boilerplate dynet rnn lm
1.0.0
هذا هو رمز Boilerplate للحصول على تجارب بسرعة وسهولة في نمذجة اللغة خارج الأرض. يتم كتابة الرمز في إصدار Python من إطار Dynet ، والذي يمكن تثبيته باستخدام هذه التعليمات.
كما أن له نمط.
للحصول على مقدمة لنماذج لغة RNN ، وكيف تعمل ، وبعض العروض التوضيحية الرائعة ، يرجى إلقاء نظرة على منشور المدونة الممتاز لـ Andrej Karpathy: الفعالية غير المعقولة للشبكات العصبية المتكررة.
لتدريب نموذج RNN الأساسي على بنك Treebank Penn:
char-level: python train.py
مستوى الكلمات: python train.py --word_level
لتدريب نموذج RNN الأساسي ، على أي ملف:
مستوى char: python train.py --train=<filename> --reader=generic_char --split_train
مستوى الكلمات: python train.py --train=<filename> --reader=generic_word --split_train
من هناك ، هناك مجموعة من الأعلام يمكنك ضبطها لضبط حجم النموذج ، والتسرب ، والهندسة المعمارية ، والعديد من الأشياء الأخرى. يجب أن تكون الأعلام توضيحية ذاتية. يمكنك سرد الأعلام مع python train.py -h
إذا كنت ترغب في حفظ نموذج مدرب والعودة إليه لاحقًا ، فما عليك سوى استخدام --save=FILELOC . بعد ذلك ، يمكنك تحميله لاحقًا باستخدام load=FILELOC . ملاحظة: إذا قمت بتحميل نموذج ، فأنت تقوم أيضًا بتحميل إعدادات المعلمات الخاصة به ، وبالتالي فإن -العلم --load يتجاوز أشياء مثل --size ، --gen_layers ، --gen_hidden_dim ، إلخ.
بشكل افتراضي ، يتم إعداد هذا الرمز للتدريب على بيانات Penn TreeBank ، والتي يتم تضمينها في الريبو في ptb/ Folder.
لإضافة مصدر بيانات جديد ، ما عليك سوى تطبيق مجموعة جديدة في util.py. تأكد من تعيين خاصية names لتكون قائمة تتضمن معرفًا فريدًا واحدًا على الأقل. بعد ذلك ، قم بتعيين --reader=ID ، واستخدم الأعلام --train ، --valid ، و --test للإشارة إلى مجموعة البيانات الخاصة بك. إذا لم يكن لديك بيانات مفصولة مسبقًا ، فما عليك سوى تعيين --train قم بتضمين علامة- --split_train لفصل البيانات الخاصة بك تلقائيًا إلى تقسيم القطار وصالح واختبار.
لتنفيذ نموذج جديد ، ما عليك سوى الانتقال إلى rnnlm.py ، قم بإنشاء فئة فرعية جديدة من SaveaBlerNnlm التي تنفذ الوظائف add_params و BuildLMGraph و BuildLMGraph_batch . يتم تضمين مثال. تأكد من تعيين خاصية name الخاصة بفصلك الجديد على معرف فريد ، ثم استخدم --arch=ID FLAG لإخبار الكود لاستخدام النموذج الجديد.
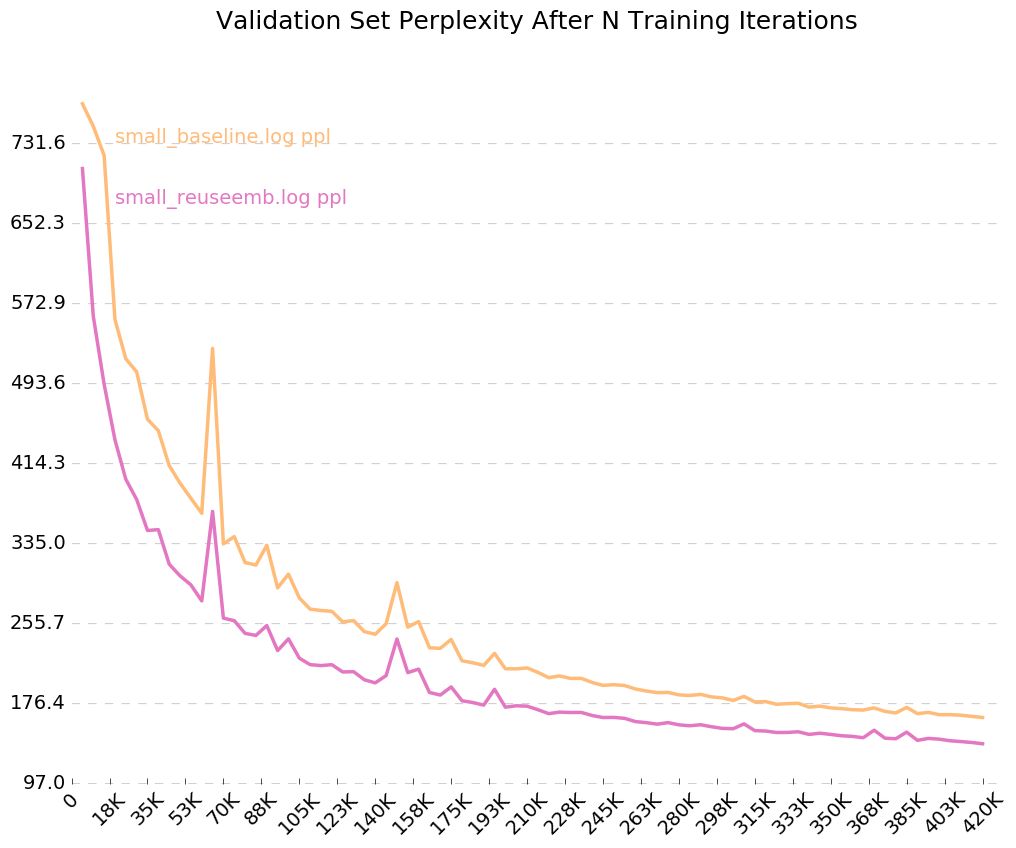
