boilerplate dynet rnn lm
1.0.0
นี่คือรหัสหม้อต้มสำหรับการทดลองอย่างรวดเร็วและง่ายดายเกี่ยวกับการสร้างแบบจำลองภาษาจากพื้นดิน รหัสถูกเขียนในเวอร์ชัน Python ของเฟรมเวิร์ก Dynet ซึ่งสามารถติดตั้งได้โดยใช้คำแนะนำเหล่านี้
นอกจากนี้ยังมี pattern.en เป็นการพึ่งพาสำหรับ tokenization หากคุณใช้เครื่องอ่านเริ่มต้นที่ระดับคำ
สำหรับการแนะนำโมเดลภาษา RNN วิธีการทำงานและการสาธิตที่ยอดเยี่ยมโปรดดูโพสต์บล็อกที่ยอดเยี่ยมของ Andrej Karpathy: ประสิทธิภาพที่ไม่สมเหตุสมผลของเครือข่ายประสาทที่เกิดขึ้นอีก
เพื่อฝึกอบรมรุ่นพื้นฐาน RNN บน Penn Treebank:
Char-Level: python train.py
Word-level: python train.py --word_level
ในการฝึกอบรมรุ่นพื้นฐาน RNN ในไฟล์ใด ๆ :
Char-Level: python train.py --train=<filename> --reader=generic_char --split_train
Word-level: python train.py --train=<filename> --reader=generic_word --split_train
จากนั้นมีธงจำนวนมากที่คุณสามารถตั้งค่าให้ปรับขนาดของโมเดลการออกกลางคันสถาปัตยกรรมและสิ่งอื่น ๆ อีกมากมาย ธงควรอธิบายตนเอง คุณสามารถแสดงรายการธงด้วย python train.py -h
หากคุณต้องการบันทึกโมเดลที่ผ่านการฝึกอบรมมาแล้วกลับมาในภายหลังเพียงแค่ใช้ --save=FILELOC FLAG จากนั้นคุณสามารถโหลดได้ในภายหลังด้วย load=FILELOC Flag หมายเหตุ: หากคุณโหลดโมเดลคุณยังโหลดการตั้งค่าพารามิเตอร์ด้วยดังนั้น --load ธงจะแทนที่สิ่งต่าง ๆ เช่น --size , --gen_layers , --gen_hidden_dim ฯลฯ
โดยค่าเริ่มต้นรหัสนี้จะถูกตั้งค่าเพื่อฝึกอบรมบนข้อมูล Penn TreeBank ซึ่งรวมอยู่ใน repo ใน ptb/ โฟลเดอร์
ในการเพิ่มแหล่งข้อมูลใหม่เพียงใช้ CorpusReader ใหม่ใน Util.py ตรวจสอบให้แน่ใจว่าคุณตั้งค่าคุณสมบัติ names เป็นรายการที่มีรหัสที่ไม่ซ้ำกันอย่างน้อยหนึ่งรายการ จากนั้นตั้ง --reader=ID และใช้ --train , --valid และ --test ธงเพื่อชี้ไปที่ชุดข้อมูลของคุณ หากคุณไม่มีข้อมูลที่คั่นด้วยล่วงหน้าเพียงแค่ตั้งค่า --train และรวมธง --split_train เพื่อให้ข้อมูลของคุณแยกออกเป็นรถไฟโดยอัตโนมัติและการทดสอบแยก
หากต้องการใช้โมเดลใหม่เพียงไปที่ rnnlm.py สร้างคลาสย่อยใหม่ของ SaveablerNnlm ซึ่งใช้ฟังก์ชั่น add_params , BuildLMGraph และ BuildLMGraph_batch ตัวอย่างรวมอยู่ด้วย ตรวจสอบให้แน่ใจว่าคุณตั้งค่าคุณสมบัติ name ของคลาสใหม่ของคุณเป็น ID ที่ไม่ซ้ำกันจากนั้นใช้ธง --arch=ID เพื่อบอกรหัสให้ใช้โมเดลใหม่ของคุณ
