boilerplate dynet rnn lm
1.0.0
Il s'agit d'un code de passe-partout pour obtenir rapidement et facilement des expériences sur la modélisation du langage hors du sol. Le code est écrit dans la version Python du framework Dynet, qui peut être installé à l'aide de ces instructions.
Il a également un modèle. En tant que dépendance de la tokenisation, si vous utilisez le lecteur par défaut au niveau des mots.
Pour une introduction aux modèles de langue RNN, comment ils fonctionnent et quelques démos sympas, veuillez jeter un œil à l'excellent article de blog d'Andrej Karpathy: l'efficacité déraisonnable des réseaux de neurones récurrents.
Pour entraîner un modèle RNN de base sur la penn arbre:
Char-Level: python train.py
Niveau de mot: python train.py --word_level
Pour former un modèle RNN de base, sur n'importe quel fichier:
Char-Level: python train.py --train=<filename> --reader=generic_char --split_train
Niveau de mot: python train.py --train=<filename> --reader=generic_word --split_train
De là, il y a un tas de drapeaux que vous pouvez définir pour ajuster la taille du modèle, le décrochage, l'architecture et bien d'autres choses. Les drapeaux devraient être assez explicatifs. Vous pouvez répertorier les drapeaux avec python train.py -h
Si vous souhaitez enregistrer un modèle formé et y revenir plus tard, utilisez simplement l'indicateur --save=FILELOC . Ensuite, vous pouvez le charger plus tard avec l'indicateur load=FILELOC . Remarque: Si vous chargez un modèle, vous chargez également ses paramètres de paramètre, donc l'indicateur --load remplace des choses comme --size , --gen_layers , --gen_hidden_dim , etc.
Par défaut, ce code est configuré pour s'entraîner sur les données de Penn Treebank, qui est incluse dans le référentiel dans le dossier ptb/ .
Pour ajouter une nouvelle source de données, implémentez simplement un nouveau CorpusReader dans util.py. Assurez-vous que vous définissez la propriété names pour être une liste qui comprend au moins un ID unique. Ensuite, définissez le --reader=ID et utilisez les indicateurs --train , --valid et --test pour pointer votre ensemble de données. Si vous n'avez pas de données pré-séparées, définissez simplement --train et incluez l'indicateur --split_train pour que vos données soient automatiquement séparées en train, valide et test.
Pour implémenter un nouveau modèle, allez simplement dans RNNLM.PY, créez une nouvelle sous-classe de SaveABLernnlm qui implémente les fonctions add_params , BuildLMGraph et BuildLMGraph_batch . Un exemple est inclus. Assurez-vous de définir la propriété name de votre nouvelle classe sur un ID unique, puis utilisez l'indicateur --arch=ID pour dire au code d'utiliser votre nouveau modèle.
