Attention Sink
1.0.0
[Arxiv]
In dieser Arbeit untersuchen wir, wie Optimierung, Datenverteilung, Verlustfunktion und Modellarchitektur in der LM-Voraussetzung die Entstehung der Aufmerksamkeits sinkt.
Wir führen alle unsere Experimente auf A100 GPUs mit 40 GB Speicher durch. Wir folgen Tinyllama und Regmix, um die Umgebungen vorzubereiten:
Wir erwarten, dass Sie CUDA 11.8 installiert haben.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' HINWEIS: Ab 2023/09/02 liefert Xformers keine vorgefertigten Binärdateien für Torch 2.1. Sie müssen es aus der Quelle bauen.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
andere Abhängigkeiten installieren. Es kann> = 5 Minuten dauern, um Xformers/Flash-Assonierung zu erstellen. Machen Sie sich keine Sorgen, wenn der Vorgang scheinbar stagniert oder das Terminal viele Warnungen ausdruckt.
Vor dem Training des Modells müssen Sie die Daten vorbereiten. Wir bieten das benutzerfreundliche Skript zur Vorverarbeitung der Daten. Sie können den folgenden Befehl verwenden, um die Daten vorzubereiten:
cd preprocess
bash run_preprocess.sh Standardmäßig laden Sie zuerst die regmix-data-sample aus dem Umarmungsface herunter und werden dann die Daten vorab. Die JSONL-Daten werden im Verzeichnis preprocess/sail/regmix-data-sample gespeichert, und die vorverarbeiteten Daten werden im Verzeichnis datasets/lit_dataset_regmix gespeichert. Dies beinhaltet ungefähr 5B -Token und benötigt etwa 20 GB Scheibenplatz.
Standardmäßig verwenden wir den Wandb zum Sammeln der Daten, um massive kleine Modelle und Protokolle auf der lokalen Maschine zu vermeiden. Wenn Sie den Wandb verwenden möchten, müssen Sie ein Konto auf dem Wandb erstellen und den API -Schlüssel erhalten. Anschließend sollten Sie die folgende Umgebungsvariable in scripts/*.sh festlegen:
