boilerplate dynet rnn lm
1.0.0
Ini adalah kode boilerplate untuk dengan cepat dan mudah mendapatkan eksperimen pada pemodelan bahasa dari tanah. Kode ini ditulis dalam versi Python dari kerangka kerja Dynet, yang dapat diinstal menggunakan instruksi ini.
Ini juga memiliki pola.
Untuk pengantar model bahasa RNN, cara kerjanya, dan beberapa demo keren, silakan lihat posting blog Andrej Karpathy yang luar biasa: efektivitas jaringan saraf berulang yang tidak masuk akal.
Untuk melatih model RNN baseline di Penn Treebank:
Level Char: python train.py
Level kata: python train.py --word_level
Untuk melatih model RNN dasar, pada file apa pun:
Level char: python train.py --train=<filename> --reader=generic_char --split_train
Level kata: python train.py --train=<filename> --reader=generic_word --split_train
Dari sana, ada banyak bendera yang dapat Anda tetapkan untuk menyesuaikan ukuran model, putus sekolah, arsitektur, dan banyak hal lainnya. Bendera harus cukup jelas. Anda dapat mendaftarkan bendera dengan python train.py -h
Jika Anda ingin menyimpan model terlatih dan kembali lagi nanti, cukup gunakan flag --save=FILELOC . Kemudian, Anda dapat memuatnya nanti dengan bendera load=FILELOC . Catatan: Jika Anda memuat model, Anda juga memuat pengaturan parameternya, sehingga bendera --load mengesampingkan hal -hal seperti --size , --gen_layers , --gen_hidden_dim , dll.
Secara default, kode ini diatur untuk berlatih pada data Penn Treebank, yang termasuk dalam repo di ptb/ folder.
Untuk menambahkan sumber data baru, cukup terapkan corpusreader baru di util.py. Pastikan Anda mengatur properti names menjadi daftar yang mencakup setidaknya satu ID unik. Kemudian, atur --reader=ID , dan gunakan -bendera --train , --valid , dan --test untuk menunjuk ke set data Anda. Jika Anda tidak memiliki data yang telah dipisahkan sebelumnya, cukup atur --train dan sertakan flag --split_train agar data Anda dipisahkan secara otomatis menjadi kereta, valid, dan pemisahan tes.
Untuk mengimplementasikan model baru, cukup masuk ke rnnlm.py, buat subkelas baru SaveAblernnlm yang mengimplementasikan fungsi add_params , BuildLMGraph , dan BuildLMGraph_batch . Contoh disertakan. Pastikan Anda mengatur properti name kelas baru Anda ke ID unik, dan kemudian gunakan flag --arch=ID untuk memberi tahu kode untuk menggunakan model baru Anda.
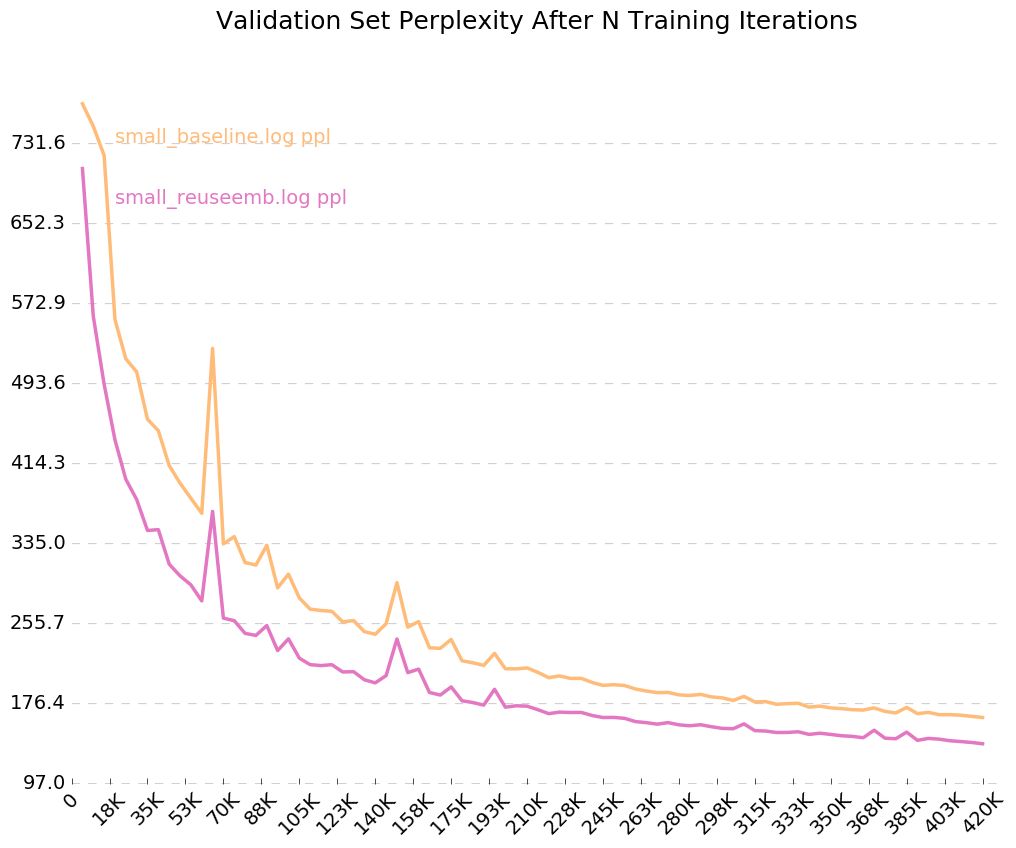
