controlled argument generation
1.0.0
논문 종자 제어 신경 인수 생성에 대한 리포지토리와 함께.
우리는 일상 생활에서 논쟁에 의존하여 의견을 전달하고 증거에 근거하여 차례로 설득력이 있습니다. 그러나 논쟁을 찾고 수립하는 것은 어려울 수 있습니다. 이 도전에 대처하기 위해, 우리는 주어진 주제, 자세 및 측면에 대한 문장 수준의 인수를 생성하기 위해 세밀한 수준으로 제어 될 수있는 인수 생성에 대한 언어 모델 (Keskar et al. (2019)의 CTRL 기반)을 훈련시켰다. 우리는 인수 측면 탐지를이 세밀하게 제어 할 수있는 필요한 방법으로 정의하고 측면과 주석이 달린 5,032 개의 인수로 데이터 세트를 크라우드 소싱합니다. 우리는이 데이터 세트와 인수 생성 모델, 가중치 및 모델로 생성 된 인수에 대한 교육 데이터를 공개합니다.
다음 그림은 인수 생성 모델이 어떻게 훈련되었는지를 보여줍니다.
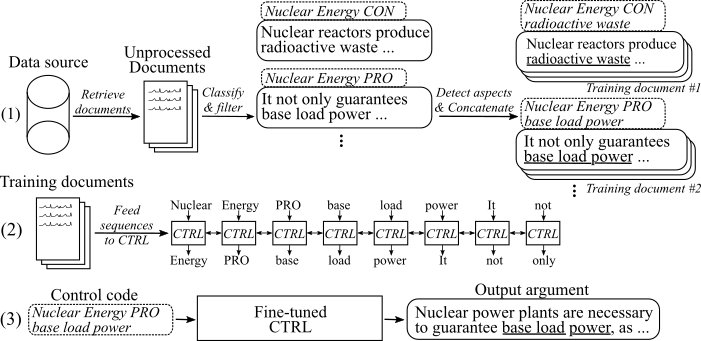
(1) 우리는 두 개의 큰 데이터 소스에서 8 개의 다른 주제에 대한 수백만 개의 문서를 수집합니다. 모든 문장은 예비, 불법 행위로 분류됩니다. 우리는 새로운 데이터 세트에 대한 교육을받은 모델로 모든 인수의 측면을 감지하고 동일한 주제, 자세 및 측면을 훈련 문서에 대한 논증을 연결합니다. (2) 수집 된 분류 데이터를 사용하여 수집 된 모든 인수의 주제, 자세 및 측면에 대한 CTRL 모델을 조정합니다. (3) 추론에 따르면, 제어 코드 [주제] [자세] [측면] 을 전달하면이 명령을 따르는 인수가 생성됩니다.
2020 년 5 월 15 일
우리는 측면 제어 신경 인수 생성 모델에 대한 코드와 그것을 사용하는 방법에 대한 설명을 추가했습니다. 모델과 코드는 Keskar et al. (2019). 미세 조정 된 모델 가중치 및 교육 데이터에 대한 링크는 다운로드 섹션에서 찾을 수 있습니다.
2020 년 5 월 8 일
인수 측면 감지 데이터 세트는 여기에서 다운로드 할 수 있습니다 ( argument_aspect_detection_v1.0.7z ). 여기에서 인수 생성 모델 ( Generated_arguments.7z )으로 생성 된 인수와 인수 생성 모델의 미세 조정 ( reddit_training_data.7z , cc_training_data.7z )으로 생성 된 인수를 다운로드 할 수 있습니다.
참고 : 라이센스 이유로 인해 이러한 파일을 자유롭게 배포 할 수 없습니다. 파일을 클릭하면 이름과 이메일을 남겨 두어야하는 양식으로 리디렉션됩니다. 양식을 제출 한 후 곧 다운로드 링크를 받게됩니다.
여기에서 데이터 세트를 다운로드하십시오. 다음 파일을 다운로드 할 수 있습니다.
참고 : 라이센스 이유로 인해 이러한 파일을 자유롭게 배포 할 수 없습니다. 파일을 클릭하면 이름과 이메일을 남겨 두어야하는 양식으로 리디렉션됩니다. 양식을 제출 한 후 곧 다운로드 링크를 받게됩니다.
