Attention Sink
1.0.0
[Arxiv]
في هذا العمل ، نتحقق من كيفية تأثير التحسين وتوزيع البيانات ووظيفة الخسارة والهندسة المعمارية النموذجية في تدريب LM قبل ظهور الانتباه.
نقوم بتشغيل جميع تجاربنا على وحدات معالجة الرسومات A100 مع ذاكرة 40 جيجابايت. نتبع Tinyllama و Regmix لإعداد البيئات:
نتوقع أن يكون لديك CUDA 11.8 مثبتة.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' ملاحظة: اعتبارًا من 2023/09/02 ، لا يوفر Xformers ثنائيات تم إنشاؤها مسبقًا لشلة Torch 2.1. عليك أن تبنيه من المصدر.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
لتثبيت تبعيات أخرى. قد يستغرق الأمر> = 5 دقائق لبناء Xformers/Flash-antention. لا تقلق إذا كانت العملية راكدة أو تُطبع المحطة العديد من التحذيرات.
قبل تدريب النموذج ، تحتاج إلى معالجة البيانات. نحن نقدم البرنامج النصي سهل الاستخدام للمعالجة المسبقة للبيانات. يمكنك استخدام الأمر التالي للمعالجة المسبقة للبيانات:
cd preprocess
bash run_preprocess.sh بشكل افتراضي ، ستقوم أولاً بتنزيل regmix-data-sample من Luggingface ثم معالجة البيانات. سيتم حفظ بيانات JSONL في دليل preprocess/sail/regmix-data-sample ، وسيتم حفظ البيانات المعالجة مسبقًا في دليل datasets/lit_dataset_regmix . ويشمل ذلك حوالي 5B الرموز المميزة ويستغرق حوالي 20 جيجابايت من القرص.
بشكل افتراضي ، نستخدم WANDB لجمع البيانات لتجنب حفظ النماذج الصغيرة الضخمة والسجلات على الجهاز المحلي. إذا كنت ترغب في استخدام WANDB ، فأنت بحاجة إلى إنشاء حساب على WANDB والحصول على مفتاح API. ثم يجب عليك تعيين متغير البيئة التالي في scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY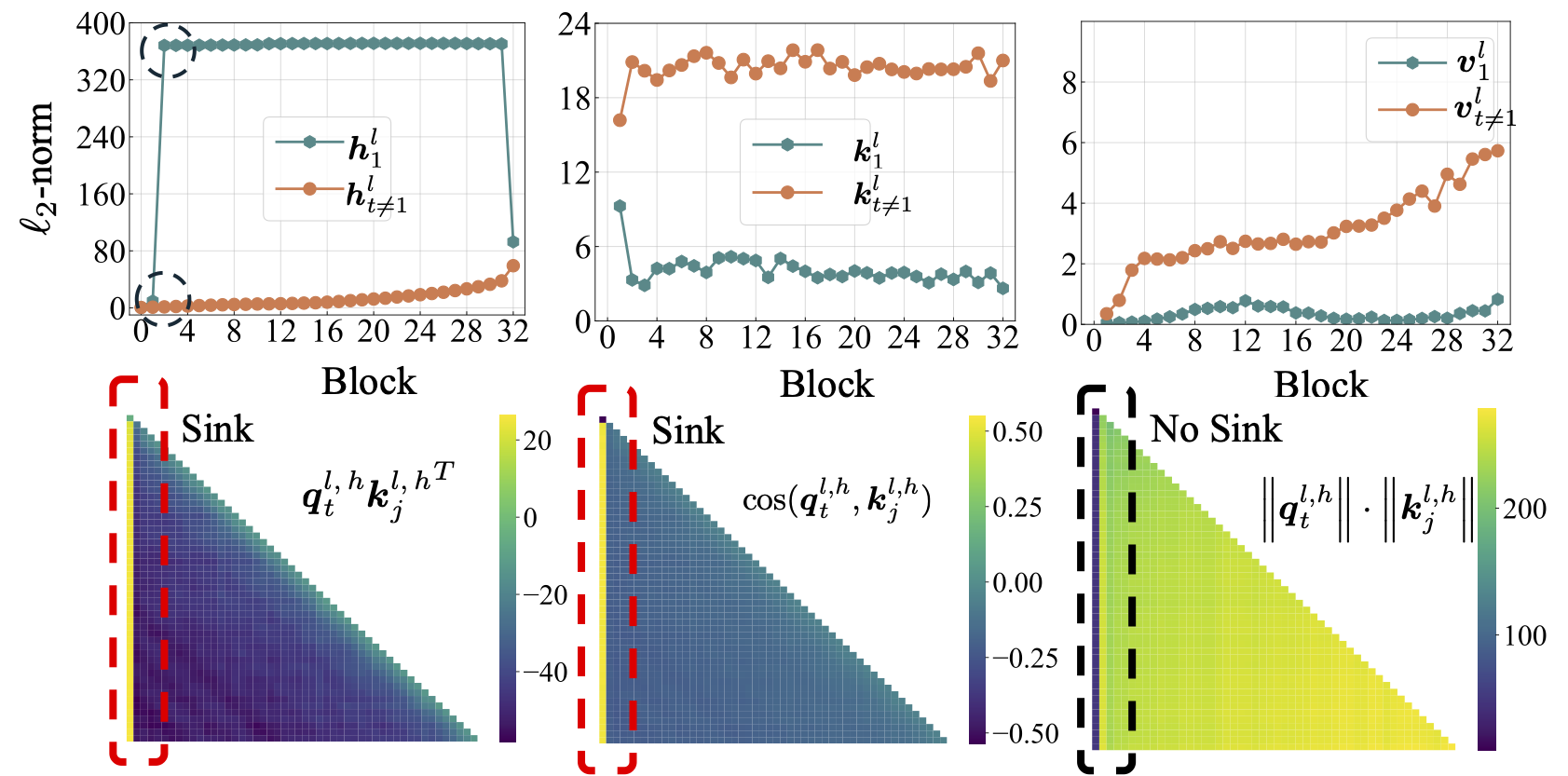
