая 2020 года
Набор данных об обнаружении аспекта аргумента может быть загружен отсюда ( Argent_aspect_detection_v1.0.7z ). Оттуда вы также можете загрузить аргументы, сгенерированные с помощью моделей генерации аргументов ( Generated_arguments.7Z ) и данных, чтобы воспроизвести точную настройку модели генерации аргументов ( REDDIT_TRAING_DATA.7Z , CC_TRAING_DATA.7Z ).
ПРИМЕЧАНИЕ . По причинам лицензии эти файлы не могут быть распределены свободно. Нажатие на любой из файлов перенаправляет вас в форму, где вы должны оставить свое имя и электронное письмо. После отправки формы вы скоро получите ссылку для загрузки.
Скачать наборы данных отсюда. Вы можете скачать следующие файлы:
ПРИМЕЧАНИЕ . По причинам лицензии эти файлы не могут быть распределены свободно. Нажатие на любой из файлов перенаправляет вас в форму, где вы должны оставить свое имя и электронное письмо. После отправки формы вы скоро получите ссылку для загрузки.
Используйте Scripts/Download_weights.sh для загрузки веса модели. Сценарий будет загружать веса для модели, настраиваемой на Reddit-Comments и обычных данных, и разкатывает их в основную папку проекта.
Код был протестирован с помощью Python3.6 . Установить все требования с
pip install -r requirements.txt
и следуйте инструкциям в оригинальном Readme при использовании , шаг 1 и 2 .
Далее мы описываем три подхода для использования модели генерации нейронных аргументов, контролируемых аспектами:
A. Используйте модель только для поколения
B. Используйте доступные учебные данные для воспроизведения/настройки модели
C. Используйте свои собственные данные для тонкой настройки новой модели генерации нейронных аргументов, контролируемых аспектами
Чтобы сгенерировать аргументы, сначала загрузите вес для моделей (скачать Script на Scripts/Download_weights.sh ). Запустите модель с помощью python generation.py --model_dir reddit_seqlen256_v1 для модели, обученной на данных Reddit-Comments или python generation.py --model_dir cc_seqlen256_v1 для модели, подготовленной по данным общего труда. После завершения загрузки введите код управления, например, nuclear energy CON waste , чтобы сгенерировать аргументы, которые следуют этому коду управления. Чтобы получить лучшие результаты для первого сгенерированного аргумента, вы можете закончить код управления с периодом или толстой кишкой ("." Или ":"). Для получения более подробной информации, пожалуйста, обратитесь к газете.
ПРИМЕЧАНИЕ . Разрешенные коды управления для каждой темы и источника данных можно найти в папке Training_Data .
Чтобы точно настроить модель, как мы делали в нашей работе, следуйте этим шагам:
Загрузите предварительно обученные веса из оригинальной статьи (оригинальная Readme при использовании , шаг 3 ).
Загрузите учебные данные (см . Раздел загрузки. Вам нужен файл REDDIT_TRAING_DATA.7Z или CC_TRAING_DATA.7Z .
7za x [FILENAME].7z
Чтобы воспроизвести те же учебные документы из учебных данных, которые мы использовали для точной настройки, используйте скрипт по адресу training_utils/pipeline/prepare_documents_all.sh и адаптируйте параметр индекса . В зависимости от вашего оборудования, генерация учебных документов может занять час или более для вычисления.
Наконец, Tfrecords необходимо генерировать из всех учебных документов. Для этого, пожалуйста, запустите:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[Папка] должна указывать на папку учебных документов, например , Training_data/Common-Crawl-en/Abort/Final/ . После генерации напечатано количество учебных последовательностей, сгенерированных для этой конкретной темы. Используйте это, чтобы определить количество шагов, на которые должна быть обучена модель. TFRECORDS хранятся в папке Training_Utils .
Обучить модель:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
Модель автоматически берет сгенерированные TFRECORDS из папки Training_Utils . Обратите внимание, что веса в [веса папки] будут перезаписаны. Для генерации с недавно настраиваемой моделью следуйте инструкциям « A. Используйте модель только для генерации ».
Чтобы облегчить процесс сбора ваших собственных данных обучения, мы добавляем нашу реализацию конвейера, описанного в нашей публикации (см. I. Используйте наш трубопровод (с API ArgiryExt)). Чтобы назвать предложения как аргументы и определить их позиции и аспекты, мы используем аргумент В качестве альтернативы, вы также можете тренировать свои собственные модели (см. II. Создайте свой собственный конвейер (без Argysext API)).
