controlled argument generation
1.0.0
مستودع مصاحب لتوليد الحجة العصبية التي يسيطر عليها الجانب.
نحن نعتمد على الحجج في حياتنا اليومية لتقديم آرائنا وإعدادها على الأدلة ، مما يجعلها أكثر إقناعًا بدورها. ومع ذلك ، يمكن أن يكون العثور على الحجج وصياغةها أمرًا صعبًا. لمعالجة هذا التحدي ، قمنا بتدريب نموذج لغة (استنادًا إلى CTRL بواسطة Keskar et al. (2019)) لتوليد الحجج الذي يمكن التحكم فيه على مستوى دقيق لتوليد حجج على مستوى الجملة لموقف وموقف وجوانب معينة. نحن نحدد اكتشاف جانب الوسيطة كوسيلة ضرورية للسماح لهذا التحكم الحصري الدقيق وتجمع مجموعة بيانات مع 5،032 وسيلة مشروحة مع الجوانب. نقوم بإصدار مجموعة البيانات هذه ، وكذلك بيانات التدريب لنموذج توليد الوسيطة ، وأوزانها ، والوسائط التي تم إنشاؤها مع النموذج.
يوضح الشكل التالي كيف تم تدريب نموذج توليد الحجة:
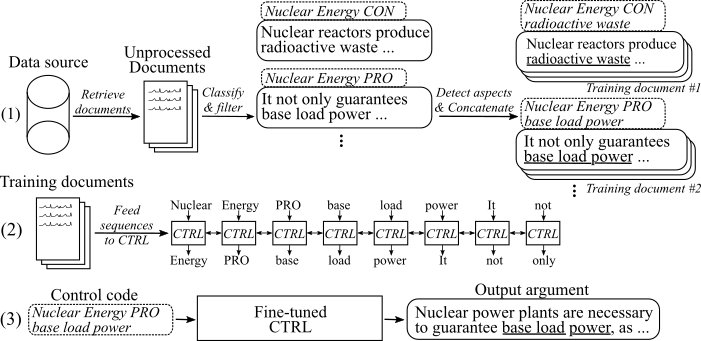
(1) نجمع عدة ملايين وثائق لثمانية مواضيع مختلفة من مصدرين بيانات كبيرتين. يتم تصنيف جميع الجمل إلى الحجوزات المؤيدة والخروجية. نكتشف جوانب جميع الحجج من خلال نموذج مدرب على مجموعة بيانات جديدة وحجج متسلسلة مع نفس الموضوع والموقف والجانب في وثائق التدريب. (2) نستخدم البيانات المصنفة التي تم جمعها لشرط نموذج CTRL في الموضوعات والمواقف والجوانب لجميع الحجج التي تم جمعها. (3) عند الاستدلال ، فإن تمرير رمز التحكم [الموضوع] [STANCE] [الجانب] سيؤدي إلى إنشاء وسيطة تتبع هذه الأوامر.
15. مايو 2020
لقد أضفنا الكود لنموذج توليد الحجة العصبية التي يسيطر عليها الجانب والأوصاف التي تم فصلها حول كيفية استخدامه. يعدل النموذج والرمز العمل بواسطة Keskar et al. (2019). يمكن العثور على رابط الأوزان النموذجية وبيانات التدريب في قسم التنزيلات.
8. مايو 2020
يمكن تنزيل مجموعة بيانات الكشف عن جانب الوسيطة من هنا ( presument_aspect_detection_v1.0.7z ). من هناك ، يمكنك أيضًا تنزيل الوسائط التي تم إنشاؤها مع نماذج توليد الوسيطة ( endered_arguments.7z ) والبيانات لإعادة إنتاج صياغة نموذج توليد الوسيطة ( Reddit_training_data.7z ، cc_training_data.7z ).