Scripts/Download_weights.sh를 사용하여 모델 가중치를 다운로드하십시오. 이 스크립트는 Reddit-Comments 및 Common-Crawl 데이터에 미세 조정 된 모델의 가중치를 다운로드하여 기본 프로젝트 폴더로 압축합니다.
코드는 Python3.6 으로 테스트되었습니다. 모든 요구 사항을 설치하십시오
pip install -r requirements.txt
그리고 1 단계 및 2 단계 에서 원래 readme의 지침을 따르십시오.
다음에서, 우리는 측면 제어 신경 인수 생성 모델을 사용하기위한 세 가지 접근법을 설명합니다.
A. 생성에만 모델을 사용하십시오
B. 사용 가능한 교육 데이터를 사용하여 모델을 재현/미세 조정하십시오
C. 자신의 데이터를 사용하여 새로운 측면 제어 신경 인수 생성 모델을 미세 조정하십시오.
인수를 생성하려면 먼저 모델의 가중치를 다운로드하십시오 ( Scripts/Download_weights.sh 에서 스크립트 다운로드). python generation.py --model_dir reddit_seqlen256_v1 reddit-comments 데이터 또는 python generation.py --model_dir cc_seqlen256_v1 에 대해 공통 크롤링 데이터에 대해 훈련 된 모델에 대한 모델의 경우 모델. 로드가 완료되면 제어 코드 (예 : nuclear energy CON waste 같은 제어 코드를 입력 하여이 제어 코드를 따르는 인수를 생성하십시오. 첫 번째 생성 된 인수에 대한 더 나은 결과를 얻으려면 기간 또는 결장으로 제어 코드를 종료 할 수 있습니다 ( "."또는 ":"). 자세한 내용은 종이를 참조하십시오.
참고 : 각 주제에 대한 허용 된 제어 코드 및 데이터 소스는 Training_Data 폴더에서 찾을 수 있습니다.
작업에서 수행 한 것처럼 모델을 미세 조정하려면 다음을 수행하십시오.
원래 논문에서 미리 훈련 된 무게를 다운로드하십시오 ( 사용시 원본 읽기, 3 단계 ).
교육 데이터를 다운로드하십시오 (다운로드 섹션 참조. reddit_training_data.7z 또는 cc_training_data.7z 파일이 필요합니다. 소스 (cc 또는 reddit)에 따라 아카이브를 폴더 training/ common-crawl-en/ 또는 training_datata/ redditcomments-/ 및 unzip via에 넣으십시오.
7za x [FILENAME].7z
미세 조정에 사용한 것과 같은 교육 데이터에서 동일한 교육 문서를 재현하려면 Training_utils/Pipeline/Preparion_documents_all.sh 의 스크립트를 사용하고 인덱스 매개 변수를 조정하십시오. 하드웨어에 따라 교육 문서 생성을 계산하는 데 1 시간 이상이 걸릴 수 있습니다.
마지막으로, 모든 교육 문서에서 tfrecord를 생성해야합니다. 그렇게하려면 실행하십시오.
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[폴더]는 훈련 문서의 폴더 (예 : training_data/common-crawl-en/accort/final/) 를 가리켜 야합니다. 생성 후,이 특정 주제에 대해 생성 된 교육 시퀀스의 수가 인쇄됩니다. 이것을 사용하여 모델을 훈련시켜야 할 단계의 수를 결정하십시오. tfrecords는 폴더 training_utils 에 저장됩니다.
모델 훈련 :
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
이 모델은 Training_utils 폴더에서 생성 된 tfrecords를 자동으로 가져옵니다. [Weights Folder]의 가중치는 덮어 쓸 것입니다. 새로 미세 조정 된 모델을 사용한 생성의 경우 " A. Generation Only"를 사용하는 지침을 따르십시오.
자신의 교육 데이터를 수집하는 프로세스를 완화하기 위해 출판물에 설명 된 파이프 라인 구현을 추가합니다 (I 참조. 파이프 라인을 사용합니다 (ArgumentExt API). 문장을 인수로 표시하고 그들의 입장과 측면을 식별하기 위해 argumentext-api를 사용합니다. 또는 자신의 모델을 훈련시킬 수도 있습니다 (II. ArgumentExt API없이 자신의 파이프 라인 생성).
ArgumentExt-Api에 대해 userId 및 apikey를 요청하십시오. Training_utils/Pipeline/Credentials.py 에서 각 상수에 ID와 키를 모두 작성하십시오.