نقوم أولاً بإجراء دراسة شاملة حول LMS مفتوح المصدر ، بما في ذلك LLAMA2 و LLAMA3 و MISTRAL و GPT2 و PYTHIA و OPT. نحن نقدم البرنامج النصي لحساب مقياس حوض الانتباه لـ LMS أعلاه:
python eval_sink_open_source.pyنحن نقدم أيضًا البرنامج النصي لحساب L2-NORM للحالات المخفية والمفاتيح والقيم:
python eval_activations_open_source.py نلاحظ أننا ندرج تقييمات جميع LMS 30 مفتوحة المصدر في برنامج نصي واحد ، والذي قد يستغرق وقتًا طويلاً لتنزيل النماذج. يرجى تعديل السطر 57-63 في eval_sink_open_source.py أو السطر 104-110 في eval_activations_open_source.py لتقييم LMS محددة.
نقوم بتدريب سلسلة من نماذج LLAMA على بيانات الرمز المميز 5B للتحقيق في كيفية تأثير التحسين والبيانات ووظيفة الخسارة والمعمنة النموذجية في تدريب LM قبل الحوض.
قد تؤدي الإعدادات المختلفة إلى استخدام الذاكرة المختلفة ، كما أن الإعدادات المودعة ليست متوافقة مع اهتمام فلاش. قد يكون لدينا قواعد كود مختلفة للتدريب قبل التدريب والاستدلال في المجلد lit_gpt . نرحب بالمساهمات من المجتمع لجعل الكود أكثر إيجازًا وفعالية.
ما لم تكن الإرشادات الإضافية ، تحتاج التجارب المتبعة إلى 4 وحدات معالجة الرسومات مع ذاكرة لا تقل عن 40 جيجابايت. يرجى تعديل حجم الدفعة الصغيرة في configs/*.yaml .
قم بتشغيل الإعداد الافتراضي:
bash scripts/run_defaults_60m.sh يتم حفظ نقطة التفتيش النهائية عند checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
نحن نقدم جميع البرامج النصية لإعادة إنتاج نتائجنا التجريبية في الورقة الرئيسية.