ملاحظة : بسبب أسباب الترخيص ، لا يمكن توزيع هذه الملفات بحرية. سيؤدي النقر فوق أي من الملفات إلى إعادة توجيهك إلى نموذج ، حيث يتعين عليك ترك الاسم والبريد الإلكتروني. بعد إرسال النموذج ، ستتلقى رابط تنزيل قريبًا.
قم بتنزيل مجموعات البيانات من هنا. يمكنك تنزيل الملفات التالية:
ملاحظة : بسبب أسباب الترخيص ، لا يمكن توزيع هذه الملفات بحرية. سيؤدي النقر فوق أي من الملفات إلى إعادة توجيهك إلى نموذج ، حيث يتعين عليك ترك الاسم والبريد الإلكتروني. بعد إرسال النموذج ، ستتلقى رابط تنزيل قريبًا.
استخدم البرامج النصية/تنزيل _weights.sh لتنزيل أوزان النموذج. سيقوم البرنامج النصي بتنزيل الأوزان الخاصة بالنموذج الذي تم ضبطه بشكل جيد على عمليات الرصاص وبيانات الزحف الشائعة وإلغاء إبطالها في مجلد المشروع الرئيسي.
تم اختبار الرمز مع Python3.6 . تثبيت جميع المتطلبات مع
pip install -r requirements.txt
واتبع الإرشادات الموجودة في ReadMe الأصلي عند الاستخدام ، الخطوة 1 و 2 .
في ما يلي ، وصفنا ثلاثة أساليب لاستخدام نموذج توليد الحجة العصبية التي يسيطر عليها الجانب:
أ. استخدم النموذج للجيل فقط
B. استخدم بيانات التدريب المتاحة لإعادة إنتاج/ضبط النموذج
ج. استخدم بياناتك الخاصة لضبط نموذج توليد الحجة العصبية الجديدة التي يسيطر عليها الجانب
من أجل إنشاء وسيطات ، يرجى أولاً تنزيل أوزان النماذج (قم بتنزيل البرنامج النصي على البرامج النصية/التنزيل _weights.sh ). قم بتشغيل النموذج عبر python generation.py --model_dir reddit_seqlen256_v1 للنموذج المدرب على بيانات reddit-comments أو python generation.py --model_dir cc_seqlen256_v1 للنموذج المدرب على بيانات crawl الشائعة. بعد اكتمال التحميل ، اكتب رمز التحكم ، على سبيل المثال nuclear energy CON waste ، لإنشاء الحجج التي تتبع رمز التحكم هذا. للحصول على نتائج أفضل للوسيطة الأولى التي تم إنشاؤها ، يمكنك إنهاء رمز التحكم بفترة أو قولون ("." أو ":"). لمزيد من التفاصيل ، يرجى الرجوع إلى الورقة.
ملاحظة : يمكن العثور على رموز التحكم المسموح بها لكل موضوع ومصدر البيانات في مجلد Training_Data .
من أجل ضبط النموذج كما فعلنا في عملنا ، يرجى اتباع هذه الخطوات:
قم بتنزيل الأوزان التي تم تدريبها مسبقًا من الورقة الأصلية (readme الأصلية عند الاستخدام ، الخطوة 3 ).
قم بتنزيل بيانات التدريب (انظر قسم التنزيلات. أنت بحاجة إلى ملف Reddit_training_data.7z أو cc_training_data.7z . اعتمادًا على المصدر (CC أو reddit ) ، ضع الأرشيف إما في مجلد التدريب_
7za x [FILENAME].7z
لإعادة إنتاج مستندات التدريب نفسها من بيانات التدريب كما استخدمنا للضبط ، يرجى استخدام البرنامج النصي في Training_utils/Pipeline/Prepared_documents_all.sh وتكييف معلمة الفهرس . بناءً على أجهزتك ، قد يستغرق توليد مستندات التدريب ساعة أو أكثر لحسابها.
