Attention Sink
1.0.0
[Arxiv]
Neste trabalho, investigamos como a otimização, distribuição de dados, função de perda e arquitetura de modelos no pré-treinamento de LM influencia o surgimento de afundamento de atenção.
Executamos todos os nossos experimentos em GPUs A100 com memória de 40 GB. Seguimos Tinyllama e Regmix para preparar os ambientes:
Esperamos que você tenha CUDA 11.8 instalado.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' Nota: Em 2023/09/02, o Xformers não fornece binários pré-construídos para a tocha 2.1. Você tem que construí -lo a partir da fonte.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
para instalar outras dependências. Pode levar> = 5 minutos para construir o Xformers/Flash-Attention. Não se preocupe se o processo aparentemente estagnado ou o terminal imprimir muitos avisos.
Antes de treinar o modelo, você precisa pré -processar os dados. Fornecemos o script fácil de usar para pré-processamento dos dados. Você pode usar o seguinte comando para pré -processar os dados:
cd preprocess
bash run_preprocess.sh Por padrão, você primeiro baixará a regmix-data-sample do huggingface e depois pré-processará os dados. Os dados JSONL serão salvos no diretório preprocess/sail/regmix-data-sample , e os dados pré-processados serão salvos no diretório datasets/lit_dataset_regmix . Isso inclui aproximadamente 5b tokens e ocupa cerca de 20 GB de espaço em disco.
Por padrão, usamos o wandb para coletar os dados para evitar salvar pequenos modelos e logs enormes na máquina local. Se você deseja usar o wandb, precisa criar uma conta no wandb e obter a chave da API. Em seguida, você deve definir a seguinte variável de ambiente em scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY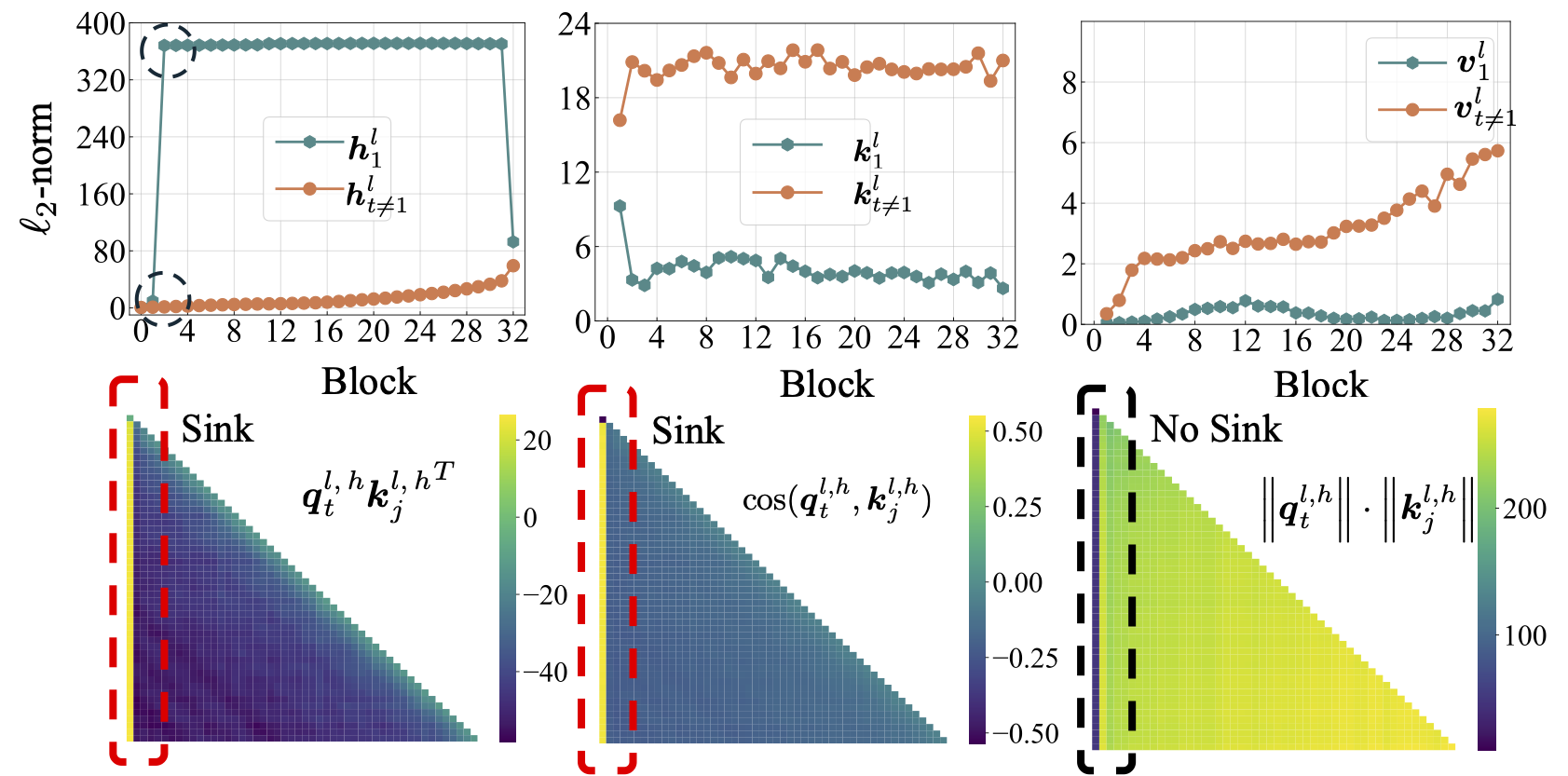
Primeiro, realizamos um estudo abrangente sobre LMS de código aberto, incluindo LLAMA2, LLAMA3, MISTRAL, GPT2, Pythia e Opt. Fornecemos o script para calcular a métrica de afundamento de atenção para o LMS acima:
python eval_sink_open_source.pyTambém fornecemos o script para calcular a norma L2 de estados, chaves e valores ocultos:
python eval_activations_open_source.py Observamos que incluímos as avaliações de todos os 30 LMs de código aberto em um único script, que podem levar muito tempo para baixar modelos. Modifique a linha 57-63 em eval_sink_open_source.py ou LINE 104-110 EM eval_activations_open_source.py para avaliar LMS específicos.
