boilerplate dynet rnn lm
1.0.0
Dies ist der Boilerplate -Code, um schnell und einfache Experimente zur Sprachmodellierung aus dem Boden zu erhalten. Der Code ist in der Python -Version des Dynet -Frameworks geschrieben, das mit diesen Anweisungen installiert werden kann.
Es hat auch Muster.En als Abhängigkeit für die Tokenisierung, wenn Sie den Standardleser auf Wortebene verwenden.
Für eine Einführung in RNN -Sprachmodelle, wie sie funktionieren und einige coole Demos, sehen Sie sich den hervorragenden Blog -Beitrag von Andrej Karpathy an: die unangemessene Wirksamkeit wiederkehrender neuronaler Netzwerke.
Um ein Basis -RNN -Modell auf der Penn Treebank zu trainieren:
Char-Level: python train.py
Word-Level: python train.py --word_level
So trainieren Sie ein Basis -RNN -Modell in jeder Datei:
Zeichen-Level: python train.py --train=<filename> --reader=generic_char --split_train
Word-Level: python train.py --train=<filename> --reader=generic_word --split_train
Von dort aus gibt es eine Reihe von Flags, die Sie so einstellen können, dass die Größe des Modells, des Ausropfens, der Architektur und viele andere Dinge angepasst wird. Die Flaggen sollten ziemlich selbsterklärend sein. Sie können die Flags mit python train.py -h auflisten
Wenn Sie ein geschultes Modell speichern und später darauf zurückkehren möchten, verwenden Sie einfach das Flag --save=FILELOC . Dann können Sie es später mit dem load=FILELOC -Flag laden. Hinweis: Wenn Sie ein Modell laden, laden Sie auch seine Parametereinstellungen, so dass das Flag --load die Dinge wie --size , --gen_layers , --gen_hidden_dim , usw. überschreibt.
Standardmäßig ist dieser Code eingerichtet, um auf den Penn Treebank -Daten zu trainieren, die im Repo im ptb/ Ordner enthalten sind.
Um eine neue Datenquelle hinzuzufügen, implementieren Sie einfach einen neuen Corpusreader in Util.py. Stellen Sie sicher, dass Sie die names als Liste festlegen, die mindestens eine eindeutige ID enthält. Setzen Sie dann die --reader=ID und verwenden Sie die Flags --train , --valid und --test , um auf Ihren Datensatz zu verweisen. Wenn Sie keine übergeschiedenen Daten haben, setzen Sie einfach --train und schließen Sie das Flag --split_train ein, damit Ihre Daten automatisch in Zug, gültig und testen.
Um ein neues Modell zu implementieren, gehen Sie einfach zu rnnlm.py, erstellen Sie eine neue Unterklasse von SaveABLERNNLM, die die Funktionen add_params , BuildLMGraph und BuildLMGraph_batch implementiert. Ein Beispiel ist enthalten. Stellen Sie sicher, dass Sie die name Ihrer neuen Klasse auf eine eindeutige ID einstellen, und verwenden Sie dann das Flag --arch=ID um den Code zu sagen, dass Sie Ihr neues Modell verwenden sollen.