أخيرًا ، يجب إنشاء Tfrecords من جميع وثائق التدريب. للقيام بذلك ، يرجى التشغيل:
python make_tf_records_multitag.py --files_folder [FOLDER] --sequence_len 256
[المجلد] يحتاج إلى الإشارة إلى مجلد وثائق التدريب ، على سبيل المثال التدريب _data/Common-Crawl-en/الإجهاض/النهائي/ . بعد التوليد ، يتم طباعة عدد تسلسل التدريب الذي تم إنشاؤه لهذا الموضوع المحدد. استخدم هذا لتحديد عدد الخطوات التي يجب تدريب النموذج عليها. يتم تخزين tfrecords في المجلد التدريب .
تدريب النموذج:
python training.py --model_dir [WEIGHTS FOLDER] --iterations [NUMBER OF TRAINING STEPS]
يأخذ النموذج tfrecords التي تم إنشاؤها تلقائيًا من مجلد التدريب . يرجى ملاحظة أن الأوزان في [مجلد الأوزان] سيتم الكتابة عليها. للتوليد مع النموذج الذي تم ضبطه حديثًا ، اتبع الإرشادات الواردة في " A. استخدام نموذج لتوليد فقط ".
لتخفيف عملية جمع بيانات التدريب الخاصة بك ، نضيف تنفيذنا لخط الأنابيب الموصوف في نشرنا (انظر I. استخدم خط الأنابيب لدينا (مع API Presentext)). لتسمية الجمل كوسيط وتحديد مواقفها وجوانبها ، نستخدم Presentext-API. بدلاً من ذلك ، يمكنك أيضًا تدريب النماذج الخاصة بك (انظر II. قم بإنشاء خط الأنابيب الخاص بك (بدون API Presentext)).
يرجى طلب استخدام المستخدم و apikey ل presentext-api. اكتب كل من المعرف والمفتاح في الثوابت المعنية في Training_Utils/خط الأنابيب/بيانات الاعتماد .
كخطوة أولى ، يجب جمع وثائق التدريب لموضوع الاهتمام. ( ملاحظة: هذه الخطوة ليست جزءًا من الكود ويجب أن تكون ذاتيًا ). لقد فعلنا ذلك عن طريق تنزيل تفريغ من الزحف المشترك والرديت وفهرستها باستخدام Elasticsearch. يجب أن تكون النتيجة مستندات يتم تخزينها في التدريب _data/[index_name]/[topic_name]/غير معالج/ ، حيث [index_name] هو اسم مصدر البيانات (مثل [index_name ] و [topic_name] هو موضوع البحث الذي تم جمع المستندات من أجله (استبدال Whitespaces في [index_name] و [topic_name]. كل مستند عبارة عن ملف JSON منفصل مع "Sents" على الأقل الذي يحمل قائمة من الجمل من هذا المستند:
{
"sents": ["sentence #1", "sentence #2", ...]
}
يأخذ argument_classification.py جميع المستندات التي تم جمعها لموضوع معين وتصنيف جملها إلى الحجج المؤيدة/غير المقيدة. يبدأ الأمر التالي التصنيف:
python argument_classification.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
يتم التخلص من غير الحجوزات ويتم تخزين الوسائط المصنفة النهائية في ملفات بحد أقصى 200000 وسيلة لكل منها في التدريب _data/[index_name]/[topic_name]/معالجتها/ .
الجوانب applet_detection.py يوسع جميع الوسائط المصنفة مسبقًا ويكتشف جوانبها. يبدأ الأمر التالي اكتشاف الجانب:
python aspect_detection.py --topic [TOPIC_NAME] --index [TOPIC_NAME]
ثم يتم تخزين جميع الوسائط مع جوانبها في ملف واحد تم دمجه .
