boilerplate dynet rnn lm
1.0.0
Это код шаблона для быстрого и легко проходить эксперименты по языковому моделированию с земли. Код написан в версии Python Dynet Framework, которая может быть установлена с использованием этих инструкций.
У него также есть шаблон .en как зависимость токенизации, если вы используете читателя по умолчанию на уровне слов.
Для введения в модели языка RNN, как они работают, и некоторые классные демонстрации, пожалуйста, посмотрите на отличный пост Андрей Карпати в блоге: необоснованная эффективность повторяющихся нейронных сетей.
Чтобы обучить базовую модель RNN на Penn Treebank:
Char-level: python train.py
Уровень слов: python train.py --word_level
Для обучения базовой модели RNN на любом файле:
Char-level: python train.py --train=<filename> --reader=generic_char --split_train
Level Word: python train.py --train=<filename> --reader=generic_word --split_train
Оттуда есть куча флагов, которые вы можете настроить, чтобы настроить размер модели, выброса, архитектуры и многих других вещей. Флаги должны быть довольно самостоятельными. Вы можете перечислить флаги с помощью python train.py -h
Если вы хотите сохранить обученную модель и вернуться к ней позже, просто используйте флаг --save=FILELOC . Затем вы можете загрузить его позже с помощью флага load=FILELOC . ПРИМЕЧАНИЕ. Если вы загружаете модель, вы также загружаете его параметры, поэтому флаг --load переопределяет такие вещи, как --size , --gen_layers , --gen_hidden_dim и т. Д.
По умолчанию этот код настроен на обучение на данных Penn Treebank, которое включено в репо в папке ptb/ .
Чтобы добавить новый источник данных, просто реализуйте нового корпуса в Util.py. Убедитесь, что вы установили свойство names в список, который включает в себя хотя бы один уникальный идентификатор. Затем установите --reader=ID и используйте флаги --train , --valid и --test , чтобы указать на ваш набор данных. Если у вас нет предварительно разделенных данных, просто установите --train и включите флаг --split_train , чтобы ваши данные автоматически разделялись на поезд, допустимым и тестируемым разделениям.
Чтобы реализовать новую модель, просто зайдите в rnnlm.py, создайте новый подкласс Saveablernnlm, который реализует функции add_params , BuildLMGraph и BuildLMGraph_batch . Пример включен. Убедитесь, что вы установили свойство name вашего нового класса на уникальный идентификатор, а затем используйте флаг --arch=ID чтобы сообщить коду для использования вашей новой модели.
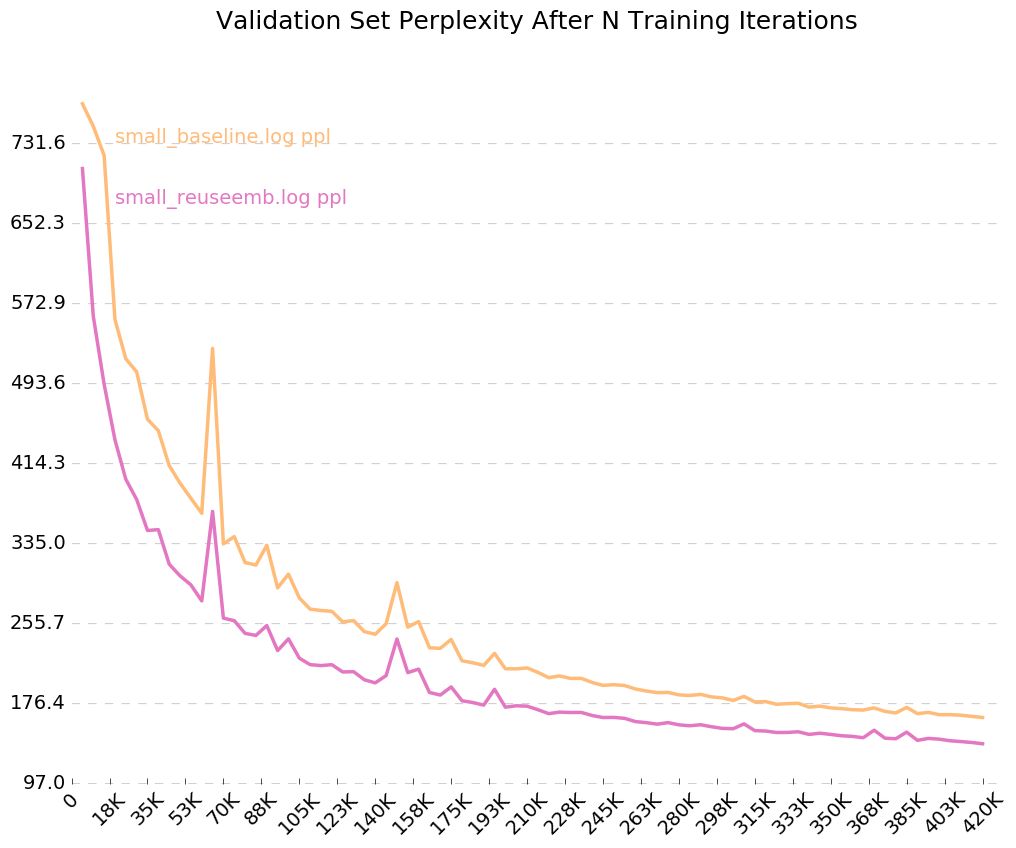
