Attention Sink
1.0.0
[arxiv]
この作業では、LMの最適化、データ分布、損失機能、およびモデルアーキテクチャが、注意シンクの出現にどのように影響するかを調査します。
40GBメモリを使用して、すべての実験をA100 GPUで実行します。 TinyllamaとRegmixに従って環境を準備します。
CUDA 11.8がインストールされていることを期待しています。
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' 注:2023/09/02の時点で、Xformersはトーチ2.1に事前に構築されたバイナリを提供していません。ソースから構築する必要があります。
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
他の依存関係をインストールします。 Xformers/Flash-Attentionを構築するのに> = 5分かかる場合があります。プロセスが停滞しているように見えるか、端末が多くの警告を印刷しても心配しないでください。
モデルをトレーニングする前に、データを前処理する必要があります。データを前処理するための使いやすいスクリプトを提供します。次のコマンドを使用して、データを前処理できます。
cd preprocess
bash run_preprocess.shデフォルトでは、最初にHuggingfaceからregmix-data-sampleをダウンロードしてから、データを事前に処理します。 JSONLデータはpreprocess/sail/regmix-data-sampleディレクトリに保存され、Preprocessedデータはdatasets/lit_dataset_regmixディレクトリに保存されます。これには約5Bのトークンが含まれ、約20GBのディスクスペースが必要です。
デフォルトでは、WANDBを使用してデータを収集して、ローカルマシンに大規模な小さなモデルやログを保存しないようにします。 WandBを使用する場合は、WandBにアカウントを作成してAPIキーを取得する必要があります。次に、 scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY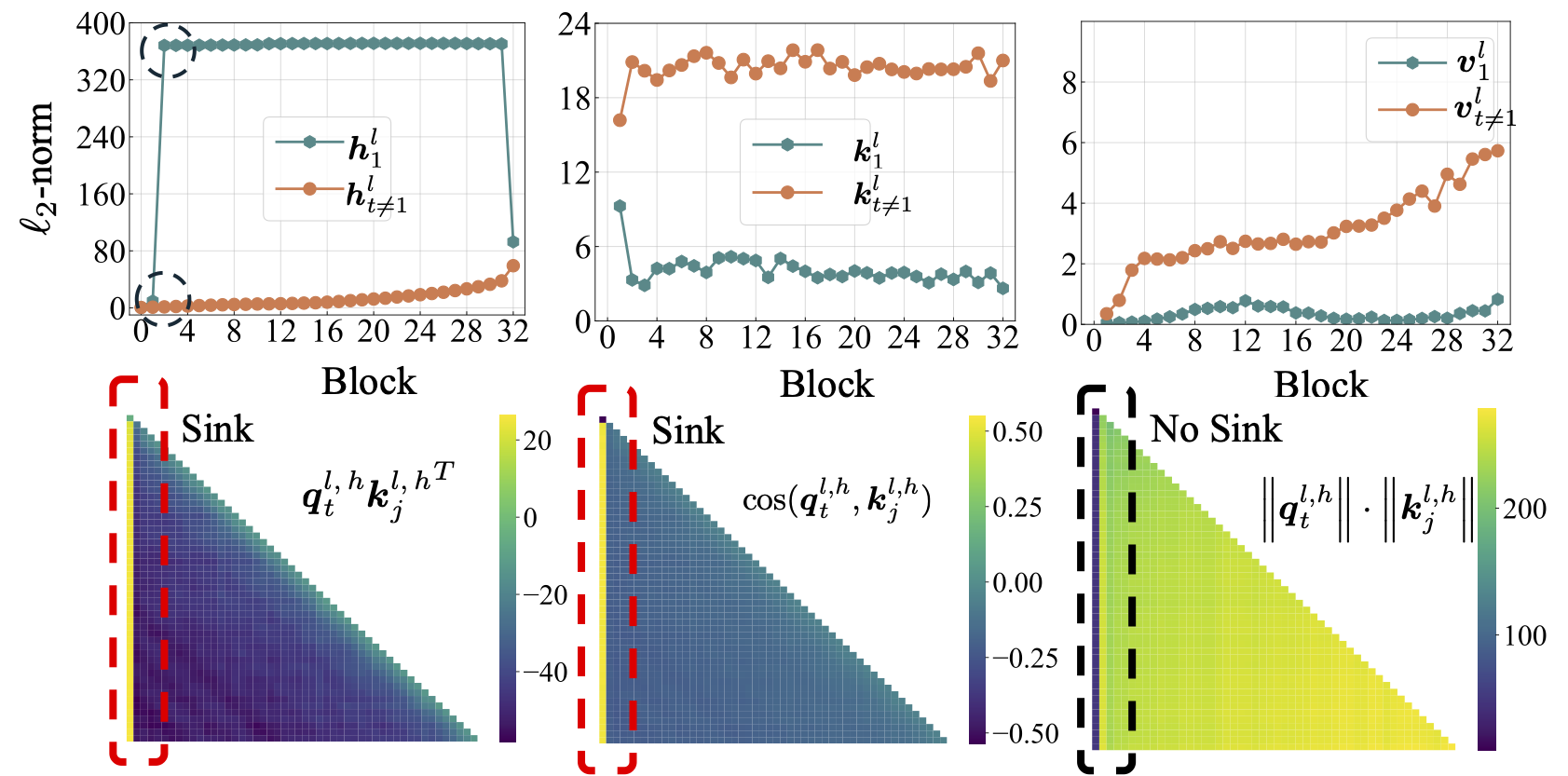
最初に、Llama2、Llama3、Mistral、GPT2、Pythia、Optなど、オープンソースのLMSに関する包括的な研究を実施します。上記のLMSの注意シンクメトリックを計算するスクリプトを提供します。
python eval_sink_open_source.pyまた、隠された状態、キー、値のL2-Normを計算するスクリプトも提供します。
python eval_activations_open_source.py単一のスクリプトに30個すべてのオープンソースLMSの評価を含めることに注意してください。これには、モデルをダウンロードするのに長い時間がかかる場合があります。特定のLMSを評価するために、 eval_sink_open_source.pyまたはeval_activations_open_source.pyのeval_sink_open_source.pyまたは104-110の行を変更してください。
