Attention Sink
1.0.0
[arXiv]
Dans ce travail, nous étudions comment l'optimisation, la distribution des données, la fonction de perte et l'architecture du modèle dans la pré-formation LM influence l'émergence de l'évier d'attention.
Nous exécutons toutes nos expériences sur des GPU A100 avec 40 Go de mémoire. Nous suivons Tinyllama et Regmix pour préparer les environnements:
Nous nous attendons à ce que CUDA 11.8 soit installé.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' Remarque: à partir de 2023/09/02, XFORMERS ne fournit pas de binaires pré-construits pour la torche 2.1. Vous devez le construire à partir de la source.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
pour installer d'autres dépendances. Il peut prendre> = 5 minutes pour construire des xformateurs / l'attention flash. Ne vous inquiétez pas si le processus stagnant apparemment ou si le terminal imprime de nombreux avertissements.
Avant d'entraîner le modèle, vous devez prétraiter les données. Nous fournissons le script facile à utiliser pour le prétraitement des données. Vous pouvez utiliser la commande suivante pour prétraiter les données:
cd preprocess
bash run_preprocess.sh Par défaut, vous téléchargerez d'abord l' regmix-data-sample à partir du HuggingFace, puis pré-trons-t-il les données. Les données JSONL seront enregistrées dans le répertoire preprocess/sail/regmix-data-sample , et les données prétraitées seront enregistrées dans le répertoire datasets/lit_dataset_regmix . Cela comprend environ 5 milliards de jetons et prend environ 20 Go d'espace disque.
Par défaut, nous utilisons le WANDB pour collecter les données afin d'éviter d'enregistrer des petits modèles et des journaux massifs sur la machine locale. Si vous souhaitez utiliser le WANDB, vous devez créer un compte sur le WANDB et obtenir la clé API. Ensuite, vous devez définir la variable d'environnement suivante dans scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY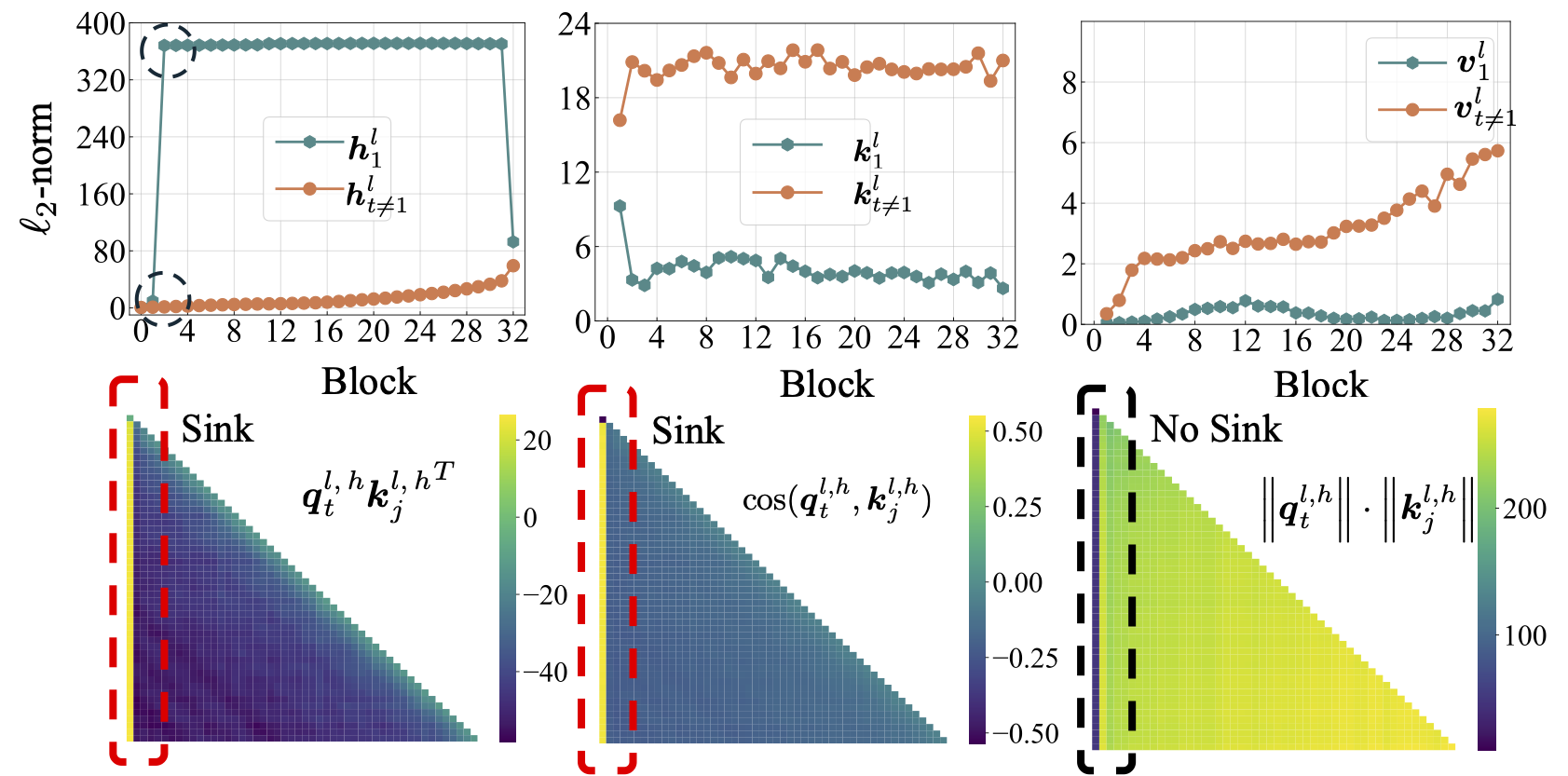
Nous mettons d'abord une étude complète sur les LMS open source, notamment LLAMA2, LLAMA3, Mistral, GPT2, Pythie et Opt. Nous fournissons le script pour calculer la métrique du puits d'attention pour le LMS ci-dessus:
python eval_sink_open_source.pyNous fournissons également le script pour calculer la norme L2 des états, des clés et des valeurs cachés:
python eval_activations_open_source.py Nous notons que nous incluons les évaluations des 30 LMS open source dans un seul script, qui peut prendre beaucoup de temps pour télécharger des modèles. Veuillez modifier la ligne 57-63 dans eval_sink_open_source.py ou la ligne 104-110 dans eval_activations_open_source.py pour évaluer des LM spécifiques.