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY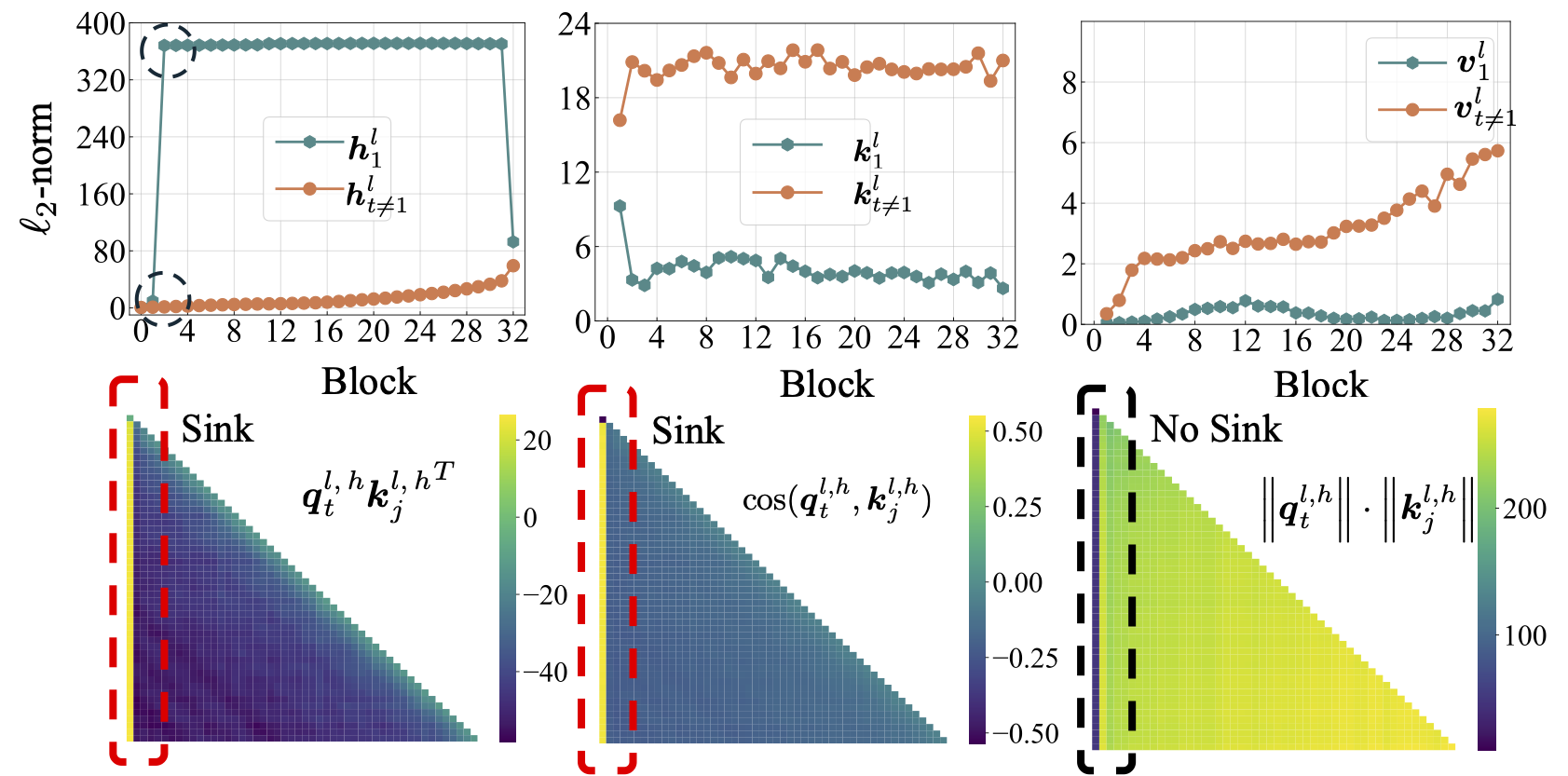
Wir führen zunächst eine umfassende Studie über Open-Sourced-LMS durch, darunter Lama2, Lama3, Mistral, GPT2, Pythia und Opt. Wir stellen das Skript zur Verfügung, um die Aufmerksamkeitssenssensmetrik für das obige LMS zu berechnen:
python eval_sink_open_source.pyWir bieten auch das Skript zur Berechnung des L2-Norms versteckter Zustände, Schlüssel und Werte:
python eval_activations_open_source.py Wir stellen fest, dass wir die Bewertungen aller 30 Open-Sourced-LMs in ein einzelnes Skript einbeziehen, was das Herunterladen von Modellen möglicherweise lange dauern kann. Bitte ändern Sie Zeile 57-63 in eval_sink_open_source.py oder Zeile 104-110 in eval_activations_open_source.py , um bestimmte LMS zu bewerten.
Wir haben eine Reihe von Lama-Modellen zu 5B-Token-Daten vorverträgt, um zu untersuchen, wie Optimierung, Daten, Verlustfunktion und Modell-Achitecture in der LM-Vorausbildung die Aufmerksamkeitssenke beeinflussen.
Verschiedene Setups können zu unterschiedlichen Speicherverbrauch führen, und Diener -Setups sind nicht gut mit der Aufmerksamkeit der Flash -Aufmerksamkeit kompatibel. Möglicherweise haben wir unterschiedliche Codebasen für die Modellvorab- und Inferenz im Ordner lit_gpt . Wir begrüßen die Beiträge der Community, um den Code präzise und effizienter zu gestalten.
Sofern nicht zusätzliche Anweisungen, benötigen die folgenden Experimente 4 GPUs mit mindestens 40 GB Speicher. Bitte ändern Sie die Micro -Stapelgröße in configs/*.yaml .
Führen Sie das Standard -Setup aus:
bash scripts/run_defaults_60m.sh Der endgültige Checkpoint wird unter checkpoints/tinyllama_60M/iter-020000-ckpt.pth gespeichert.
Wir stellen alle Skripte zur Verfügung, um unsere experimentellen Ergebnisse im Hauptpapier zu reproduzieren.