للحصول على رسم بياني نظيف لكيفية تدريب النموذج الخاص بك مع مرور الوقت ، اتصل بـ python visualize_log.py <filename> <filename>... لرسم ما يصل إلى 20 عملية تدريب. لإنشاء ملفات تسجيل الدخول المستخدمة كمدخلات لـ The Postimizer ، ما عليك سوى تضمين العلم --output=<filename> عند التدريب.
تأتي المعلمة --size في أربعة إعدادات: طبقة صغيرة (طبقة واحدة ، 128 معلمة لكل تضمين ، 128 عقدًا في الطبقة المخفية المتكررة) ، المتوسطة (طبقة 2 ، 256 إدخال خافت ، 256 خفية مخفية) ، كبيرة (2 ، 512 ، 512) ، وهائلة (2 ، 1024 ، 1024). يمكنك أيضًا تعيين المعلمات بشكل فردي ، مع الأعلام --gen_layers ، --gen_input_dim ، و --gen_hidden_dim .
دعنا نقول أننا أردنا اختبار [كيف تؤثر إعادة استخدام تضمينات الكلمات على أداء نموذج اللغة] (https://openreview.net/pdf؟id=r1apbsfle). سنستخدم مجموعة PTB ، لذلك لا داعي للقلق بشأن إعداد قارئ Corpus جديد - ما عليك سوى استخدام الافتراضي.
أولاً ، دعنا ندرب نموذجًا أساسيًا لـ 10 عصر:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(انتظر حوالي 2-3 ساعات)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
هذا أسوأ بكثير من الحيرة الأساسية التي تم الإبلاغ عنها في الورقة ، ولكن هذا لأننا نستخدم فقط نموذج LSTM عام كخط الأساس لدينا ، بدلاً من نموذج VD-LSTM الأكثر تعقيدًا ، ومع وجود عدد أقل من المعلمات.
بعد ذلك ، دعنا نعدل نموذج اللغة الأساسية لدينا لدمج إعادة استخدام تضمينات الكلمات. على سبيل المثال ، قمت بذلك في RNNLM.Py ، إنشاء فصل يسمى ReuseEmbeddingsRNNLM مع name = "reuse_emb" . الكود هو إلى حد كبير مجرد نسخة ولصق من نموذج خط الأساس أعلاه ، وتغيير حوالي 10 أسطر لدمج استئناف تضمينات الكلمات في التنبؤ بالمخرجات. الآن ، دعنا ندير هذه الاختبارات أيضًا:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(انتظر حوالي 2-3 ساعات)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
وهناك لدينا - إعادة استخدام التضمينات تعطينا انخفاضًا في الحيرة 26 نقطة. لطيف - جيد!
نظرًا لأننا نشغل العلامة لسجلات الإخراج ، --output=small_baseline.log و --output=small_reuseemb.log ، يمكننا تصور خطأ التحقق من الصحة لدينا بمرور الوقت أثناء التدريب باستخدام برنامج visualize_log.py :
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
إنتاج:
إذا كان لديك أي أسئلة ، فلا تتردد في ضربني: [email protected]


