Attention Sink
1.0.0
[arxiv]
이 작업에서는 LM 사전 훈련의 최적화, 데이터 분포, 손실 기능 및 모델 아키텍처가주의 싱크의 출현에 어떤 영향을 미치는지 조사합니다.
40GB 메모리를 사용하여 모든 실험을 A100 GPU로 실행합니다. 우리는 Tinyllama와 Regmix를 따라 환경을 준비합니다.
우리는 당신이 Cuda 11.8을 설치했을 것으로 기대합니다.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' 참고 : 2023/09/02 현재 Xformers는 Torch 2.1에 사전 제작 된 이진을 제공하지 않습니다. 소스에서 빌드해야합니다.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
다른 종속성을 설치합니다. Xformers/Flash-intention을 구축하는 데> = 5 분이 걸릴 수 있습니다. 프로세스가 정체 된 것처럼 보이거나 터미널이 많은 경고를 인쇄하더라도 걱정하지 마십시오.
모델을 훈련하기 전에 데이터를 전처리해야합니다. 데이터 전처리를위한 사용하기 쉬운 스크립트를 제공합니다. 다음 명령을 사용하여 데이터를 전처리 할 수 있습니다.
cd preprocess
bash run_preprocess.sh 기본적으로 먼저 Huggingface에서 regmix-data-sample 다운로드 한 다음 데이터를 전제로 처리합니다. JSONL 데이터는 preprocess/sail/regmix-data-sample 디렉토리에 저장되며 전처리 데이터는 datasets/lit_dataset_regmix 디렉토리에 저장됩니다. 여기에는 약 5B 토큰이 포함되며 약 20GB 디스크 공간이 필요합니다.
기본적으로 우리는 대규모 소형 모델과 로컬 컴퓨터에 로그를 절약하지 않기 위해 데이터를 수집하기 위해 Wandb를 사용합니다. Wandb를 사용하려면 Wandb에 계정을 만들고 API 키를 가져와야합니다. 그런 다음 scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY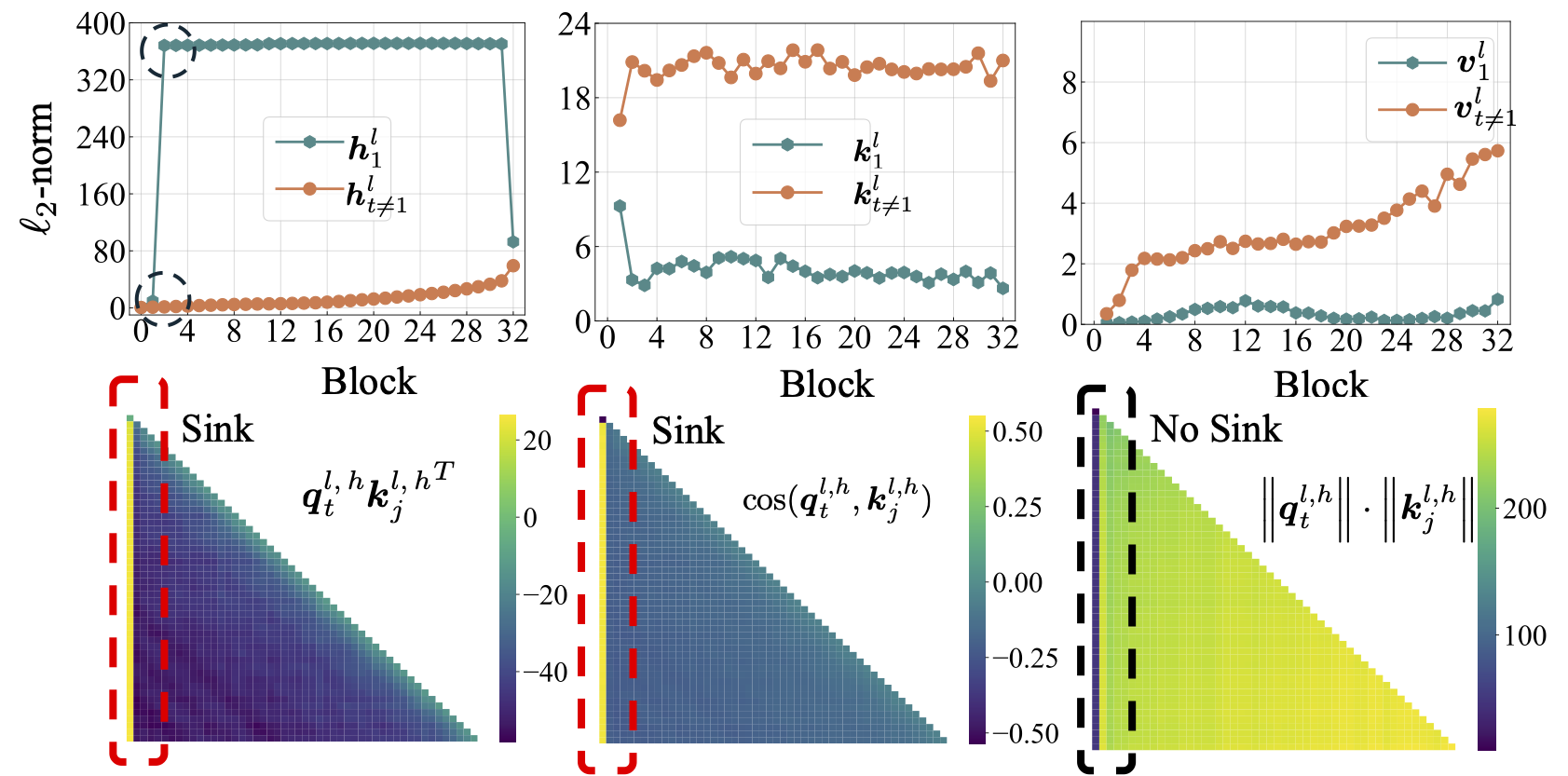
