boilerplate dynet rnn lm
1.0.0
这是用于快速轻松地从地面上进行语言建模实验的样板代码。该代码写在Dynet框架的Python版本中,可以使用这些说明安装。
如果您在Word级别使用默认阅读器,则它还具有模式作为令牌化的依赖性。
有关RNN语言模型的介绍,它们的工作方式以及一些很酷的演示,请查看Andrej Karpathy的出色博客文章:经常性神经网络的不合理有效性。
训练宾夕法尼亚州培养基的基线RNN模型:
char-level: python train.py
文字级别: python train.py --word_level
在任何文件上训练基线RNN模型:
char-level: python train.py --train=<filename> --reader=generic_char --split_train
字级: python train.py --train=<filename> --reader=generic_word --split_train
从那里开始,您可以设置一堆标志来调整模型的大小,辍学,体系结构和许多其他东西。旗帜应该是非常自我解释的。您可以使用python train.py -h列出旗帜
如果您想保存训练有素的型号并稍后再介绍,只需使用--save=FILELOC标志即可。然后,您稍后可以加载load=FILELOC标志。注意:如果加载模型,也会加载其参数设置,因此--load load标志覆盖了--size , --gen_layers , --gen_hidden_dim ,等等。
默认情况下,该代码设置为训练Penn Treebank数据,该数据包含在ptb/文件夹中的存储库中。
要添加新的数据源,只需在util.py中实现一个新的coldusreader。确保将“ names属性”设置为一个至少包含一个唯一ID的列表。然后,设置--reader=ID ,并使用--train , --valid和--test标志指向您的数据集。如果您没有预分离的数据,则只需设置--train ,并包括--split_train标志以将您的数据自动分为火车,有效和测试拆分即可。
要实现一个新模型,只需进入rnnlm.py,创建一个新的SaveAblernnLM子类,该子类实现功能add_params , BuildLMGraph和BuildLMGraph_batch 。包括一个示例。确保将新类的name属性设置为唯一ID,然后使用--arch=ID标志告诉代码使用新模型。
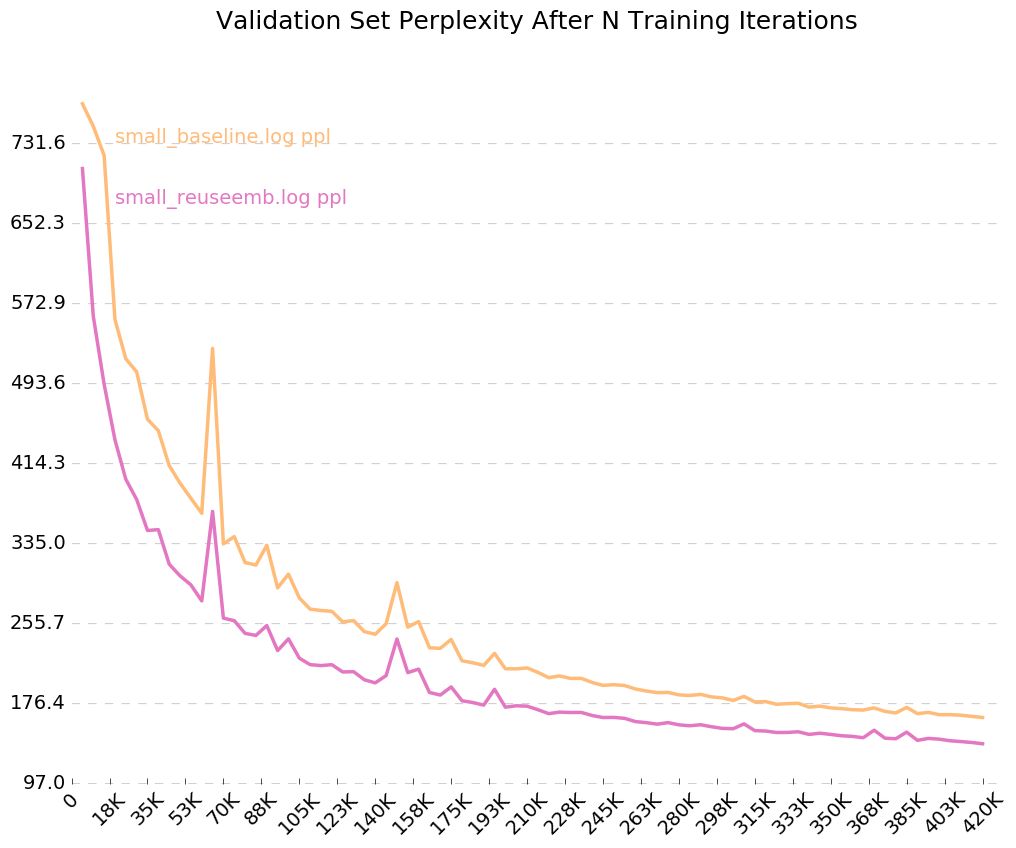
要查看您的模型如何随着时间的推移进行训练的清晰图表,请致电python visualize_log.py <filename> <filename>...绘制多达20次培训。为了生成用作可视化器输入的日志文件,只需在训练时包含--output=<filename> flag。
--size参数有四个设置:小(1层,每个嵌入的参数128个参数,复发性隐藏层中的128个节点),中等(2层,256个输入昏暗,256个隐藏dim),大(2,512,512)和巨大(2,1024,1024,1024)。您还可以使用标志--gen_layers , --gen_input_dim和--gen_hidden_dim单独设置参数。
假设我们想测试[单词嵌入的重复使用如何影响语言模型的性能](https://openreview.net/pdf?id=r1apbsfle)。我们将使用PTB语料库,因此我们不必担心设置新的语料库读取器 - 只需使用默认值即可。
首先,让我们训练10个时期的基线模型:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(等待大约2-3个小时)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
这比论文中报道的基线困惑差得多,但这是因为我们只是使用通用LSTM模型作为基线,而不是更复杂的VD-LSTM模型,并且参数较少。
接下来,让我们修改基线语言模型以结合单词嵌入的重复使用。例如,我已经在rnnlm.py中完成了此操作,创建了一个名为ReuseEmbeddingsRNNLM的类name = "reuse_emb" 。该代码几乎只是上面基线模型的副本和贴合,更改了大约10行,以将单词嵌入的重新使用纳入输出的预测中。现在,让我们也要进行这些测试:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(等待大约2-3个小时)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
在那里我们有 - 重复使用嵌入使我们的困惑下降了26分。好的!
由于我们打开了输出日志的标志, --output=small_baseline.log and --output=small_reuseemb.log ,我们可以通过使用随附的visualize_log.py脚本在训练过程中可视化我们的验证错误。
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
生产:
如果您有任何疑问,请随时打我:[email protected]