Untuk mendapatkan grafik yang bersih tentang bagaimana model Anda berlatih dari waktu ke waktu, hubungi python visualize_log.py <filename> <filename>... untuk merencanakan hingga 20 pelatihan berjalan. Untuk menghasilkan logfile yang digunakan sebagai input untuk visualisasi, cukup sertakan -flag --output=<filename> saat pelatihan.
Parameter --size hadir dalam empat pengaturan: kecil (1 lapisan, 128 parameter per embedding, 128 node di lapisan tersembunyi berulang), medium (2 lapisan, 256 redup input, 256 redup tersembunyi), besar (2, 512, 512), dan besar (2, 1024, 1024). Anda juga dapat mengatur parameter secara individual, dengan flags --gen_layers , --gen_input_dim , dan --gen_hidden_dim .
Katakanlah kami ingin menguji [bagaimana penggunaan kembali kata embeddings mempengaruhi kinerja model bahasa] (https://openreview.net/pdf?id=r1apbsfle). Kami akan menggunakan PTB Corpus, jadi kami tidak perlu khawatir tentang menyiapkan pembaca corpus baru - cukup gunakan default.
Pertama, mari kita latih model baseline untuk 10 zaman:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Tunggu sekitar 2-3 jam)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
Ini jauh lebih buruk daripada kebingungan awal yang dilaporkan dalam kertas, tetapi itu karena kami hanya menggunakan model LSTM generik sebagai baseline kami, daripada model VD-LSTM yang lebih kompleks, dan dengan lebih banyak parameter.
Selanjutnya, mari kita ubah model bahasa dasar kami untuk menggabungkan penggunaan kembali kata embeddings. Sebagai contoh, saya telah melakukan ini di rnnlm.py, membuat kelas yang disebut ReuseEmbeddingsRNNLM dengan name = "reuse_emb" . Kode ini cukup banyak hanyalah copy-and-paste dari model baseline di atas, mengubah sekitar 10 baris untuk memasukkan kembali embeddings kata ke dalam prediksi output. Sekarang, mari kita jalankan tes itu juga:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Tunggu sekitar 2-3 jam)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
Dan begitulah - penggunaan kembali embeddings memberi kita penurunan 26 poin dalam kebingungan. Bagus!
Karena kami menyalakan bendera untuk log output, --output=small_baseline.log dan --output=small_reuseemb.log , kami dapat memvisualisasikan kesalahan validasi kami dari waktu ke waktu selama pelatihan dengan menggunakan skrip visualize_log.py yang disertakan:
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Menghasilkan:
Jika Anda memiliki pertanyaan, jangan ragu untuk memukul saya: [email protected]


