Attention Sink
1.0.0
[arxiv]
在这项工作中,我们研究了LM预训练中的优化,数据分布,损失函数和模型结构如何影响注意力下降的出现。
我们在具有40GB内存的A100 GPU上运行所有实验。我们遵循Tinyllama和Regmix准备环境:
我们希望您安装了CUDA 11.8。
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' 注意:截至2023/09/02,Xformers不能为火炬2.1提供预制的二进制文件。您必须从源头构建它。
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
安装其他依赖关系。构建Xformers/flash注意力可能需要> = 5分钟。不用担心该过程似乎停滞不前或终端打印出许多警告。
在训练模型之前,您需要预处理数据。我们提供易于使用的脚本,用于预处理数据。您可以使用以下命令来预处理数据:
cd preprocess
bash run_preprocess.sh默认情况下,您将首先从拥抱面下载regmix-data-sample ,然后预处理数据。 JSONL数据将保存在preprocess/sail/regmix-data-sample目录中,并且预处理数据将保存在datasets/lit_dataset_regmix目录中。这包括大约5B令牌,并占用约20GB的磁盘空间。
默认情况下,我们使用WANDB收集数据,以避免在本地机器上节省大量的小型型号和日志。如果要使用wandb,则需要在wandb上创建一个帐户并获取API密钥。然后,您应该在scripts/*.sh :中设置以下环境变量:
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY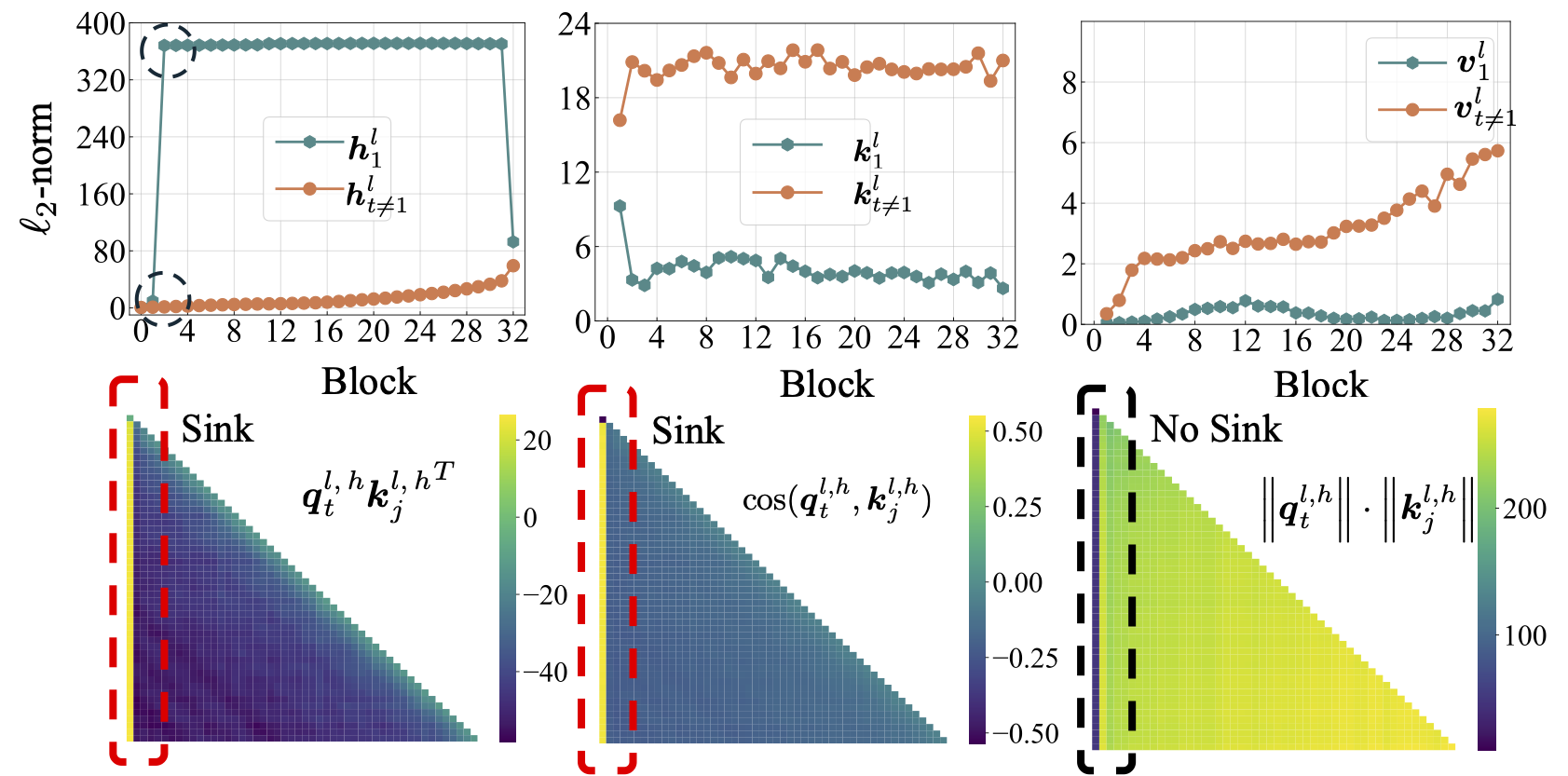
我们首先对开源LMS进行全面研究,包括Llama2,Llama3,Mismtral,GPT2,Pythia和Opt。我们提供脚本来计算上述LMS的注意下沉指标:
python eval_sink_open_source.py我们还提供了脚本来计算隐藏状态,密钥和值的L2-norm:
python eval_activations_open_source.py我们注意到,我们在一个脚本中包括所有30个开源LMS的评估,这可能需要很长时间才能下载模型。请在eval_sink_open_source.py中修改57-63行或eval_activations_open_source.py中的第104-110行,以评估特定的LMS。
