Attention Sink
1.0.0
[arxiv]
En este trabajo, investigamos cómo la optimización, la distribución de datos, la función de pérdida y la arquitectura del modelo en la pre-entrenamiento de LM influyen en la aparición del sumidero de atención.
Ejecutamos todos nuestros experimentos en GPU A100 con memoria de 40 GB. Seguimos a Tinyllama y RegMix para preparar los entornos:
Esperamos que haya instalado CUDA 11.8.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' Nota: A partir de 2023/09/02, Xformers no proporciona binarios preconstruidos para la antorcha 2.1. Tienes que construirlo desde la fuente.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
para instalar otras dependencias. Puede tomar> = 5 minutos construir Xformers/Flash-Atention. No se preocupe si el proceso aparentemente está estancado o la terminal imprime muchas advertencias.
Antes de entrenar el modelo, debe preprocesar los datos. Proporcionamos el script fácil de usar para preprocesar los datos. Puede usar el siguiente comando para preprocesar los datos:
cd preprocess
bash run_preprocess.sh De forma predeterminada, primero descargará la regmix-data-sample desde Huggingface y luego preprocesará los datos. Los datos JSONL se guardarán en el directorio preprocess/sail/regmix-data-sample , y los datos preprocesados se guardarán en el directorio datasets/lit_dataset_regmix . Esto incluye aproximadamente 5B de tokens y ocupa aproximadamente 20 GB de espacio en disco.
Por defecto, usamos el WandB para recopilar los datos para evitar guardar modelos y registros pequeños masivos en la máquina local. Si desea usar el WandB, debe crear una cuenta en el WandB y obtener la clave API. Luego debe establecer la siguiente variable de entorno en scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY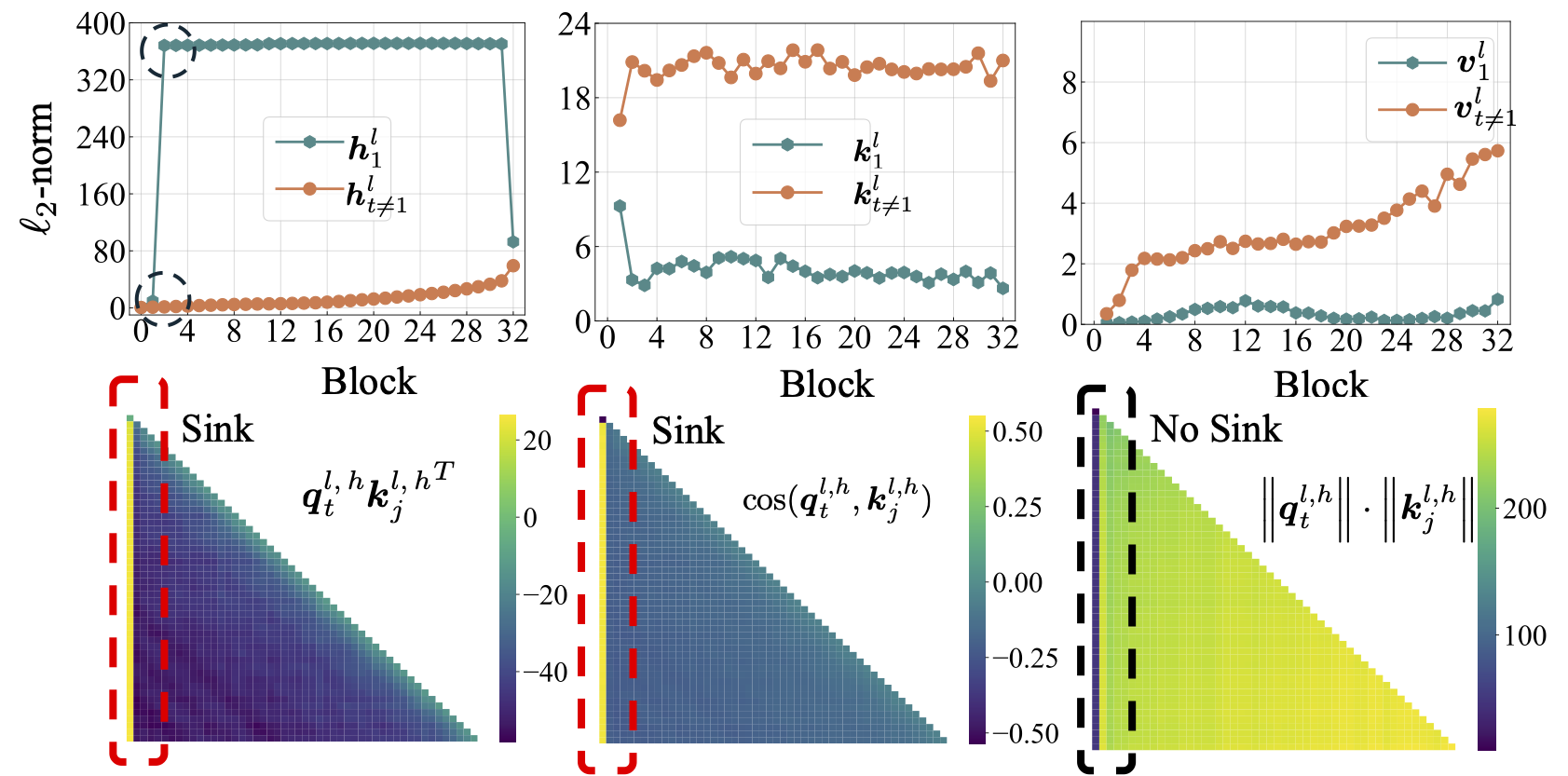
Primero realizamos un estudio exhaustivo sobre LMS de código abierto, incluidos LLAMA2, LLAMA3, Mistral, GPT2, Pythia y Opt. Proporcionamos el script para calcular la métrica del sumidero de atención para el LMS anterior:
python eval_sink_open_source.pyTambién proporcionamos el script para calcular la norma L2 de los estados ocultos, claves y valores:
python eval_activations_open_source.py Observamos que incluimos las evaluaciones de los 30 LM de código abierto en un solo script, que puede llevar mucho tiempo descargar modelos. Modifique la línea 57-63 en eval_sink_open_source.py o la línea 104-110 en eval_activations_open_source.py para evaluar LMS específicos.
