boilerplate dynet rnn lm
1.0.0
Este es el código de Boilerplate para obtener experimentos rápidos y fácilmente en el modelado de lenguaje fuera del suelo. El código está escrito en la versión de Python de Dynet Framework, que se puede instalar utilizando estas instrucciones.
También tiene patrón.en como dependencia de la tokenización, si está utilizando el lector predeterminado a nivel de palabra.
Para una introducción a los modelos de idiomas RNN, cómo funcionan y algunas demostraciones geniales, eche un vistazo a la excelente publicación de blog de Andrej Karpathy: la efectividad irrazonable de las redes neuronales recurrentes.
Para entrenar un modelo RNN de línea de base en el Penn Treebank:
Char-Level: python train.py
Level de palabras: python train.py --word_level
Para entrenar un modelo de referencia RNN, en cualquier archivo:
Char-nivel: python train.py --train=<filename> --reader=generic_char --split_train
Level de palabras: python train.py --train=<filename> --reader=generic_word --split_train
A partir de ahí, hay un montón de banderas que puede configurar para ajustar el tamaño del modelo, el desanimo, la arquitectura y muchas otras cosas. Las banderas deberían ser bastante explicativas. Puede enumerar las banderas con python train.py -h
Si desea guardar un modelo entrenado y volver a él más tarde, simplemente use el indicador --save=FILELOC . Luego, puede cargarlo más tarde con el indicador load=FILELOC . Nota: Si carga un modelo, también carga su configuración de parámetros, por lo que el indicador --load anula cosas como --size , --gen_layers , --gen_hidden_dim , etc.
Por defecto, este código está configurado para entrenar en los datos de Penn Trebank, que se incluye en el repositorio en la carpeta ptb/ .
Para agregar una nueva fuente de datos, simplemente implementa un nuevo CorpusReader en Util.py. Asegúrese de establecer la propiedad names para que sea una lista que incluya al menos una identificación única. Luego, establezca los --reader=ID y use los indicadores --train , --valid y --test para apuntar a su conjunto de datos. Si no tiene datos pre-separados, simplemente establezca --train e incluya el indicador --split_train para que sus datos se separen automáticamente en las divisiones de trenes, válidas y de prueba.
Para implementar un nuevo modelo, simplemente ingrese a rnnlm.py, cree una nueva subclase de SaveLernnlm que implementa las funciones add_params , BuildLMGraph y BuildLMGraph_batch . Se incluye un ejemplo. Asegúrese de establecer la propiedad name de su nueva clase en una identificación única, y luego use el indicador --arch=ID para decirle al código que use su nuevo modelo.
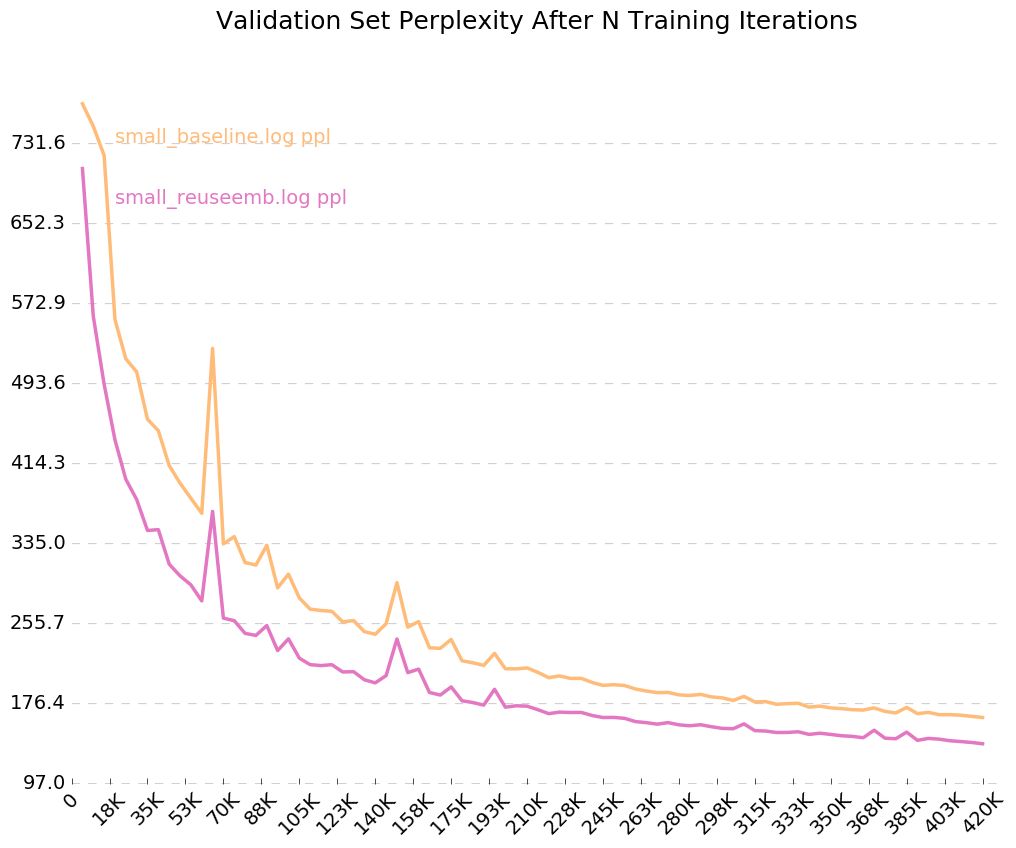
Para obtener un gráfico limpio de cómo su modelo está entrenando con el tiempo, llame python visualize_log.py <filename> <filename>... para trazar hasta 20 ejecuciones de entrenamiento. Para generar los archivos de registro utilizados como entrada para el visualizador, simplemente incluya el indicador --output=<filename> al entrenar.