우리는 먼저 LLAMA2, LLAMA3, MISTRAL, GPT2, PYTHIA 및 OPT를 포함한 오픈 소스 LM에 대한 포괄적 인 연구를 수행합니다. 위의 LMS의주의 싱크대 메트릭을 계산하기 위해 스크립트를 제공합니다.
python eval_sink_open_source.py또한 숨겨진 상태, 열쇠 및 값의 L2-Norm을 계산하기위한 스크립트를 제공합니다.
python eval_activations_open_source.py 우리는 단일 스크립트에 30 개의 오픈 소싱 LMS의 평가를 포함시켜 모델을 다운로드하는 데 오랜 시간이 걸릴 수 있습니다. 특정 LMS eval_activations_open_source.py 평가하려면 eval_sink_open_source.py 또는 Line 104-110에서 57-63 행을 수정하십시오.
우리는 5B 토큰 데이터에 대한 일련의 LLAMA 모델을 사전 훈련시키기 위해 LM 사전 훈련의 최적화, 데이터, 손실 기능 및 모델 성취가주의 싱크에 미치는 영향을 조사합니다.
다른 설정은 다른 메모리 사용을 초래할 수 있으며, Serveal 설정은 플래시주의와 호환되지 않습니다. lit_gpt 폴더에서 모델 사전 훈련 및 추론에 대해 다른 코드베이스가있을 수 있습니다. 우리는 코드를보다 간결하고 효율적으로 만들기 위해 커뮤니티의 기여를 환영합니다.
추가 지침이 없으면 추적 실험은 40GB 이상의 메모리를 갖는 4 개의 GPU가 필요합니다. configs/*.yaml 에서 마이크로 배치 크기를 수정하십시오.
기본 설정 실행 :
bash scripts/run_defaults_60m.sh 최종 체크 포인트는 checkpoints/tinyllama_60M/iter-020000-ckpt.pth 로 저장됩니다.
우리는 메인 논문에서 실험 결과를 재현하기위한 모든 스크립트를 제공합니다.