Optimierung: Siehe scripts/optimization.md . Imbiss: 1. Aufmerksamkeitssenke entsteht, nachdem LMs effektiv trainiert wurden. 2. Die Aufmerksamkeits sinkt, scheint in LMs mit kleinen Lernraten weniger offensichtlich zu sein.
Datenverteilung: Siehe scripts/data_distribution.md . TakeAways: 1. Aufmerksamkeitssenke entsteht, nachdem LMS nach ausreichenden Trainingsdaten geschult wurde. 2. Die Aufmerksamkeitssenke kann eher auf andere Positionen als an das erste Token verlagert werden, wenn die Datenverteilung geändert wird.
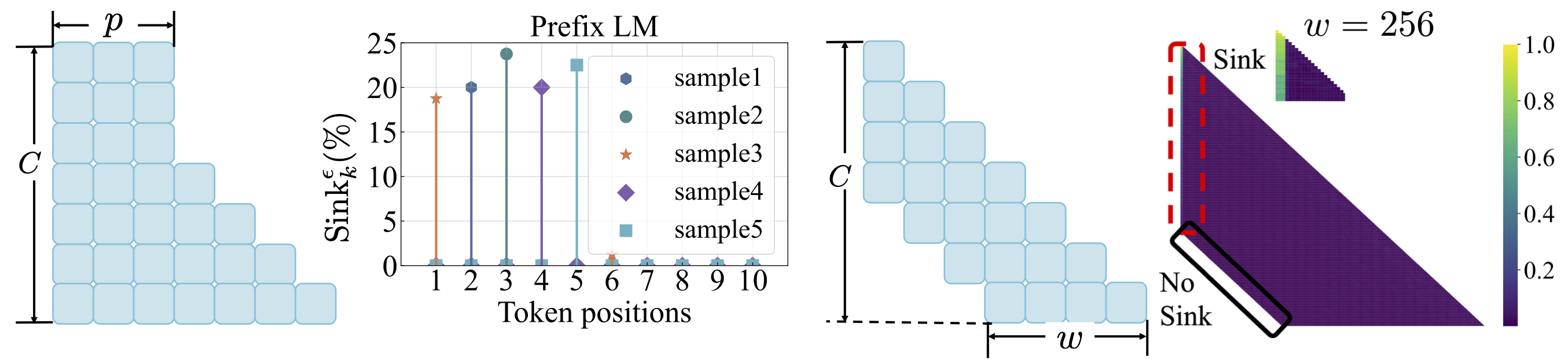
Verlustfunktion: Siehe scripts/loss_function.md . Imbiss: 1. Gewichtsverfall fördert die Entstehung der Aufmerksamkeits sinkend. 2. Mit der Präfix -Sprachmodellierung erscheint die Aufmerksamkeitssöhne unter den Präfix -Token und nicht unter dem ersten Token. 3. Mit der Aufmerksamkeit des Fensters erscheint die Aufmerksamkeits sinkt, dass das Absolute, nicht auf dem relativen ersten Token. Eine kleinere Fenstergröße verhindert die Entstehung der Aufmerksamkeits sinkt.
scripts/model_architecture.md . Imbetten: 1. Positionseinbettung, FFN-Design, LN-Standort und mehrköpfiges Design beeinflussen keinen Einfluss auf die Entstehung der Aufmerksamkeitssenke. 2. Aufmerksamkeits sinkend wirkt eher wie wichtige Vorurteile, speichert zusätzliche Aufmerksamkeit und trägt inzwischen nicht zur Wertberechnung bei. 3. Wenn die innere Abhängigkeit von Tokens von der Aufmerksamkeitsbewertungen entspannt, entsteht in LMS nicht. 

Schließlich skalieren wir die Modellgröße auf 1B -Parameter und finden immer noch keine Aufmerksamkeitssenke und massive Aktivierungen. Standardmäßig verwenden wir 8 GPUs, um die folgenden Skripte auszuführen
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shWenn Sie dieses Projekt in Ihrer Forschung nützlich finden, sollten Sie in unserem Papier zitieren:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Unsere Codes werden basierend auf Tinyllama und Regmix entwickelt.