Pre-entrenamos una serie de modelos de LLAMA en datos de token 5B para investigar cómo la optimización, los datos, la función de pérdida y la achitectura del modelo en la pretruación de LM afectan el sumidero de atención.
Las diferentes configuraciones pueden dar como resultado un uso de memoria diferente, y las configuraciones de serveal no son bien compatibles con la atención flash. Es posible que tengamos diferentes bases de código para la capacitación e inferencia del modelo en la carpeta lit_gpt . Agradecemos las contribuciones de la comunidad para que el código sea más conciso y eficiente.
A menos que las instrucciones adicionales, los experimentos seguidos necesitan 4 GPU con al menos 40 GB de memoria. Modifique el tamaño de micro por lotes en configs/*.yaml .
Ejecute la configuración predeterminada:
bash scripts/run_defaults_60m.sh El punto de control final se guarda en checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
Proporcionamos todos los guiones para reproducir nuestros resultados experimentales en el documento principal.
Optimización: consulte scripts/optimization.md . Takeaways: 1. El fregadero de atención surge después de que los LM se entrenan de manera efectiva. 2. El fregadero de atención parece menos obvio en LMS entrenados con pequeñas tarifas de aprendizaje.
Distribución de datos: consulte scripts/data_distribution.md . Takeaways: 1. El fregadero de atención surge después de que los LMS se entrenan en datos de entrenamiento suficientes. 2. El sumidero de atención podría cambiarse a otras posiciones en lugar del primer token si modifica la distribución de datos.
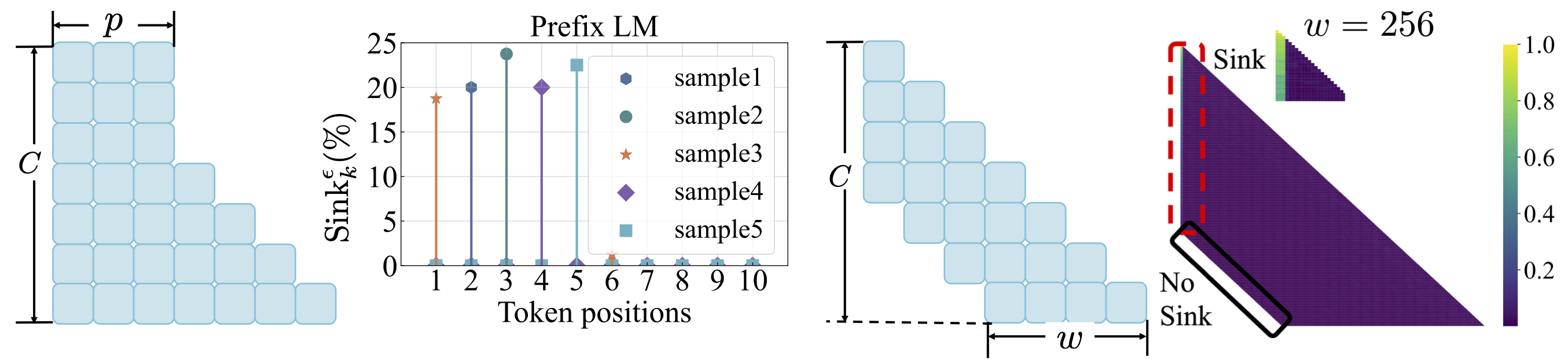
Función de pérdida: consulte scripts/loss_function.md . Takeaways: 1. La descomposición de peso fomenta la aparición del sumidero de atención. 2. Con el modelado de lenguaje de prefijo, la atención aparece entre los tokens de prefijo en lugar del primer token solamente. 3. Con la atención de la ventana desplazada, la atención aparece en el absoluto, no en el primer token relativo. El tamaño de la ventana más pequeño evita la aparición del sumidero de atención.
scripts/model_architecture.md . Takeaways: 1. Incrustación de posición, diseño de FFN, ubicación LN y diseño de múltiples cabezas no afectan la aparición del sumidero de atención. 2. La atención se actúa más como sesgos clave, almacenando atención adicional y, mientras tanto, no contribuye al cálculo del valor. 3. Al relajar la dependencia interna de los tokens de los puntajes de atención, la atención no emerge en LMS. 

Finalmente, ampliamos el tamaño del modelo a parámetros 1b y todavía no encontramos fregadero de atención y activaciones masivas. Por defecto, usamos 8 GPU para ejecutar los siguientes scripts
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shSi encuentra útil este proyecto en su investigación, considere citar nuestro documento:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Nuestros códigos se desarrollan en base a Tinyllama y RegMix.