我们在5B令牌数据上预先培训一系列的Llama模型,以研究LM训练前训练中的优化,数据,损耗函数和模型成绩如何影响注意力下水道。
不同的设置可能会导致不同的内存使用情况,并且服务设置与闪光注意力不符。我们可能具有不同的代码库,用于在文件夹lit_gpt中进行预训练和推断。我们欢迎社区的贡献使代码更加简洁,效率。
除非额外的说明,否则遵循的实验需要至少40 GB内存的4个GPU。请修改configs/*.yaml中的微批量尺寸。
运行默认设置:
bash scripts/run_defaults_60m.sh最终检查点保存在checkpoints/tinyllama_60M/iter-020000-ckpt.pth 。
我们提供所有脚本以在主要论文中重现我们的实验结果。
优化:请参阅scripts/optimization.md 。外卖:1。有效训练LMS之后,注意下沉出现。 2。注意下沉率在接受较小学习率的LMS中显而易见。
数据分布:请参阅scripts/data_distribution.md 。外卖:1。在LMS接受足够的培训数据训练后,注意下水道出现。 2。如果修改数据分布,则可以将注意点转移到其他位置,而不是第一个令牌。
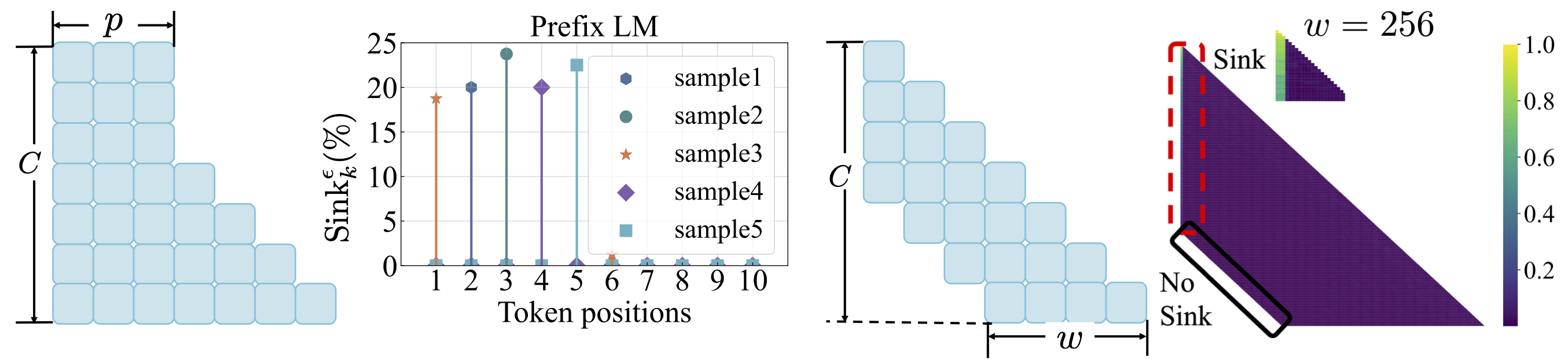
损失功能:请参阅scripts/loss_function.md 。外卖:1。重量衰减鼓励注意力下降。 2。使用前缀语言建模,注意下沉出现在前缀令牌中,而不是仅第一个令牌。 3。随着窗户关注的转移,注意下沉出现在绝对上,而不是相对的第一个令牌上。较小的窗户大小可防止注意力下降。
scripts/model_architecture.md 。外卖:1。位置嵌入,FFN设计,LN位置和多头设计不会影响注意流的出现。 2。注意水槽的作用更像是关键偏见,存储额外的关注,同时不促进价值计算。 3。放松令牌对注意力评分的内在依赖性时,注意力下降不会在LMS中出现。 

最后,我们将模型大小扩展到1B参数,发现仍然没有注意力下沉和大量激活。默认情况下,我们使用8个GPU运行以下脚本
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.sh如果您发现此项目在您的研究中有用,请考虑引用我们的论文:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
我们的代码是根据Tinyllama和Regmix开发的。


