Attention Sink
1.0.0
[Arxiv]
Dalam karya ini, kami menyelidiki bagaimana optimasi, distribusi data, fungsi kerugian, dan arsitektur model dalam pra-pelatihan LM mempengaruhi munculnya wastafel perhatian.
Kami menjalankan semua percobaan kami pada A100 GPU dengan memori 40GB. Kami mengikuti Tinyllama dan Regmix untuk mempersiapkan lingkungan:
Kami berharap Anda telah menginstal CUDA 11.8.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' CATATAN: Pada 2023/09/02, Xformers tidak menyediakan binari pra-dibangun untuk Torch 2.1. Anda harus membangunnya dari sumber.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
untuk menginstal dependensi lainnya. Mungkin butuh> = 5 menit untuk membangun xformers/flash-flash. Jangan khawatir jika prosesnya tampaknya stagnan atau terminal mencetak banyak peringatan.
Sebelum melatih model, Anda perlu melakukan preprocess data. Kami menyediakan skrip yang mudah digunakan untuk preprocessing data. Anda dapat menggunakan perintah berikut untuk preprocess data:
cd preprocess
bash run_preprocess.sh Secara default, Anda akan mengunduh regmix-data-sample dari permukaan pelukan dan kemudian melakukan preprocess data. Data JSONL akan disimpan di direktori preprocess/sail/regmix-data-sample , dan data preproses akan disimpan dalam datasets/lit_dataset_regmix direktori. Ini termasuk sekitar 5b token dan membutuhkan sekitar 20GB disk ruang.
Secara default kami menggunakan wandb untuk mengumpulkan data untuk menghindari menghemat model dan log kecil pada mesin lokal. Jika Anda ingin menggunakan wandb, Anda perlu membuat akun di wandb dan mendapatkan kunci API. Maka Anda harus mengatur variabel lingkungan berikut dalam scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY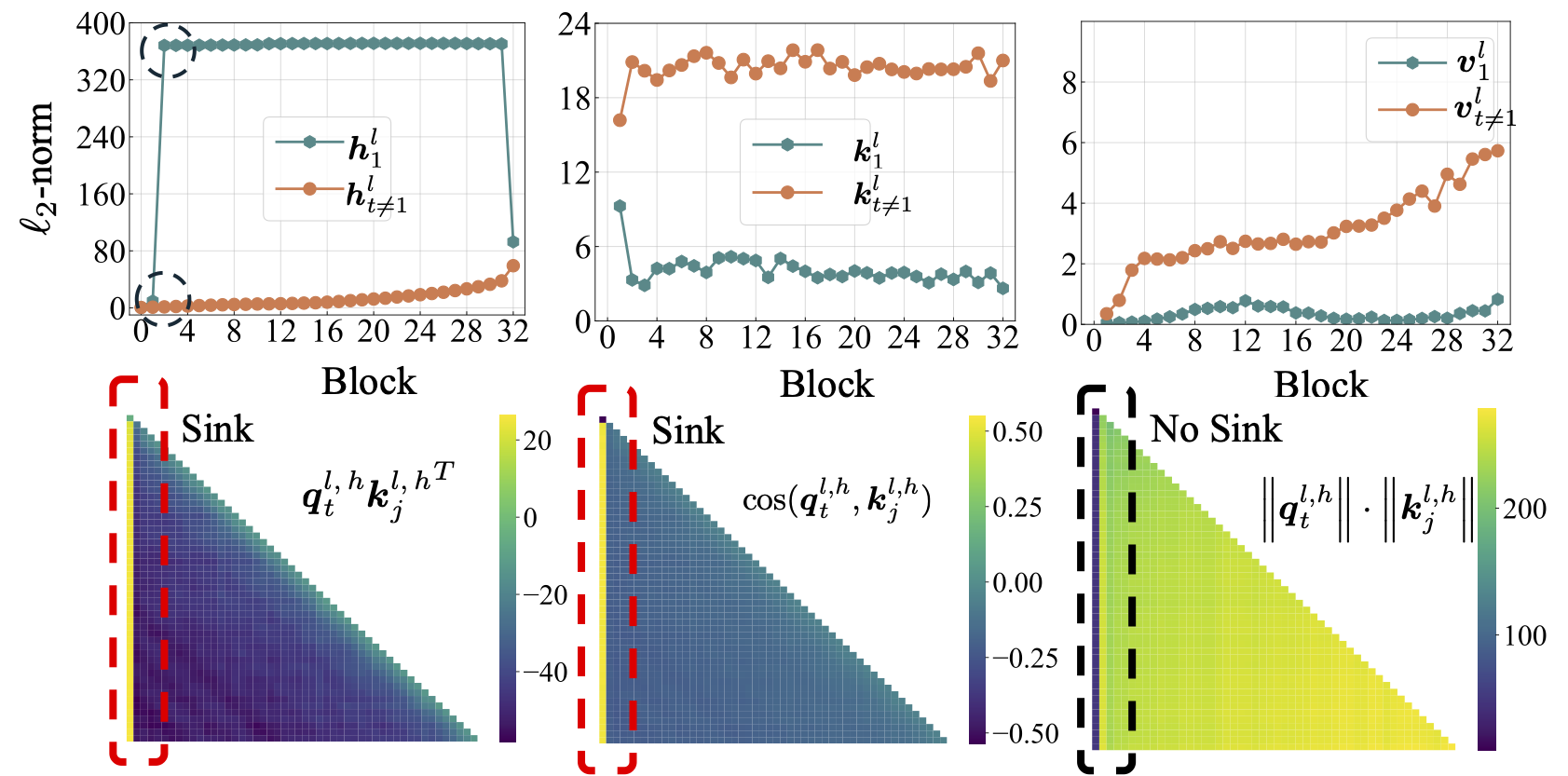
Kami pertama-tama melakukan studi komprehensif tentang LMS sumber terbuka, termasuk LLAMA2, LLAMA3, MISTRAL, GPT2, Pythia, dan Opt. Kami menyediakan skrip untuk menghitung metrik wastafel perhatian untuk LMS di atas:
python eval_sink_open_source.pyKami juga menyediakan skrip untuk menghitung norma L2 dari status tersembunyi, kunci dan nilai:
python eval_activations_open_source.py Kami mencatat bahwa kami menyertakan evaluasi semua 30 LMS open-source dalam satu skrip, yang mungkin membutuhkan waktu lama untuk mengunduh model. Harap ubah baris 57-63 di eval_sink_open_source.py atau baris 104-110 di eval_activations_open_source.py untuk mengevaluasi LMS tertentu.