التحسين: ارجع إلى scripts/optimization.md . الوجبات السريعة: 1. يظهر حوض الانتباه بعد تدريب LMS بشكل فعال. 2. يبدو أن بالوعة الانتباه أقل وضوحًا في LMS المدربة مع معدلات التعلم الصغيرة.
توزيع البيانات: راجع scripts/data_distribution.md . الوجبات السريعة: 1. يظهر حوض الانتباه بعد تدريب LMS على بيانات تدريب كافية. 2. يمكن تحويل مغسلة الانتباه إلى مواقف أخرى بدلاً من الرمز المميز الأول في حالة تعديل توزيع البيانات.
وظيفة الخسارة: راجع scripts/loss_function.md . الوجبات السريعة: 1. تسوس الوزن يشجع ظهور الانتباه. 2. مع نمذجة لغة البادئة ، يظهر حوض الانتباه بين الرموز المميزة بدلا من الرمز المميز الأول فقط. 3. مع انتباه النافذة المحولة ، يظهر حوض الانتباه على الرمز المطلق ، وليس المميز النسبي الأول. حجم النافذة الأصغر يمنع ظهور الانتباه بالوعة.
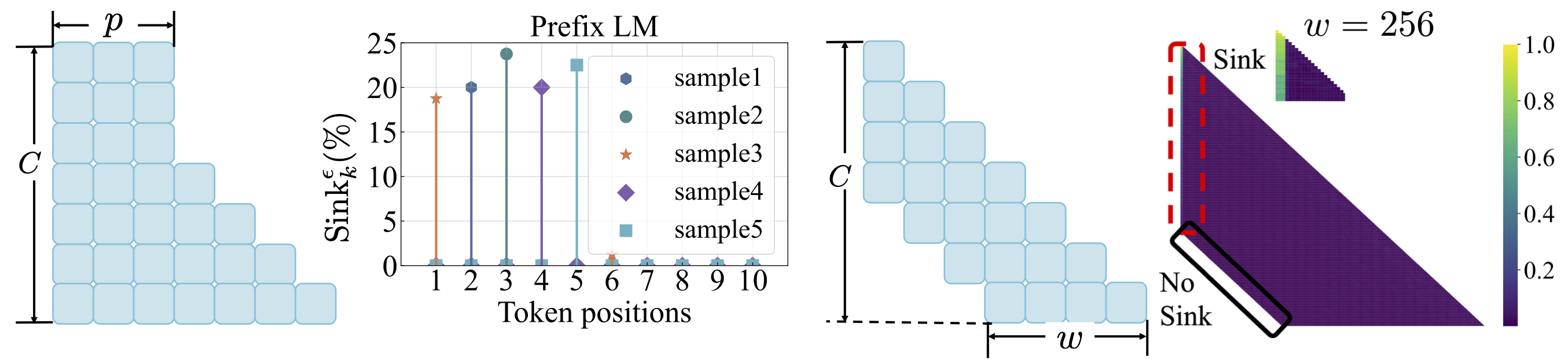
scripts/model_architecture.md . الوجبات السريعة: 1. التضمين الموضعي ، تصميم FFN ، موقع LN ، والتصميم متعدد الرأس لا يؤثر على ظهور بالوعة الانتباه. 2. يتصرف الانتباه بالتحيزات الرئيسية ، وتخزين اهتمام إضافي وفي الوقت نفسه لا يساهم في حساب القيمة. 3. عند استرخاء الاعتماد الداخلي على الرموز على درجات الانتباه ، لا يظهر حوض الانتباه في LMS. 

أخيرًا ، نقوم بزيادة حجم النموذج إلى معلمات 1B ونجد عدم الاهتمام بالوعة وتنشيطات ضخمة. بشكل افتراضي ، نستخدم 8 وحدات معالجة الرسومات لتشغيل النصوص التالية
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shإذا وجدت هذا المشروع مفيدًا في بحثك ، فيرجى التفكير في ذكر ورقتنا:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
تم تطوير رموزنا على أساس Tinyllama و Regmix.


