boilerplate dynet rnn lm
1.0.0
これは、地面からの言語モデリングに関する実験をすばやく簡単に取得するためのボイラープレートコードです。このコードは、これらの命令を使用してインストールできるDynet FrameworkのPythonバージョンで記述されています。
また、Word-Levelでデフォルトの読者を使用している場合、トークン化の依存関係としてpattern.enもあります。
RNN言語モデル、それらの仕組み、いくつかのクールなデモの紹介については、Andrej Karpathyの優れたブログ投稿である再発性ニューラルネットワークの不合理な有効性をご覧ください。
Penn TreeBankでベースラインRNNモデルをトレーニングするには:
Char-Level: python train.py
ワードレベル: python train.py --word_level
任意のファイルでベースラインRNNモデルをトレーニングするには:
char-level: python train.py --train=<filename> --reader=generic_char --split_train
ワードレベル: python train.py --train=<filename> --reader=generic_word --split_train
そこから、モデルのサイズ、ドロップアウト、アーキテクチャ、その他多くのものを調整するために設定できるフラグがたくさんあります。フラグはかなり自明でなければなりません。 python train.py -hでフラグをリストできます
訓練されたモデルを保存して後で戻ってくる場合は、 --save=FILELOCフラグを使用してください。次に、 load=FILELOCフラグで後でロードできます。注:モデルをロードすると、パラメーター設定もロードされるため、 --loadフラグは--size 、 --gen_layers 、 --gen_hidden_dimなどのようなものをオーバーライドします。
デフォルトでは、このコードは、 ptb/フォルダーのリポジトリに含まれるPenn TreeBankデータのトレーニングに設定されています。
新しいデータソースを追加するには、util.pyに新しいcorpusreaderを実装するだけです。 namesプロパティを少なくとも1つの一意のIDを含むリストに設定するようにしてください。次に、 --reader=IDを設定し、 --train 、 --valid 、および--testフラグを使用してデータセットを指します。事前に分離されたデータがない場合は、 --trainフラグ--split_train設定して、データを自動的に電車、有効、テストスプリットに分離するように設定して含めてください。
新しいモデルを実装するには、rnnlm.pyに移動するだけで、 add_params 、 BuildLMGraph 、およびBuildLMGraph_batch実装するsaveablernnlmの新しいサブクラスを作成します。例が含まれています。新しいクラスのnameプロパティを一意のIDに設定し、 --arch=IDフラグを使用して、コードに新しいモデルを使用するように指示します。
時間の経過とともにモデルのトレーニング方法のクリーンなグラフを取得するには、 python visualize_log.py <filename> <filename>...で最大20回のトレーニングをプロットしてください。 Visualizerの入力として使用されるログファイルを生成するには、トレーニング時に--output=<filename>フラグを含めるだけです。
--sizeパラメーターには、小さな設定があります:小さな(1層、埋め込みあたり128パラメーター、再発隠されたレイヤーの128ノード)、中(2層、256入力DIM、256 HIDDEN DIM)、Large(2、512、512)、および巨大な(2、1024、1024)。また、フラグ--gen_layers 、 --gen_input_dim 、および--gen_hidden_dimを使用して、パラメーターを個別に設定することもできます。
テストしたかったとしましょう[単語埋め込みの再利用が言語モデルのパフォーマンスにどのように影響するか](https://openreview.net/pdf?id=rr1apbsfle)。 PTBコーパスを使用するため、新しいコーパスリーダーのセットアップを心配する必要はありません。デフォルトを使用するだけです。
まず、10エポックのベースラインモデルを訓練しましょう。
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(約2〜3時間待ちます)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
これは、論文で報告されているベースラインの困惑よりもはるかに悪いことですが、それは、より複雑なVD-LSTMモデルではなく、パラメーターが多いものではなく、ベースラインとしてジェネリックLSTMモデルを使用しているだけだからです。
次に、ベースライン言語モデルを変更して、単語の埋め込みの再利用を組み込みましょう。例として、私はrnnlm.pyでこれを行い、 name = "reuse_emb"でReuseEmbeddingsRNNLMというクラスを作成しました。このコードは、上記のベースラインモデルのコピーアンドペーストであり、約10行を変更して、ワード埋め込みの履歴書を出力の予測に組み込みます。さて、それらのテストも実行しましょう:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(約2〜3時間待ちます)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
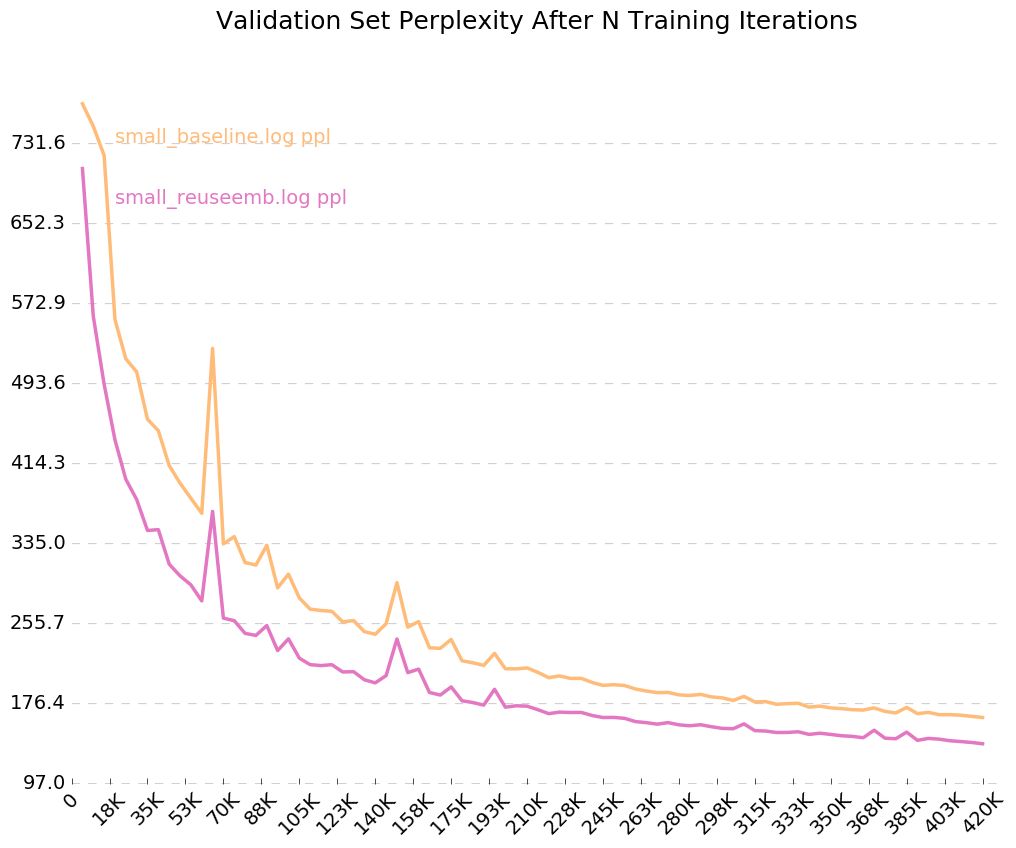
そして、私たちはそれを持っています - 埋め込みの再利用により、困惑が26ポイント減少します。ニース!
出力ログのフラグをオンにしたため、 --output=small_baseline.logおよび--output=small_reuseemb.log visualize_log.pyあるため、Training中に検証エラーを時間の経過とともに視覚化することができます。
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
プロデュース:
ご質問がある場合は、お気軽にご連絡ください:[email protected]