Kami melakukan pra-pelatihan serangkaian model LLAMA pada data token 5B untuk menyelidiki bagaimana optimasi, data, fungsi kehilangan, dan model achitecture dalam pra-pelatihan LM mempengaruhi wastafel perhatian.
Pengaturan yang berbeda dapat menghasilkan penggunaan memori yang berbeda, dan pengaturan serveal tidak kompatibel dengan perhatian flash. Kami mungkin memiliki basis kode yang berbeda untuk model pra-pelatihan dan inferensi di folder lit_gpt . Kami menyambut kontribusi dari masyarakat untuk membuat kode lebih ringkas dan efisien.
Kecuali instruksi tambahan, percobaan yang diikuti membutuhkan 4 GPU dengan setidaknya 40 GB memori. Harap ubah ukuran batch mikro di configs/*.yaml .
Jalankan pengaturan default:
bash scripts/run_defaults_60m.sh Pos pemeriksaan akhir disimpan di checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
Kami menyediakan semua skrip untuk mereproduksi hasil eksperimen kami di makalah utama.
Optimalisasi: Lihat scripts/optimization.md . Takeaways: 1. Perhatian wastafel muncul setelah LMS dilatih secara efektif. 2. Perhatian wastafel tampak kurang jelas pada LMS yang dilatih dengan tingkat pembelajaran yang kecil.
Distribusi Data: Lihat scripts/data_distribution.md . Takeaways: 1. Perhatian wastafel muncul setelah LMS dilatih pada data pelatihan yang cukup. 2. Perhatian wastafel dapat dialihkan ke posisi lain daripada token pertama jika memodifikasi distribusi data.
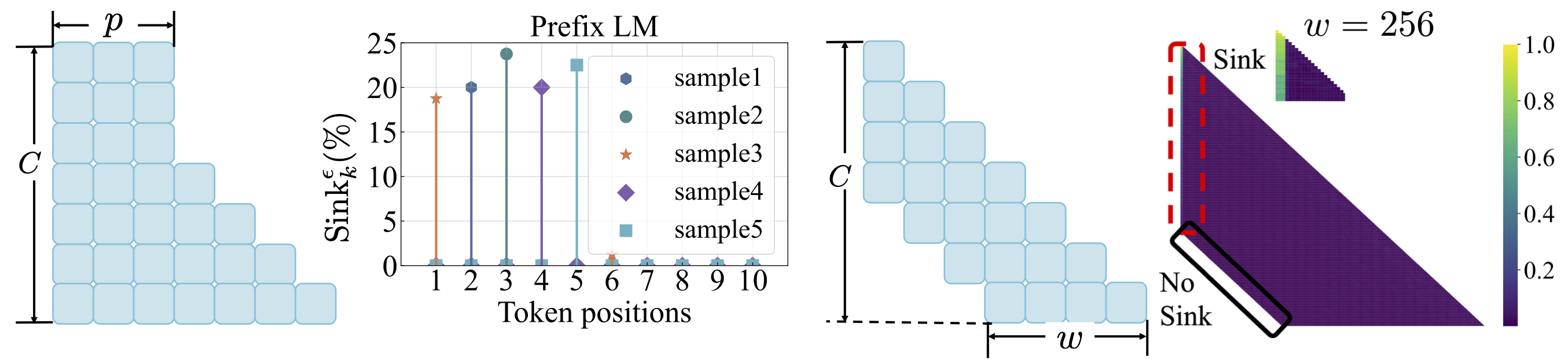
Fungsi Kehilangan: Lihat scripts/loss_function.md . Takeaways: 1. Weight Decay mendorong munculnya perhatian. 2. Dengan pemodelan bahasa awalan, wastafel perhatian muncul di antara token awalan daripada token pertama saja. 3. Dengan perhatian jendela yang digeser, wastafel perhatian muncul di absolut, bukan token pertama yang relatif. Ukuran jendela yang lebih kecil mencegah kemunculan wastafel perhatian.
scripts/model_architecture.md . Takeaways: 1. Embedding posisi, desain FFN, lokasi LN, dan desain multi-head tidak mempengaruhi munculnya wastafel perhatian. 2. Perhatian wastafel bertindak lebih seperti bias utama, menyimpan perhatian ekstra dan sementara itu tidak berkontribusi pada perhitungan nilai. 3. Saat menenangkan ketergantungan batin token pada skor perhatian, wastafel perhatian tidak muncul di LMS. 

Akhirnya, kami meningkatkan ukuran model ke parameter 1B dan menemukan masih belum ada perhatian dan aktivasi besar -besaran. Secara default, kami menggunakan 8 GPU untuk menjalankan skrip berikut
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shJika Anda menemukan proyek ini berguna dalam penelitian Anda, silakan pertimbangkan mengutip makalah kami:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Kode kami dikembangkan berdasarkan Tinyllama dan Regmix.


