boilerplate dynet rnn lm
1.0.0
이것은 지상에서 언어 모델링에 대한 실험을 빠르고 쉽게 얻을 수있는 보일러 플레이트 코드입니다. 이 코드는 Python 버전의 Dynet Framework로 작성 되었으며이 지침을 사용하여 설치할 수 있습니다.
또한 워드 레벨에서 기본 리더를 사용하는 경우 토큰 화의 종속성으로 패턴이 있습니다.
RNN 언어 모델, 작동 방식 및 멋진 데모에 대한 소개를 보려면 Andrej Karpathy의 훌륭한 블로그 게시물 : 재발 성 신경망의 불합리한 효과를 살펴보십시오.
Penn TreeBank에서 기준선 RNN 모델을 훈련시키기 위해 :
숯불 : python train.py
단어 수준 : python train.py --word_level
모든 파일에서 기준 RNN 모델을 훈련시키기 위해 :
char-level : python train.py --train=<filename> --reader=generic_char --split_train
Word-level : python train.py --train=<filename> --reader=generic_word --split_train
거기에서 모델의 크기, 드롭 아웃, 아키텍처 및 기타 여러 가지를 조정하도록 설정할 수있는 깃발이 많이 있습니다. 깃발은 꽤 자기 설명이어야합니다. python train.py -h 로 깃발을 나열 할 수 있습니다
훈련 된 모델을 저장하고 나중에 다시 오려면 --save=FILELOC 플래그를 사용하십시오. 그런 다음 나중에 load=FILELOC 플래그로로드 할 수 있습니다. 참고 : 모델을로드하면 매개 변수 설정을로드하므로 --load 플래그는 --size , --gen_layers , --gen_hidden_dim 등과 같은 것을 무시합니다.
기본적 으로이 코드는 PNN TreeBank 데이터를 훈련하도록 설정되어 있으며 ptb/ 폴더의 Repo에 포함되어 있습니다.
새로운 데이터 소스를 추가하려면 Util.py에서 새로운 CorpusReader를 구현하십시오. names 속성을 하나 이상의 고유 ID를 포함하는 목록으로 설정해야합니다. 그런 다음 --reader=ID 설정하고 --train , --valid 및 --test 플래그를 사용하여 데이터 세트를 가리 킵니다. 사전 분리 된 데이터가없는 경우 --train 트레이닝하고 --split_train 플래그를 포함시키기 위해 데이터를 자동으로 열차로 분리하고 유효하며 테스트 스플릿을 포함하도록하십시오.
새 모델을 구현하려면 RNNLM.Py로 이동하여 add_params , BuildLMGraph 및 BuildLMGraph_batch 함수를 구현하는 새 서브 클래스 서브 클래스를 만듭니다. 예가 포함되어 있습니다. 새 클래스의 name 속성을 고유 한 ID로 설정 한 다음 --arch=ID 플래그를 사용하여 코드에 새 모델을 사용하도록 지시하십시오.
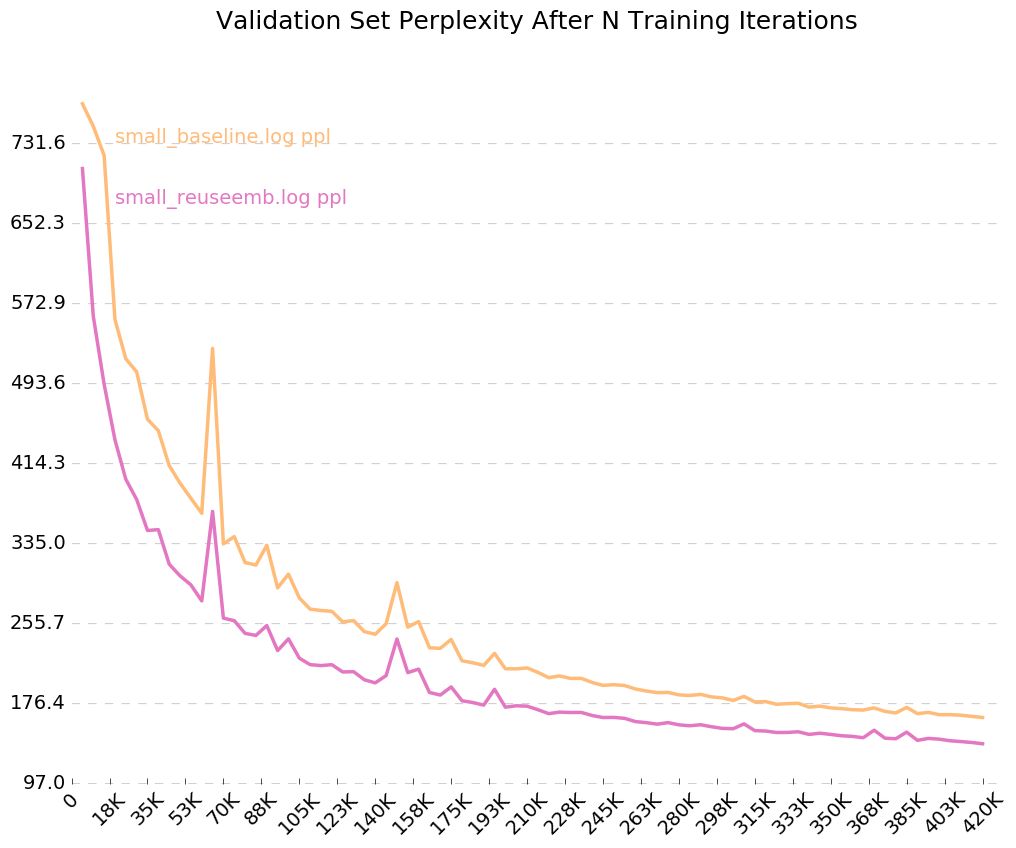