หากต้องการรับกราฟที่สะอาดว่าโมเดลของคุณคือการฝึกอบรมเมื่อเวลาผ่านไปให้โทรไปที่ python visualize_log.py <filename> <filename>... เพื่อวางแผนการฝึกอบรมสูงสุด 20 ครั้ง การสร้าง logfiles ที่ใช้เป็นอินพุตสำหรับ Visualizer เพียงรวมการตั้งค่าสถานะ --output=<filename> เมื่อฝึกอบรม
พารามิเตอร์ --size มีการตั้งค่าสี่ครั้ง: ขนาดเล็ก (1 ชั้น, 128 พารามิเตอร์ต่อการฝัง, 128 โหนดในเลเยอร์ที่ซ่อนเร้นซ้ำ), กลาง (2 เลเยอร์, 256 อินพุตสลัว, 256 ที่ซ่อนอยู่), ขนาดใหญ่ (2, 512, 512) และใหญ่มาก (2, 1024, 1024, 1024 นอกจากนี้คุณยังสามารถตั้งค่าพารามิเตอร์เป็นรายบุคคลด้วยธง --gen_layers , --gen_input_dim และ --gen_hidden_dim
สมมติว่าเราต้องการทดสอบ [การใช้คำที่ใช้ซ้ำอีกครั้งมีผลต่อประสิทธิภาพของแบบจำลองภาษา] (https://openreview.net/pdf?id=r1apbsfle) เราจะใช้ PTB Corpus ดังนั้นเราไม่จำเป็นต้องกังวลเกี่ยวกับการตั้งค่าตัวอ่านคลังข้อมูลใหม่ - เพียงใช้ค่าเริ่มต้น
ก่อนอื่นมาฝึกอบรมแบบจำลองพื้นฐานสำหรับ 10 Epochs:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(รอประมาณ 2-3 ชั่วโมง)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
สิ่งนี้เลวร้ายยิ่งกว่าความงุนงงพื้นฐานที่รายงานในกระดาษ แต่นั่นเป็นเพราะเราเพิ่งใช้โมเดล LSTM ทั่วไปเป็นพื้นฐานของเรามากกว่ารุ่น VD-LSTM ที่ซับซ้อนกว่าและมีพารามิเตอร์น้อยลง
ถัดไปเรามาปรับเปลี่ยนรูปแบบภาษาพื้นฐานของเราเพื่อรวมการใช้คำที่ฝังคำอีกครั้ง ตัวอย่างเช่นฉันได้ทำสิ่งนี้ใน rnnlm.py การสร้างคลาสที่เรียกว่า ReuseEmbeddingsRNNLM ด้วย name = "reuse_emb" รหัสนี้ค่อนข้างเป็นเพียงการคัดลอกและวางของโมเดลพื้นฐานด้านบนการเปลี่ยนแปลงประมาณ 10 บรรทัดเพื่อรวมการฝังคำที่ฝังคำลงในการทำนายเอาต์พุต ตอนนี้เรามาทดสอบกันเถอะ:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(รอประมาณ 2-3 ชั่วโมง)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
และที่นั่นเรามี - การใช้ซ้ำของการฝังตัวทำให้เราลดลง 26 จุด ดี!
เนื่องจากเราเปิดการตั้งค่าสถานะสำหรับบันทึกเอาต์พุต --output=small_baseline.log และ --output=small_reuseemb.log เราสามารถเห็นภาพข้อผิดพลาดการตรวจสอบความถูกต้องของเราเมื่อเวลาผ่านไประหว่างการฝึกอบรมโดยใช้สคริปต์ visualize_log.py ที่รวมอยู่
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
การผลิต:
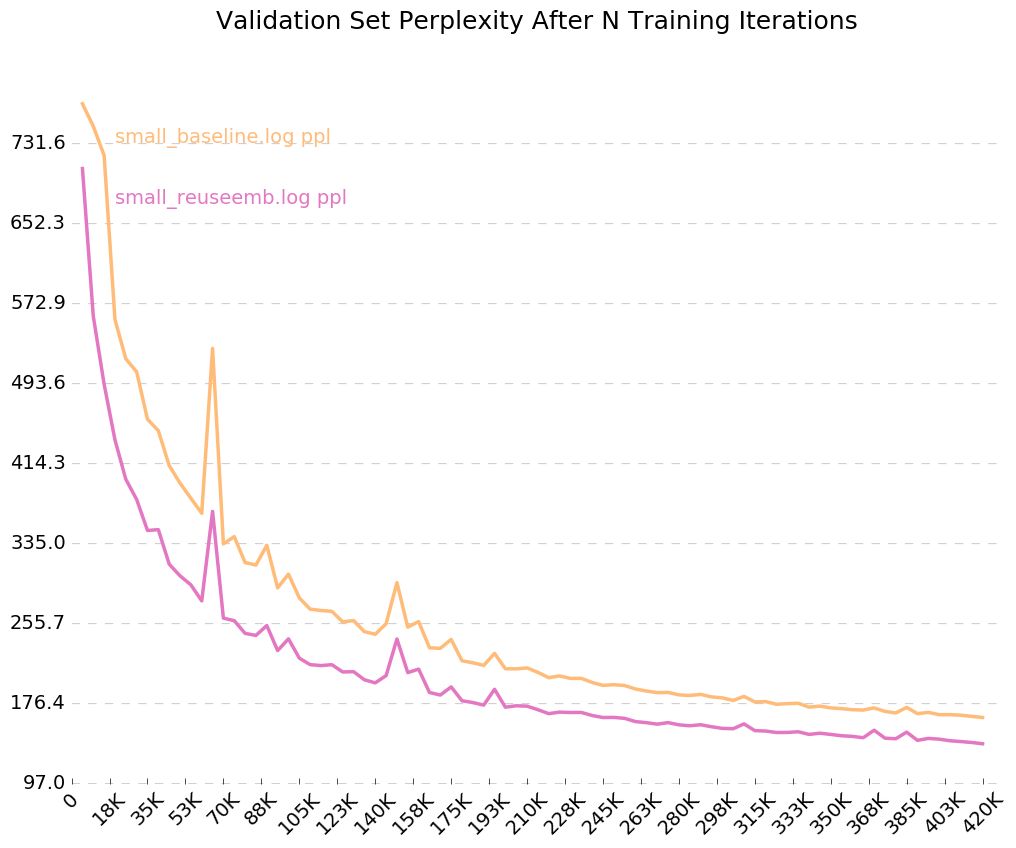
หากคุณมีคำถามใด ๆ โปรดอย่าลังเลที่จะตีฉัน: [email protected]