5Bトークンデータの一連のLlamaモデルを事前にトレーニングして、LMプリトレーニングの最適化、データ、損失機能、およびモデルの痛みが注意シンクにどのように影響するかを調査します。
セットアップが異なると、メモリの使用が異なる場合があり、ServealセットアップはFlashの注意と互換性がありません。フォルダーlit_gptには、モデルの事前トレーニングと推論のための異なるコードベースがある場合があります。コードをより簡潔で効率的にするために、コミュニティからの貢献を歓迎します。
余分な指示がない限り、後に続く実験では、少なくとも40 GBのメモリを備えた4つのGPUが必要です。 configs/*.yamlのマイクロバッチサイズを変更してください。
デフォルトのセットアップを実行します:
bash scripts/run_defaults_60m.sh最終チェックポイントはcheckpoints/tinyllama_60M/iter-020000-ckpt.pthに保存されます。
メインペーパーで実験結果を再現するためのすべてのスクリプトを提供します。
最適化: scripts/optimization.mdを参照してください。テイクアウト:1。LMSが効果的に訓練された後、注意シンクが現れます。 2。注意シンクは、小さな学習率で訓練されたLMSではあまり明白ではないように見えます。
データ分布: scripts/data_distribution.mdを参照してください。テイクアウト:1。LMSが十分なトレーニングデータでトレーニングされた後、注意シンクが現れます。 2。データ分布を変更する場合、注意シンクは最初のトークンではなく、他の位置に移行できます。
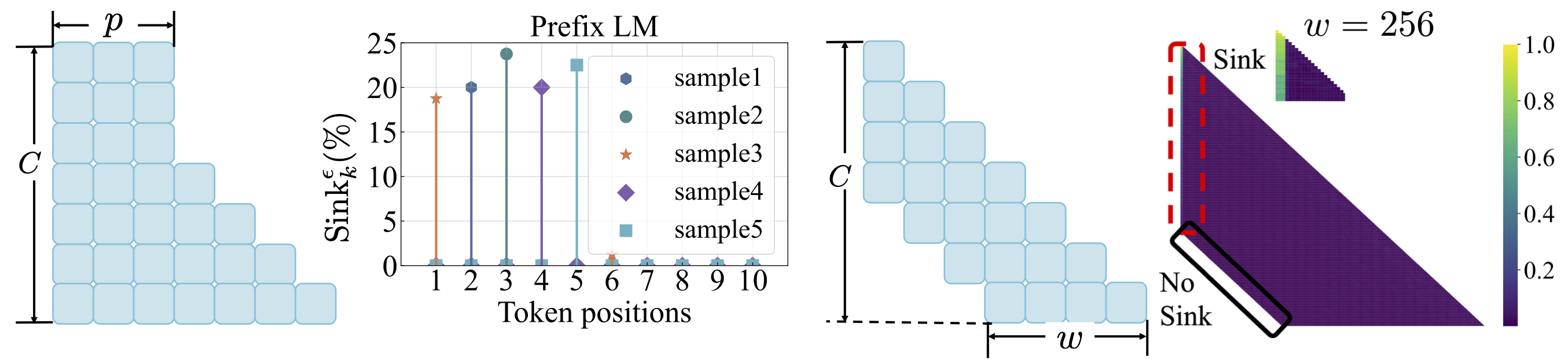
損失関数: scripts/loss_function.mdを参照してください。テイクアウト:1。体重減衰は注意シンクの出現を促進します。 2。プレフィックス言語モデリングでは、最初のトークンのみではなく、プレフィックストークンの間に注意シンクが表示されます。 3。窓の注意がシフトした場合、相対的な最初のトークンではなく、絶対に注意シンクが現れます。ウィンドウサイズが小さくなると、注意シンクの出現が防止されます。
scripts/model_architecture.mdを参照してください。テイクアウト:1。位置埋め込み、FFN設計、LNの位置、およびマルチヘッド設計は、注意シンクの出現に影響しません。 2。注意シンクは、重要なバイアスのように機能し、特別な注意を蓄え、その間に価値計算に貢献しません。 3.トークンの注意スコアへの内部依存をリラックスさせると、LMSでは注意シンクが現れません。 

最後に、モデルサイズを1Bパラメーターにスケールアップしますが、シンクと大規模なアクティベーションはまだありません。デフォルトでは、8つのGPUを使用して次のスクリプトを実行します
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shこのプロジェクトがあなたの研究で役立つと思うなら、私たちの論文を引用することを検討してください:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
私たちのコードは、TinyllamaとRegmixに基づいて開発されています。