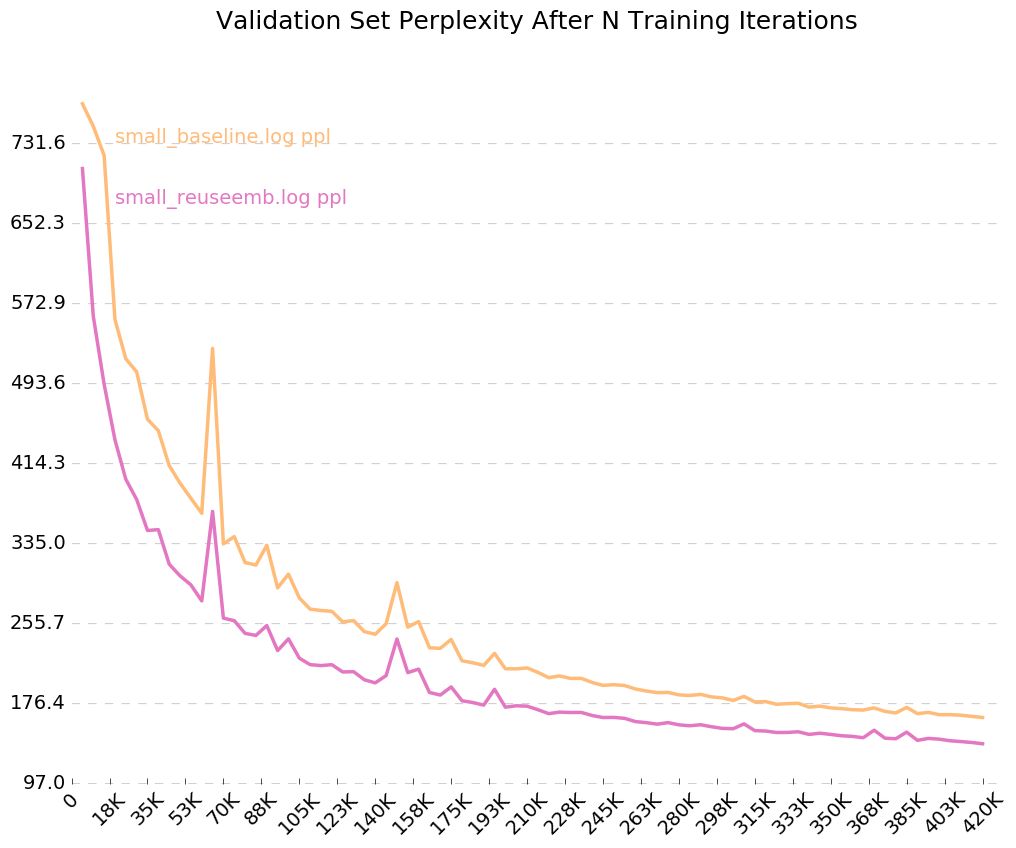
Um ein sauberes Diagramm darüber zu erhalten, wie Ihr Modell im Laufe der Zeit trainiert, rufen Sie python visualize_log.py <filename> <filename>... an, um bis zu 20 Trainingsläufe zu zeichnen. Um die als Eingabe für den Visualizer verwendeten Protokolldateien zu generieren, schließen Sie einfach das Flag --output=<filename> beim Training ein.
Der Parameter --size ist in vier Einstellungen geliefert: klein (1 Schicht, 128 Parameter pro Einbettung, 128 Knoten in der wiederkehrenden versteckten Schicht), Medium (2 Schichten, 256 Eingangsdim, 256 verstecktes Dim), groß (2, 512, 512) und enormal (2, 1024, 1024). Sie können die Parameter auch einzeln mit den Flags --gen_layers , --gen_input_dim und --gen_hidden_dim festlegen.
Angenommen, wir wollten die Leistung eines Sprachmodells testen [wie die Wiederverwendung von Worteinbettungen die Leistung eines Sprachmodells beeinflusst] (https://openreview.net/pdf?id=r1apbsfle). Wir werden den PTB Corpus verwenden, damit wir uns keine Sorgen machen müssen, einen neuen Corpus -Leser einzurichten. Verwenden Sie einfach die Standardeinstellung.
Lassen Sie uns zunächst ein Basismodell für 10 Epochen trainieren:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Warten Sie ungefähr 2-3 Stunden)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
Dies ist viel schlechter als die in der Arbeit gemeldete Basislinie-Verwirrung, aber das liegt daran, dass wir nur ein generisches LSTM-Modell als Grundlinie verwenden, anstatt das komplexere VD-LSTM-Modell und mit viel weniger Parametern.
Ändern wir als nächstes unser Basissprachmodell, um die Wiederverwendung von Worteinbettungen zu berücksichtigen. Als Beispiel habe ich dies in rnnlm.py gemacht und eine Klasse namens ReuseEmbeddingsRNNLM mit name = "reuse_emb" erstellt. Der Code ist so gut wie nur eine Kopie und ein Paste des obigen Basismodells, wobei sich etwa 10 Zeilen ändert, um die Wiederverwendung von Worteinbettungen in die Vorhersage von Ausgängen einzubeziehen. Lassen Sie uns jetzt auch diese Tests durchführen:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Warten Sie ungefähr 2-3 Stunden)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
Und dort haben wir es - Wiederverwendung von Einbettungsdings gibt uns eine Verwirrung von 26 Punkten. Hübsch!
Da wir das Flag für Ausgabeprotokolle eingeschaltet haben, --output=small_baseline.log und --output=small_reuseemb.log , können wir unseren Validierungsfehler im Laufe der Zeit während des Trainings visualisieren, indem wir das Skript visualize_log.py verwenden:
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Produzieren:
Wenn Sie Fragen haben, können Sie mich gerne treffen: [email protected]