Nous pré-entraînons une série de modèles LLAMA sur des données de jetons 5B pour étudier comment l'optimisation, les données, la fonction de perte et l'achitecture du modèle dans la pré-formation LM affectent l'évier d'attention.
Différentes configurations peuvent entraîner une utilisation différente de la mémoire et les configurations de la Service ne sont pas bien compatibles avec l'attention du flash. Nous pouvons avoir différentes bases de code pour la pré-formation et l'inférence du modèle dans le dossier lit_gpt . Nous accueillons les contributions de la communauté pour rendre le code plus concis et efficace.
À moins d'instructions supplémentaires, les expériences suivies ont besoin de 4 GPU avec au moins 40 Go de mémoire. Veuillez modifier la taille du micro-lot dans configs/*.yaml .
Exécutez la configuration par défaut:
bash scripts/run_defaults_60m.sh Le point de contrôle final est enregistré aux checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
Nous fournissons tous les scripts pour reproduire nos résultats expérimentaux dans le document principal.
Optimisation: reportez-vous aux scripts/optimization.md . À emporter: 1. Le puits d'attention émerge après la formation efficace du LMS. 2. L'évier d'attention semble moins évident en LMS formé avec de petits taux d'apprentissage.
Distribution des données: reportez-vous à scripts/data_distribution.md . À emporter: 1. Le puits d'attention émerge après que les LM sont formées sur des données de formation suffisantes. 2. Évier d'attention pourrait être déplacé vers d'autres positions plutôt que le premier jeton si modifier la distribution des données.
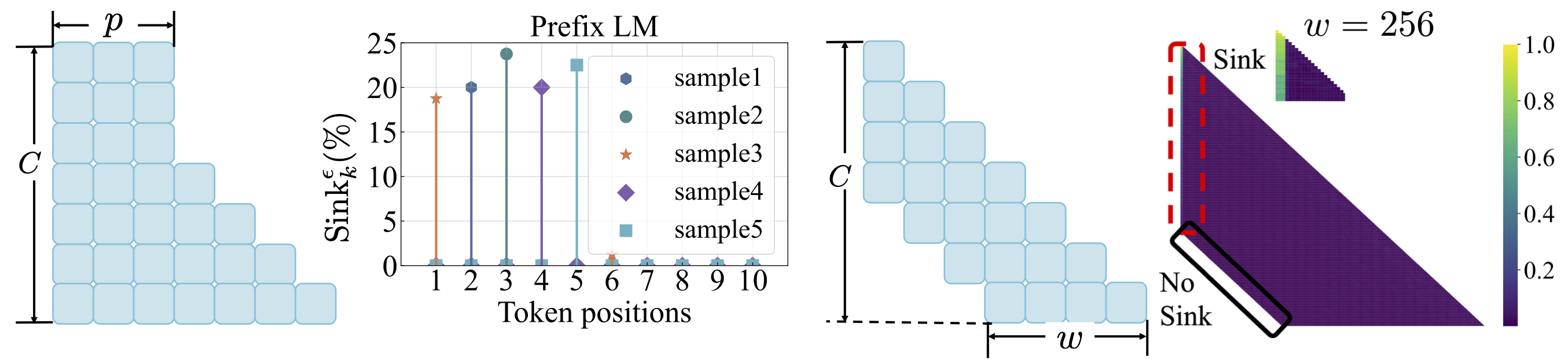
Fonction de perte: reportez-vous à scripts/loss_function.md . Les plats à emporter: 1. La décroissance du poids encourage l'émergence de l'évier d'attention. 2. Avec la modélisation du langage préfixe, l'évier d'attention apparaît parmi les jetons de préfixe plutôt que le premier jeton uniquement. 3. Avec l'attention des fenêtres décalée, l'évier d'attention apparaît sur l'absolu, pas le premier jeton relatif. La taille des fenêtres plus petite empêche l'émergence de l'évier d'attention.
scripts/model_architecture.md . À emporter: 1. L'intégration de position, la conception FFN, l'emplacement du LN et la conception multi-têtes n'affectent pas l'émergence de l'évier d'attention. 2. L'évier d'attention agit davantage comme des biais clés, stockant une attention supplémentaire et ne contribuant pas au calcul de la valeur. 3. Lorsque la dépendance intérieure des jetons relaxants à l'égard des scores d'attention, l'évier d'attention n'émerge pas en LMS. 

Enfin, nous augmentons la taille du modèle aux paramètres 1B et trouvons toujours aucun puits d'attention et des activations massives. Par défaut, nous utilisons 8 GPU pour exécuter les scripts suivants
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shSi vous trouvez ce projet utile dans vos recherches, veuillez envisager de citer notre article:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Nos codes sont développés sur la base de Tinyllama et Regmix.


