Attention Sink
1.0.0
[arxiv]
ในงานนี้เราตรวจสอบว่าการเพิ่มประสิทธิภาพการกระจายข้อมูลฟังก์ชั่นการสูญเสียและสถาปัตยกรรมแบบจำลองในการฝึกอบรมก่อนการฝึกอบรม LM มีผลต่อการเกิดขึ้นของความสนใจ
เราเรียกใช้การทดลองทั้งหมดของเราใน A100 GPU ด้วยหน่วยความจำ 40GB เราติดตาม Tinyllama และ Regmix เพื่อเตรียมสภาพแวดล้อม:
เราคาดหวังว่าคุณจะติดตั้ง Cuda 11.8 แล้ว
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' หมายเหตุ: ณ ปี 2023/09/02, Xformers ไม่ได้ให้ไบนารีที่สร้างไว้ล่วงหน้าสำหรับ Torch 2.1 คุณต้องสร้างจากแหล่งที่มา
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
เพื่อติดตั้งการพึ่งพาอื่น ๆ อาจใช้เวลา> = 5 นาทีในการสร้าง Xformers/Flash-Attention ไม่ต้องกังวลหากกระบวนการดูเหมือนจะนิ่งหรือเทอร์มินัลพิมพ์คำเตือนมากมาย
ก่อนที่จะฝึกอบรมแบบจำลองคุณต้องประมวลผลข้อมูลล่วงหน้า เราให้บริการสคริปต์ที่ใช้งานง่ายสำหรับการประมวลผลข้อมูลล่วงหน้า คุณสามารถใช้คำสั่งต่อไปนี้เพื่อประมวลผลข้อมูลล่วงหน้า:
cd preprocess
bash run_preprocess.sh โดยค่าเริ่มต้นคุณจะดาวน์โหลด regmix-data-sample ก่อนจาก HuggingFace จากนั้นประมวลผลข้อมูลล่วงหน้า ข้อมูล JSONL จะถูกบันทึกไว้ในไดเรกทอรี preprocess/sail/regmix-data-sample และข้อมูลที่ประมวลผลล่วงหน้าจะถูกบันทึกไว้ในไดเร็กทอรี datasets/lit_dataset_regmix ซึ่งรวมถึงโทเค็นประมาณ 5B และใช้พื้นที่ดิสก์ประมาณ 20GB
โดยค่าเริ่มต้นเราใช้ WANDB สำหรับการรวบรวมข้อมูลเพื่อหลีกเลี่ยงการบันทึกรุ่นขนาดเล็กขนาดใหญ่และบันทึกบนเครื่องท้องถิ่น หากคุณต้องการใช้ Wandb คุณต้องสร้างบัญชีบน Wandb และรับคีย์ API จากนั้นคุณควรตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้ใน scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY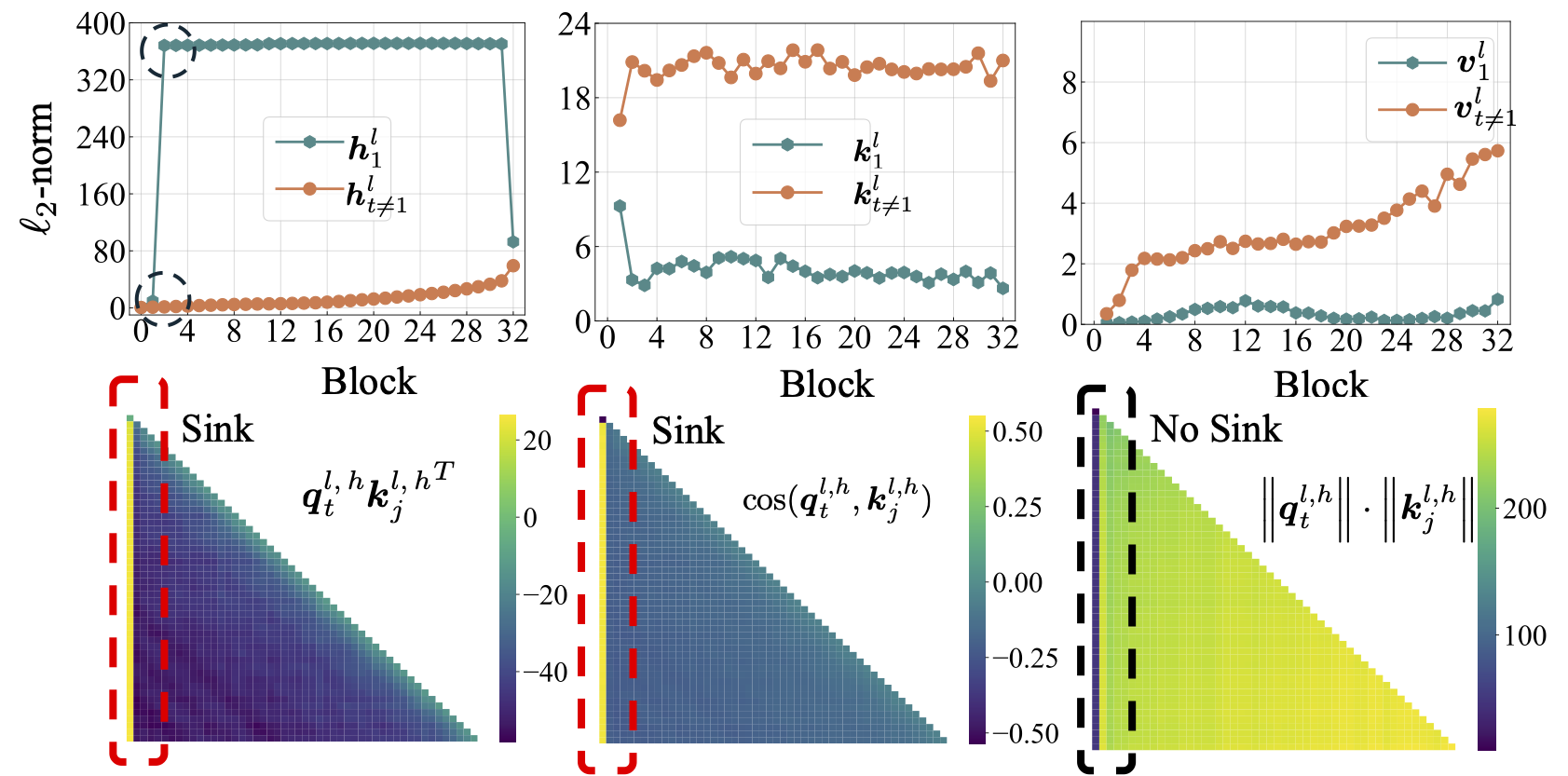