El parámetro --size viene en cuatro configuraciones: pequeñas (1 capa, 128 parámetros por incrustación, 128 nodos en la capa oculta recurrente), medio (2 capas, 256 de entrada tenue, 256 tenues ocultos), grandes (2, 512, 512) y enormes (2, 1024, 1024). También puede establecer los parámetros individualmente, con las banderas --gen_layers , --gen_input_dim y --gen_hidden_dim .
Digamos que queríamos probar [cómo la reutilización de las incrustaciones de palabras afecta el rendimiento de un modelo de idioma] (https://openreview.net/pdf?id=r1apbsfle). Usaremos el Corpus PTB, por lo que no necesitamos preocuparnos por configurar un nuevo lector de corpus, solo use el valor predeterminado.
Primero, entrenemos un modelo de referencia para 10 épocas:
python train.py --dynet-mem 3000 --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_baseline.log
(Espere alrededor de 2-3 horas)
python train.py --dynet-mem 3000 --word_level --minibatch_size=24 --load=small_baseline.model --evaluate
[Test TEST] Loss: 5.0651960628 Perplexity: 158.411497631 Time: 20.4854779243
Esto es mucho peor que la perplejidad de referencia informada en el documento, pero eso se debe a que solo estamos usando un modelo LSTM genérico como nuestra línea de base, en lugar del modelo VD-LSTM más complejo, y con muchos menos parámetros.
A continuación, modifiquemos nuestro modelo de lenguaje de línea de base para incorporar la reutilización de incrustaciones de palabras. Como ejemplo, he hecho esto en rnnlm.py, creando una clase llamada ReuseEmbeddingsRNNLM con name = "reuse_emb" . El código es más o menos una copia y pasta del modelo de línea de base anterior, cambiando alrededor de 10 líneas para incorporar la reanudación de los incrustaciones de palabras en la predicción de las salidas. Ahora, ejecutemos esas pruebas también:
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --size=small --minibatch_size=24 --save=small_reuseemb.model --output=small_reuseemb.log
(Espere alrededor de 2-3 horas)
python train.py --dynet-mem 3000 --arch=reuse_emb --word_level --minibatch_size=24 --load=small_reuseemb.model --evaluate
[Test TEST] Loss: 4.88281608367 Perplexity: 132.001869276 Time: 20.2611508369
Y allí lo tenemos: la reutilización de incrustaciones nos da una disminución de 26 puntos en perplejidad. ¡Lindo!
Dado que encendimos el indicador para registros de salida, --output=small_baseline.log y --output=small_reuseemb.log , podemos visualizar nuestro error de validación a lo largo del tiempo durante el entrenamiento utilizando el script de visualize_log.py incluido:
python visualize_log.py small_baseline.log small_baseline.log --output=compare_baseline_reuseemb.png
Productor:
Si tiene alguna pregunta, no dude en golpearme: [email protected]


