boilerplate dynet rnn lm
1.0.0
Este é o código de caldeira para obter experiências de modelagem de idiomas com rapidez e facilidade com a modelagem de idiomas. O código é escrito na versão Python da estrutura do Dynet, que pode ser instalada usando essas instruções.
Ele também possui padrão. Como uma dependência para tokenização, se você estiver usando o leitor padrão no nível da palavra.
Para uma introdução aos modelos de idiomas RNN, como eles funcionam e algumas demos legais, dê uma olhada na excelente postagem do blog de Andrej Karpathy: a eficácia irracional das redes neurais recorrentes.
Para treinar um modelo RNN de linha de base no Penn Treebank:
Nível de char: python train.py
Nível de palavra: python train.py --word_level
Para treinar um modelo RNN de linha de base, em qualquer arquivo:
Nível de char: python train.py --train=<filename> --reader=generic_char --split_train
Nível de palavra: python train.py --train=<filename> --reader=generic_word --split_train
A partir daí, há um monte de bandeiras que você pode definir para ajustar o tamanho do modelo, o abandono, a arquitetura e muitas outras coisas. As bandeiras devem ser bastante auto -explicativas. Você pode listar as bandeiras com python train.py -h
Se você deseja economizar um modelo treinado e voltar a ele mais tarde, basta usar o sinalizador --save=FILELOC . Em seguida, você pode carregá -lo mais tarde com o sinalizador load=FILELOC . NOTA: Se você carregar um modelo, também carrega as configurações de parâmetros; portanto, o sinalizador --load substitui as coisas como --size , --gen_layers , --gen_hidden_dim , etc.
Por padrão, este código é configurado para treinar nos dados da Penn Treebank, incluídos no repositório na pasta ptb/ .
Para adicionar uma nova fonte de dados, basta implementar um novo CorpusReader em util.py. Certifique -se de definir a propriedade names como uma lista que inclua pelo menos um ID exclusivo. Em seguida, defina os --reader=ID e use os sinalizadores --train , --valid e --test para apontar para o seu conjunto de dados. Se você não possui dados pré-separados, basta definir --train e incluir o sinalizador --split_train para que seus dados se separem automaticamente em divisões de trem, válido e teste.
Para implementar um novo modelo, basta entrar no rnnlm.py, crie uma nova subclasse do SAVEABLERNNLM, que implementa as funções add_params , BuildLMGraph e BuildLMGraph_batch . Um exemplo está incluído. Certifique -se de definir a propriedade name da sua nova classe como um ID exclusivo e, em seguida, use o sinalizador --arch=ID para informar o código para usar seu novo modelo.