Чтобы получить чистый график того, как ваша модель тренируется с течением времени, позвоните в python visualize_log.py <filename> <filename>... чтобы запланировать до 20 тренировочных прогонов. Для генерации файлов журналов, используемых в качестве входных данных для визуализатора, просто включите флаг --output=<filename> при обучении.
Параметр --size поставляется в четырех настройках: небольшой (1 слой, 128 параметров на встроение, 128 узлов в рецидивирующем скрытом слое), средний (2 слоя, 256 входных DIM, 256 скрытый DIM), большой (2, 512, 512) и энмичный (2, 1024, 1024). Вы также можете установить параметры индивидуально, с флагами --gen_layers , --gen_input_dim и --gen_hidden_dim .
Допустим, мы хотели проверить [как повторное использование встроенных слов влияет на производительность языковой модели] (https://openreview.net/pdf?id=r1apbsfle). Мы будем использовать PTB Corpus, поэтому нам не нужно беспокоиться о настройке нового читателя Corpus - просто используйте по умолчанию.
Во -первых, давайте тренируем базовую модель для 10 эпох:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Подождите около 2-3 часов)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
Это намного хуже, чем базовая недоумение, о которой сообщалось в статье, но это потому, что мы просто используем общую модель LSTM в качестве нашей базовой линии, а не более сложную модель VD-LSTM, и с гораздо меньшим количеством параметров.
Далее, давайте изменим нашу базовую языковую модель, чтобы включить повторное использование встроенных слов. В качестве примера я сделал это в rnnlm.py, создав класс под названием ReuseEmbeddingsRNNLM с name = "reuse_emb" . Код-это в значительной степени просто копия и вставка базовой модели выше, изменяя около 10 строк, чтобы включить респонденцию встроенных слов в прогнозирование выходов. Теперь давайте проведем эти тесты тоже:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Подождите около 2-3 часов)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
И там у нас есть это - повторное использование встроенных вторжений дает нам снижение недоумения на 26 пунктов. Хороший!
Поскольку мы включили флаг для выходных журналов, --output=small_baseline.log и --output=small_reuseemb.log , мы можем визуализировать нашу ошибку проверки с течением времени во время обучения с помощью включенного сценария visualize_log.py :
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Производство:
Если у вас есть какие -либо вопросы, пожалуйста, не стесняйтесь поразить меня: [email protected]