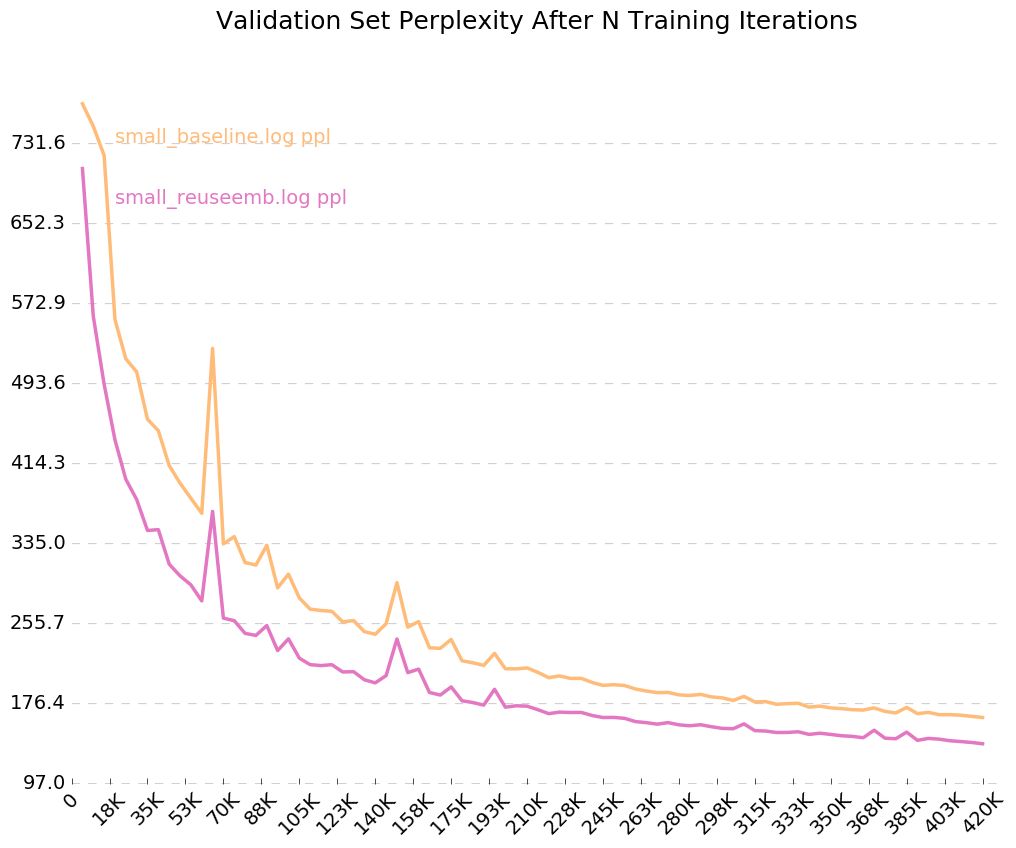
Pour obtenir un graphique propre de la façon dont votre modèle s'entraîne au fil du temps, appelez python visualize_log.py <filename> <filename>... pour tracer jusqu'à 20 courses de formation. Le pour générer les fichiers de journaux utilisés comme entrée pour le visualiseur, incluez simplement le drapeau --output=<filename> lors de la formation.
Le paramètre --size est disponible en quatre paramètres: petite (1 couche, 128 paramètres par intégration, 128 nœuds dans la couche cachée récurrente), moyenne (2 couches, 256 DIM d'entrée, 256 DIM caché), grande (2, 512, 512) et énorme (2, 1024, 1024). Vous pouvez également définir les paramètres individuellement, avec les drapeaux --gen_layers , --gen_input_dim et --gen_hidden_dim .
Disons que nous voulions tester [comment la réutilisation des intégres de mots affecte les performances d'un modèle de langue] (https://openreview.net/pdf?id=r1apbsfle). Nous utiliserons le corpus PTB, nous n'avons donc pas à nous soucier de la configuration d'un nouveau lecteur de corpus - utilisez simplement la valeur par défaut.
Tout d'abord, formons un modèle de base pour 10 époques:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Attendez environ 2-3 heures)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
C'est bien pire que la perplexité de base rapportée dans l'article, mais c'est parce que nous utilisons simplement un modèle LSTM générique comme notre ligne de base, plutôt que le modèle VD-LSTM plus complexe, et avec beaucoup moins de paramètres.
Ensuite, modifions notre modèle de langue de base pour incorporer la réutilisation des incorporations de mots. Par exemple, je l'ai fait dans rnnlm.py, créant une classe appelée ReuseEmbeddingsRNNLM avec name = "reuse_emb" . Le code est à peu près juste une copie et un casson du modèle de base ci-dessus, modifiant environ 10 lignes pour incorporer la résume des intégres de mots dans la prédiction des sorties. Maintenant, faisons également ces tests:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Attendez environ 2-3 heures)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
Et là, nous l'avons - la réutilisation des intérêts nous donne une diminution de la perplexité de 26 points. Bon!
Puisque nous avons activé l'indicateur pour les journaux de sortie, --output=small_baseline.log et --output=small_reuseemb.log , nous pouvons visualiser notre erreur de validation au fil du temps pendant la formation en utilisant le script visualize_log.py inclus:
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Production:
Si vous avez des questions, n'hésitez pas à me frapper: [email protected]