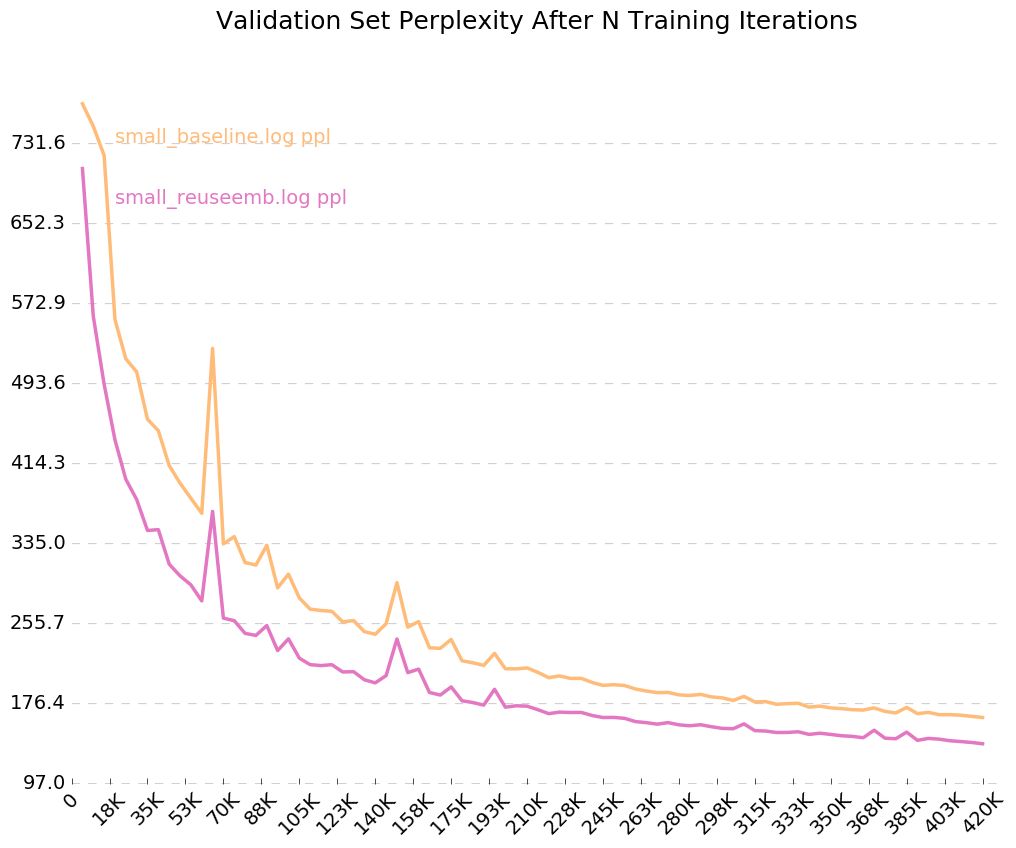
Para obter um gráfico limpo de como seu modelo está treinando ao longo do tempo, ligue para python visualize_log.py <filename> <filename>... para plotar até 20 execuções de treinamento. Para gerar os arquivos de log usados como entrada para o visualizador, basta incluir o sinalizador --output=<filename> ao treinar.
O parâmetro --size vem em quatro configurações: Pequena (1 camada, 128 parâmetros por incorporação, 128 nós na camada oculta recorrente), médio (2 camadas, 256 entrada dim, 256 oculto), grande (2, 512, 512) e enormoso (2, 1024, 1024). Você também pode definir os parâmetros individualmente, com os sinalizadores --gen_layers , --gen_input_dim e --gen_hidden_dim .
Digamos que queríamos testar [como a reutilização de incorporações de palavras afeta o desempenho de um modelo de idioma] (https://openreview.net/pdf?id=r1apBSFLE). Usaremos o PTB Corpus, por isso não precisamos nos preocupar em configurar um novo leitor de corpus - basta usar o padrão.
Primeiro, vamos treinar um modelo de linha de base para 10 épocas:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Aguarde por cerca de 2-3 horas)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
Isso é muito pior que a perplexidade da linha de base relatada no artigo, mas isso é porque estamos apenas usando um modelo LSTM genérico como nossa linha de base, em vez do modelo VD-LSTM mais complexo e com muitos parâmetros.
Em seguida, vamos modificar nosso modelo de linguagem de linha de base para incorporar a reutilização de incorporações de palavras. Como exemplo, eu fiz isso no RNNLM.Py, criando uma classe chamada ReuseEmbeddingsRNNLM com name = "reuse_emb" . O código é praticamente apenas uma cópia e cola do modelo de linha de base acima, alterando cerca de 10 linhas para incorporar o caso de incorporação de palavras na previsão de saídas. Agora, vamos executar esses testes também:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Aguarde por cerca de 2-3 horas)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
E lá estamos - a reutilização de incorporações nos dá uma diminuição de 26 pontos de perplexidade. Legal!
Desde que ligamos o sinalizador para logs de saída, --output=small_baseline.log e --output=small_reuseemb.log , podemos visualizar nosso erro de validação ao longo do tempo durante o treinamento usando o script visualize_log.py incluído:
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Produzindo:
Se você tiver alguma dúvida, fique à vontade para me bater: [email protected]