ก่อนอื่นเราจะทำการศึกษาที่ครอบคลุมเกี่ยวกับ LMS แบบเปิดโล่งรวมถึง LLAMA2, LLAMA3, Mistral, GPT2, Pythia และ Opt เราให้สคริปต์เพื่อคำนวณตัวชี้วัด Sink Sink สำหรับ LMS ด้านบน:
python eval_sink_open_source.pyนอกจากนี้เรายังให้สคริปต์เพื่อคำนวณ L2-norm ของสถานะซ่อนคีย์และค่า:
python eval_activations_open_source.py เราทราบว่าเรารวมการประเมิน LMS ที่เปิดทั้งหมด 30 รายการในสคริปต์เดียวซึ่งอาจใช้เวลานานในการดาวน์โหลดรุ่น โปรดแก้ไขบรรทัด 57-63 ใน eval_sink_open_source.py หรือบรรทัด 104-110 ใน eval_activations_open_source.py เพื่อประเมิน LMS เฉพาะ
เราฝึกอบรมชุดของแบบจำลอง LLAMA บนข้อมูลโทเค็น 5B เพื่อตรวจสอบว่าการเพิ่มประสิทธิภาพข้อมูลฟังก์ชั่นการสูญเสียและการสร้างแบบจำลองในการฝึกอบรมล่วงหน้า LM ส่งผลกระทบต่อความสนใจ
การตั้งค่าที่แตกต่างกันอาจส่งผลให้เกิดการใช้หน่วยความจำที่แตกต่างกันและการตั้งค่า sereal นั้นไม่เข้ากันได้ดีกับความสนใจของแฟลช เราอาจมีรหัสฐานที่แตกต่างกันสำหรับรุ่นก่อนการฝึกอบรมและการอนุมานในโฟลเดอร์ lit_gpt เรายินดีต้อนรับการมีส่วนร่วมจากชุมชนเพื่อให้รหัสกระชับและมีประสิทธิภาพมากขึ้น
การทดลองที่ตามมาจะต้องมี 4 GPUs 4 GPU ที่มีหน่วยความจำอย่างน้อย 40 GB โปรดปรับเปลี่ยนขนาดแบทช์ขนาดเล็กใน configs/*.yaml
รันการตั้งค่าเริ่มต้น:
bash scripts/run_defaults_60m.sh จุดตรวจสอบสุดท้ายจะถูกบันทึกที่ checkpoints/tinyllama_60M/iter-020000-ckpt.pth
เราให้สคริปต์ทั้งหมดเพื่อทำซ้ำผลการทดลองของเราในบทความหลัก
การเพิ่มประสิทธิภาพ: ดู scripts/optimization.md Takeaways: 1. Sink Attention เกิดขึ้นหลังจาก LMS ได้รับการฝึกฝนอย่างมีประสิทธิภาพ 2. อ่างล้างจานความสนใจปรากฏชัดเจนน้อยลงใน LMS ที่ได้รับการฝึกฝนด้วยอัตราการเรียนรู้ขนาดเล็ก