Pré-trep uma série de modelos de llama em dados de token 5B para investigar como otimização, dados, função de perda e acidentes de modelo no pré-treinamento de LM afetam o afastamento da atenção.
Diferentes configurações podem resultar em uso de memória diferente e as configurações do servEal não são bem compatíveis com a atenção do flash. Podemos ter bases de código diferentes para o pré-treinamento e inferência do modelo na pasta lit_gpt . Congratulamo -nos com as contribuições da comunidade para tornar o código mais conciso e eficiente.
A menos que instruções extras, os experimentos seguidos precisam de 4 GPUs com pelo menos 40 GB de memória. Modifique o tamanho do micro em lote nas configs/*.yaml .
Execute a configuração padrão:
bash scripts/run_defaults_60m.sh O ponto de verificação final é salvo nos checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
Fornecemos todos os scripts para reproduzir nossos resultados experimentais no artigo principal.
Otimização: consulte scripts/optimization.md . Takeaways: 1. A atenção em surge depois que os LMs são treinados de maneira eficaz. 2. A atenção do afundamento parece menos óbvia no LMS treinado com pequenas taxas de aprendizado.
Distribuição de dados: consulte scripts/data_distribution.md . Takeaways: 1. A atenção em surge depois que o LMS é treinado em dados de treinamento suficientes. 2. A atenção pode ser transferida para outras posições, em vez do primeiro token se modificar a distribuição de dados.
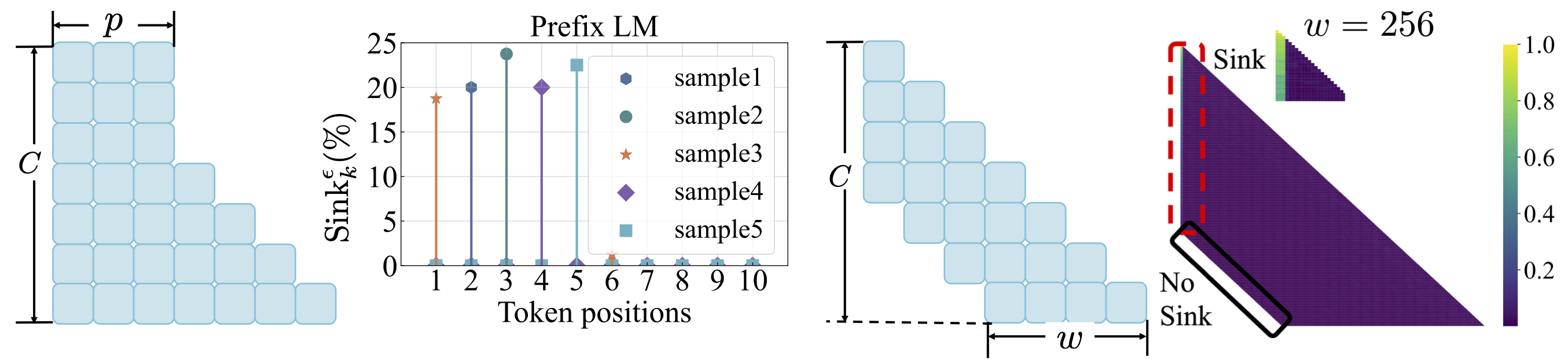
Função de perda: consulte scripts/loss_function.md . Takeaways: 1. O decaimento do peso incentiva o surgimento da atenção afundando. 2. Com modelagem de idiomas de prefixo, o coletor de atenção aparece entre os tokens de prefixo, em vez do primeiro token. 3. Com a atenção da janela deslocada, o afundamento da atenção aparece no absoluto, não no relato primeiro token. O tamanho menor da janela impede o surgimento de atenção afundar.
scripts/model_architecture.md . Takeaways: 1. A incorporação posicional, o design da FFN, a localização do LN e o design de várias cabeças não afetam o surgimento da atenção. 2. A atenção age mais como vieses -chave, armazenando atenção extra e, enquanto isso, não contribuindo para o cálculo do valor. 3. Ao relaxar a dependência interior dos tokens de pontuações de atenção, o afastamento da atenção não surge no LMS. 

Finalmente, ampliamos o tamanho do modelo para parâmetros 1B e ainda não encontramos atenção e ativações maciças. Por padrão, usamos 8 GPUs para executar os seguintes scripts
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shSe você achar este projeto útil em sua pesquisa, considere citar nosso artigo:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Nossos códigos são desenvolvidos com base em Tinyllama e Regmix.