첫 번째 단계로, 관심 주제에 대한 교육 문서를 수집해야합니다. ( 참고 :이 단계는 코드의 일부가 아니며 자체 적합해야합니다 ). 우리는 Common-Crawl 및 Reddit-Comments에서 덤프를 다운로드하여 Elasticsearch로 색인화하여 그렇게했습니다. 결과는 training_data/[index_name]/[topic_name]/처리되지 않은/ , [index_name]이 데이터 소스 (예 : Common-Crawl-En )의 이름이며 [index_name]의 검색 주제 (Index_name] 및 [Topic_name]에 대한 검색 주제입니다. 각 문서는이 문서에서 문장 목록을 보유하는 최소한 "Sents"가있는 별도의 JSON-File입니다.
{
"sents": ["sentence #1", "sentence #2", ...]
}
argument_classification.py 는 주어진 주제에 대해 수집 된 모든 문서를 가져 와서 문장을 pro/con-/비과 구분으로 분류합니다. 다음 명령은 분류를 시작합니다.
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
비 관점이 폐기되고 최종 분류 된 인수는 각각 Training_Data/[index_name]/[topic_name]/processed/ 에서 최대 200,000 개의 인수가있는 파일에 저장됩니다.
Spect_Detection.py 는 이전에 분류 된 모든 인수를 구문 분석하고 해당 측면을 감지합니다. 다음 명령은 측면 감지를 시작합니다.
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
그런 다음 해당 측면이있는 모든 인수는 training_data /[index_name]/[topic_name]/processed/에서 단일 파일 병합 에 저장됩니다.
repay_documents.py 는 동일한 주제, 자세 및 (stemmed) 측면을 갖는 모든 인수를 훈련 문서에 추가합니다.
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
[max_sents]는 사용할 인수의 최대 수를 설정합니다 (가능하면 Pro와 Con 인수 사이에 균등하게 개발 됨) 및 [min_aspect_cluster_size]/[max_aspect_cluster_size] 단일 교육 문서에 대한 최소/max 수를 설정합니다. 최종 문서는 폴더 training_data/[index_name]/[topic_name]/final/ 에 저장됩니다. 스크립트 준비 _all_documents.sh는 프로세스를 자동화하는 데 사용할 수 있습니다.
마지막으로, 문서에서 교육 시퀀스를 만들고 모델을 미세 조정하기 위해 미세 조정 가중치를 다운로드하고 (다운로드 섹션 참조) BOFL
중요 : 교육 문서 외에도 교육 문서를 기반으로 모든 제어 코드가있는 파일은 training_data/[index_name]/[topic_name] /generation_data/control_codes.jsonl 에서 작성됩니다. 이 파일은 모든 제어 코드를 보유하여 미세 조정이 완료된 후 인수를 생성합니다.
인수 및 자세 분류 모델을 훈련시키기 위해 UKP 코퍼스와 STAB et al.의 해당 간행물에 설명 된 모델을 사용할 수 있습니다. (2018). 그러나 더 나은 결과를 얻으려면 Bert를 사용하는 것이 좋습니다 (Devlin et al., 2019).
Aspect Detection Model을 훈련 시키려면 인수 측면 감지 데이터 세트를 다운로드하십시오 (라이센스 이유로 인해 이름과 이메일로 양식을 채워야합니다). 모델로서, 우리는 서열 태깅을 위해 포옹 페이스의 Bert를 제안합니다.
교육 문서를 준비하고 모델을 미세 조정하려면 I에 설명 된대로 repay_documents.py 를 사용할 수 있습니다. 파이프 라인 (ArgumentExt API 포함), 단계 d. 분류 된 데이터를 다음 형식으로 유지하는 경우 :
파일은 menged.jsonl 로 명명되었으며 디렉토리 training_data/[index_name]/[topic_name]/processed/ , 여기서 [index_name]은 샘플이 수집 된 데이터 소스 와이 데이터의 각 검색 쿼리의 이름입니다.
각 라인은 다음 형식의 훈련 샘플을 나타냅니다.
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
이 작업이 도움이된다면 출판물 측면 제어 신경 논증 세대를 인용하십시오.
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
담당자 : Benjamin Schiller
https://www.ukp.tu-darmstadt.de/