การกระจายข้อมูล: ดู scripts/data_distribution.md Takeaways: 1. ความสนใจอ่างล้างจานเกิดขึ้นหลังจาก LMS ได้รับการฝึกฝนเกี่ยวกับข้อมูลการฝึกอบรมที่เพียงพอ 2. Sink Attention สามารถเปลี่ยนไปยังตำแหน่งอื่นได้มากกว่าโทเค็นแรกหากแก้ไขการกระจายข้อมูล
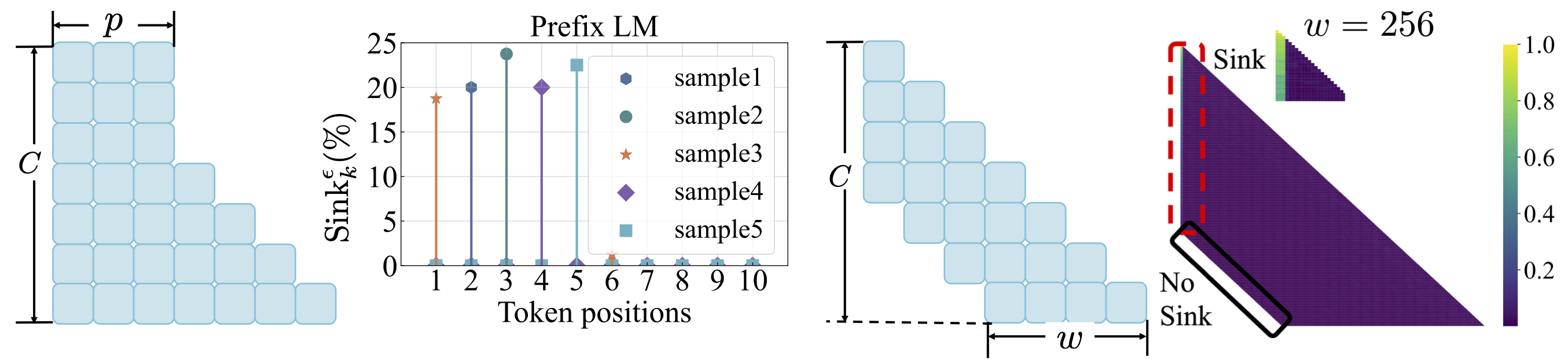
ฟังก์ชั่นการสูญเสีย: ดู scripts/loss_function.md ประเด็น: 1. การสลายตัวของน้ำหนักส่งเสริมการเกิดขึ้นของความสนใจ 2. ด้วยการสร้างแบบจำลองภาษาคำนำหน้าอ่างล้างจานจะปรากฏขึ้นในโทเค็นคำนำหน้ามากกว่าโทเค็นแรกเท่านั้น 3. ด้วยความสนใจของหน้าต่างที่เปลี่ยนไปอ่างความสนใจจะปรากฏขึ้นบนสัมบูรณ์ไม่ใช่โทเค็นญาติคนแรก ขนาดหน้าต่างที่เล็กกว่าช่วยป้องกันการเกิดขึ้นของอ่างล้างจาน
scripts/model_architecture.md Takeaways: 1. การฝังตำแหน่งการออกแบบ FFN ตำแหน่ง LN และการออกแบบหลายหัวไม่ส่งผลกระทบต่อการเกิดขึ้นของความสนใจ 2. Sink Attention ทำหน้าที่เหมือนอคติที่สำคัญจัดเก็บความสนใจเป็นพิเศษและในขณะเดียวกันก็ไม่ได้มีส่วนร่วมในการคำนวณมูลค่า 3. เมื่อผ่อนคลายภายในของโทเค็นการพึ่งพาคะแนนความสนใจอ่างล้างจานความสนใจจะไม่เกิดขึ้นใน LMS 

ในที่สุดเราขยายขนาดของโมเดลเป็นพารามิเตอร์ 1B และค้นหาว่ายังไม่มีการอ่างล้างจานและการเปิดใช้งานขนาดใหญ่ โดยค่าเริ่มต้นเราใช้ 8 GPU เพื่อเรียกใช้สคริปต์ต่อไปนี้
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shหากคุณพบว่าโครงการนี้มีประโยชน์ในการวิจัยของคุณโปรดพิจารณาอ้างถึงบทความของเรา:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
รหัสของเราได้รับการพัฒนาขึ้นอยู่กับ Tinyllama และ Regmix