최적화 : scripts/optimization.md 참조하십시오 .md. 테이크 아웃 : 1. LMS가 효과적으로 훈련 된 후주의 싱크가 나타납니다. 2. LMS에서는 작은 학습 속도로 훈련 된 LMS에서주의 싱크가 덜 명백해 보입니다.
데이터 배포 : scripts/data_distribution.md 를 참조하십시오. 테이크 아웃 : 1. LMS가 충분한 교육 데이터에 대해 교육을받은 후주의 싱크가 나타납니다. 2. 데이터 배포를 수정하는 경우 첫 번째 토큰이 아닌 다른 위치로주의 싱크를 이동할 수 있습니다.
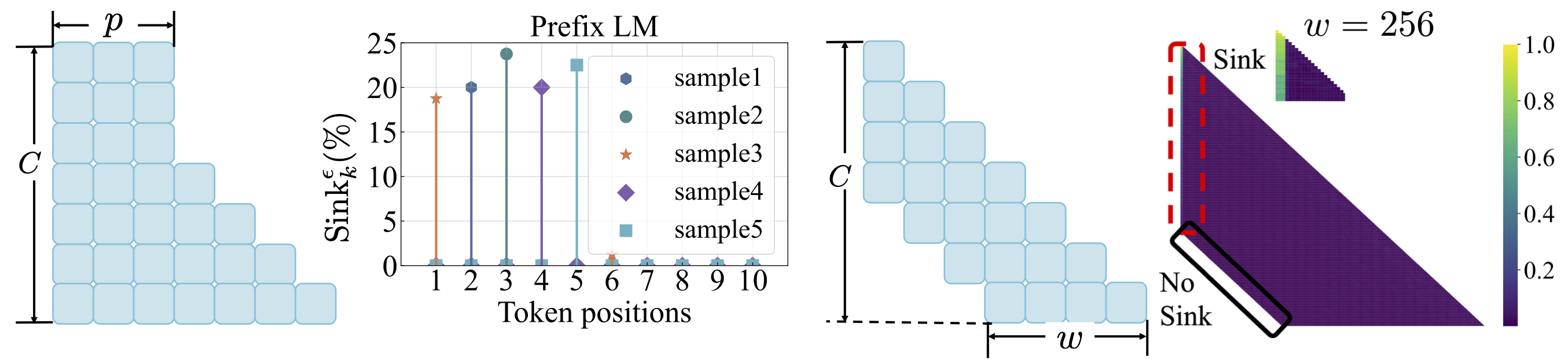
손실 기능 : scripts/loss_function.md 를 참조하십시오. 테이크 아웃 : 1. 체중 부패는주의 싱크의 출현을 장려합니다. 2. 접두사 언어 모델링을 사용하면 첫 번째 토큰이 아닌 접두사 토큰 사이에주의 싱크가 나타납니다. 3. 윈도우주의가 이동 한 상태에서,주의 싱크대는 상대적인 첫 토큰이 아니라 절대에 나타납니다. 창 크기가 작을수록주의 싱크대의 출현을 방지합니다.
scripts/model_architecture.md 를 참조하십시오. 테이크 아웃 : 1. 위치 임베딩, FFN 디자인, LN 위치 및 다중 헤드 디자인은주의 싱크의 출현에 영향을 미치지 않습니다. 2.주의 싱크대는 주요 편견처럼 작용하여 추가주의를 기울이고 가치 계산에 기여하지 않습니다. 3.주의 점수에 대한 토큰의 내면 의존도를 이완시킬 때 LMS에서주의 싱크가 나타나지 않습니다. 

마지막으로, 모델 크기를 1B 매개 변수로 확장하고 여전히주의 싱크대와 대규모 활성화가 없습니다. 기본적으로 8 GPU를 사용하여 다음 스크립트를 실행합니다.
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.sh이 프로젝트가 귀하의 연구에 유용하다고 생각되면, 우리의 논문을 인용하는 것을 고려하십시오.
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
우리의 코드는 Tinyllama와 Regmix를 기반으로 개발되었습니다.