Пожалуйста, запросите пользовательский и Apikey для ArgiryExt-API. Напишите и ID и ключ в соответствующих констант по адресу training_utils/pipeline/credentials.py .
В качестве первого шага необходимо собрать учебные документы для интересующей темы. ( Примечание: этот шаг не является частью кода и должен быть самостоятельным ). Мы сделали это, загрузив дамп с Common-Cloul и Reddit-Comments и индексировав их с помощью Elasticsearch. Результат должен быть документами, которые хранятся по адресу training_data/[index_name]/[toma_name]/необработанное/ , где [index_name] является именем источника данных (например , общий ливень ), а [toma_name]-это тема поиска, для которой были собраны документы (замените пробелы в [Index_Name и [Topic_Name]. Каждый документ представляет собой отдельный JSON-файл, по крайней мере, с ключом «Sents», который содержит список предложений из этого документа:
{
"sents": ["sentence #1", "sentence #2", ...]
}
Armage_classification.py берет все документы, собранные для данной темы и классифицирует их предложения на Pro-/con-/non-arguments. Следующая команда начинает классификацию:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Неаргументы отбрасываются, и окончательные классифицированные аргументы хранятся в файлах с максимум 200 000 аргументов, каждый из которых по адресу training_data/[index_name]/[toma_name]/обработка/ .
Assoce_detection.py Saclses - все ранее классифицированные аргументы и обнаруживают их аспекты. Следующая команда начинает обнаружение аспекта:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
Все аргументы с их аспектами затем хранятся в одном файле Merged.jsonl At Training_data /[index_name]/[TOMA_NAME]/обработка/.
Prepare_Documents.py добавляет все аргументы, которые имеют одинаковую тему, позицию и (Stemmed) аспект к учебному документу:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[Max_sents] устанавливает максимальное количество аргументов, которые для использования (равномерно развязаны между аргументами Pro и Con, если это возможно), и [min_aspect_cluster_size]/[max_aspect_cluster_size] устанавливает количество Min/Max разрешенных аргументов для добавления для одного учебного документа. Окончательные документы хранятся в папке Training_data/[index_name]/[toma_name]/final/ . Script Prepare_all_documents.sh может использоваться для автоматизации процесса.
Наконец, чтобы создать обучающие последовательности из документов и начать точную настройку модели, пожалуйста, загрузите наши тонкие веса (см. Раздел загрузки) и следуйте B. Используйте данные обучающие данные для воспроизведения/настройки модели, шаги 4-5.
ВАЖНО : В дополнение к учебным документам файл со всеми контрольными кодами, основанными на учебных документах, создается по адресу training_data/[index_name]/[topic_name]/generation_data/control_codes.jsonl . Этот файл содержит все коды управления для генерации аргументов после окончания точной настройки.
Чтобы обучить модель аргумента и классификации позиций, вы можете использовать корпус UKP и модели, описанные в соответствующей публикации Stab et al. (2018). Однако для лучших результатов мы предлагаем использовать Bert (Devlin et al., 2019).
Чтобы обучить модель обнаружения аспектов, пожалуйста, загрузите наш набор данных об обнаружении аспекта аргумента (по причинам лицензии необходимо заполнить форму вашим именем и электронной почтой). Как модель, мы предлагаем Bert от Huggingface для тега последовательности.
Чтобы подготовить учебные документы и точно настроить модель, вы можете использовать Prepare_documents.py , как описано в I. Используйте наш конвейер (с ArgiryExt API), шаг d. Если вы сохраните свои классифицированные данные в следующем формате:
Файл должен быть назван merged.jsonl и расположен в Directory Training_data/[index_name]/[topic_name]/обработка/ , где [index_name] является источником данных, из которого были собраны выборки, и [topic_name] Имя соответствующего поискового запроса для этих данных.
Каждая строка представляет образец в следующем формате:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
Если вы обнаружите эту работу полезной, пожалуйста, сослатесь на нашу публикацию, контролируемое аспектом, генерация нейронных аргументов:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
Контактный человек: Бенджамин Шиллер
https://www.ukp.tu-darmstadt.de/