시간이 지남에 따라 모델이 어떻게 훈련하는지에 대한 깨끗한 그래프를 얻으려면 python visualize_log.py <filename> <filename>... 에 전화하십시오. 비주얼 라이저의 입력으로 사용되는 로그 파일을 생성하려면 훈련시 --output=<filename> 플래그를 포함시킵니다.
--size 매개 변수는 4 가지 설정으로 제공됩니다 : 작은 (1 층, 임베딩 당 128 개의 매개 변수, 재발 성 숨겨진 층의 128 개의 노드), 중간 (2 층, 256 개의 입력 희미, 256 개의 숨겨진 희미), Large (2, 512, 512) 및 ernormous (2, 1024, 1024)로 제공됩니다. 플래그 --gen_layers , --gen_input_dim 및 --gen_hidden_dim 으로 매개 변수를 개별적으로 설정할 수도 있습니다.
[Word Embedding의 재사용이 언어 모델의 성능에 미치는 영향] (https://openreview.net/pdf?id=r1apbsfle)을 테스트하고 싶다고 가정 해 봅시다. 우리는 PTB 코퍼스를 사용할 것이므로 새로운 코퍼스 리더를 설정하는 것에 대해 걱정할 필요가 없습니다. 기본값 만 사용하십시오.
먼저 10 개의 에포크에 대한 기준 모델을 훈련합시다.
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(약 2-3 시간 동안 기다리십시오)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
이는 논문에보고 된 기준의 당혹감보다 훨씬 나쁩니다. 그러나 우리는 일반적인 LSTM 모델을보다 복잡한 VD-LSTM 모델보다는 기준선으로 사용하고 매개 변수가 훨씬 적기 때문입니다.
다음으로, 단어 임베딩의 재사용을 통합하기 위해 기준 언어 모델을 수정합시다. 예를 들어, rnnlm.py 에서이 작업을 수행하여 name = "reuse_emb" 라는 ReuseEmbeddingsRNNLM 이라는 클래스를 만듭니다. 이 코드는 위의 기준선 모델의 복사 및 붙여 넣기 일뿐 아니라 단어 임베딩을 출력 예측에 통합하기 위해 약 10 줄을 변경합니다. 이제 그 테스트도 실행합시다.
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(약 2-3 시간 동안 기다리십시오)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
그리고 거기에 우리는 그것을 가지고 있습니다 - 임베딩의 재사용은 우리에게 26 점의 당황을 줄입니다. 멋진!
출력 로그, --output=small_baseline.log 및 --output=small_reuseemb.log 에 대한 플래그를 켰으므로 visualize_log.py 스크립트를 사용하여 훈련 중에 시간이 지남에 따라 유효성 검사 오류를 시각화 할 수 있습니다.
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
생산 :
궁금한 점이 있으시면 언제든지 [email protected]를 치르십시오.