يقوم repar_documents.py بإلحاق جميع الوسائط التي لها نفس الموضوع والموقف والجانب (الجذري) إلى وثيقة التدريب:
python prepare_documents.py --max_sents [MAX_SENTS] --topic [TOPIC_NAME] --index [INDEX_NAME] --max_aspect_cluster_size [MAX_ASPECT_CLUSTER_SIZE] --min_aspect_cluster_size [MIN_ASPECT_CLUSTER_SIZE]
يحدد [max_sents] الحد الأقصى لعدد الوسائط المراد استخدامه (تم توزيعه بالتساوي بين الوسيطات المحترفة والخداع إذا كان ذلك ممكنًا) و [min_aspect_cluster_size]/[max_aspect_cluster_size] يعينون عدد الوسيطات المسموح بها/الحد الأقصى إلى إلحاق وثيقة تدريب واحدة. يتم تخزين المستندات النهائية في Folder Training_Data/[index_name]/[topic_name]/final/ . يمكن استخدام البرنامج النصي prepar_all_documents.sh لأتمتة العملية.
أخيرًا ، لإنشاء تسلسل تدريب من المستندات وبدء صياغة النموذج ، يرجى تنزيل أوزاننا المعدلة (انظر قسم التنزيل) واتبع B. استخدم بيانات التدريب المعطاة لإعادة إنتاج/ضبط النموذج ، الخطوات 4-5.
هام : بالإضافة إلى مستندات التدريب ، يتم إنشاء ملف يحتوي على جميع رموز التحكم استنادًا إلى مستندات التدريب في التدريب _data/[index_name]/[topic_name] /generation_data/control_codes.jsonl . يحمل هذا الملف جميع رموز التحكم لإنشاء وسيط من بعد انتهاء الضبط.
لتدريب نموذج تصنيف الحجة وموقف ، يمكنك استخدام مجموعة UKP والنماذج الموضحة في المنشور المقابل من قبل Stab et al. (2018). للحصول على نتائج أفضل ، نقترح استخدام Bert (Devlin et al. ، 2019).
لتدريب نموذج اكتشاف الجوانب ، يرجى تنزيل مجموعة بيانات اكتشاف جانب الوسيطة الخاصة بنا (بسبب أسباب الترخيص ، من الضروري ملء النموذج باسمك والبريد الإلكتروني). كنموذج ، نقترح Bert من Huggingface لعلامة التسلسل.
من أجل إعداد مستندات التدريب وضبط النموذج ، يمكنك استخدام repart_documents.py كما هو موضح في I. استخدم خط الأنابيب الخاص بنا (مع API Presentext) ، الخطوة د. إذا احتفظت ببياناتك المصنفة بالتنسيق التالي:
يجب تسمية الملف merged.jsonl ويقع في الدليل التدريبي _data/[index_name]/[topic_name]/معالجته/ ، حيث [index_name] هو مصدر البيانات من حيث تم جمع العينات و [topic_name] اسم استعلام البحث المعني لهذه البيانات.
يمثل كل سطر عينة تدريب بالتنسيق التالي:
{"id": id of the sample, starting with 0 (int), "stance": "Argument_against" or "Argument_for", depending on the stance (string), "sent": The argument sentence (string), "aspect_string": A list of aspects for this argument (list of string)}
إذا وجدت هذا العمل مفيدًا ، فيرجى الاستشهاد بتوليد الحجة العصبية التي يتم التحكم فيها في جانب النشر:
@inproceedings{schiller-etal-2021-aspect,
title = "Aspect-Controlled Neural Argument Generation",
author = "Schiller, Benjamin and
Daxenberger, Johannes and
Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.34",
doi = "10.18653/v1/2021.naacl-main.34",
pages = "380--396",
abstract = "We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we present the Arg-CTRL - a language model for argument generation that can be controlled to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that the Arg-CTRL is able to generate high-quality, aspect-specific arguments, applicable to automatic counter-argument generation. We publish the model weights and all datasets and code to train the Arg-CTRL.",
}
شخص الاتصال: بنيامين شيلر
https://www.ukp.tu-darmstadt.de/


