Attention Sink
1.0.0
[arxiv]
В этой работе мы исследуем, как оптимизация, распределение данных, функция потерь и архитектура модели в предварительном обучении LM влияют на появление погружения внимания.
Мы проводим все наши эксперименты на графических процессорах A100 с памятью 40 ГБ. Мы следуем за Tinyllama и Regmix, чтобы подготовить среду:
Мы ожидаем, что у вас установлен CUDA 11.8.
pip install --index-url https://download.pytorch.org/whl/nightly/cu118 --pre ' torch>=2.1.0dev ' Примечание: по состоянию на 2023/09/02 Xformers не предоставляют предварительно построенные двоичные файлы для Torch 2.1. Вы должны построить его из источника.
pip uninstall ninja -y && pip install ninja -U
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformersgit clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attention pip install -r requirements.txt tokenizers sentencepiece
Установить другие зависимости. Это может потребоваться> = 5 минут, чтобы построить Xformers/Flash-Attention. Не беспокойтесь, если процесс кажется застойным или терминал распечатывает много предупреждений.
Перед обучением модели вам необходимо предварительно обработать данные. Мы предоставляем простой в использовании сценарий для предварительной обработки данных. Вы можете использовать следующую команду для предварительной обработки данных:
cd preprocess
bash run_preprocess.sh По умолчанию вы сначала загрузите regmix-data-sample из HuggingFace, а затем предварительно предварительно обрабатывать данные. Данные JSONL будут сохранены в каталоге preprocess/sail/regmix-data-sample , а предварительные данные будут сохранены в каталоге datasets/lit_dataset_regmix . Это включает в себя приблизительно 5b токены и занимает около 20 ГБ дискового пространства.
По умолчанию мы используем Wandb для сбора данных, чтобы избежать сохранения массивных небольших моделей и журналов на локальной машине. Если вы хотите использовать Wandb, вам нужно создать учетную запись на Wandb и получить ключ API. Затем вам следует установить следующую переменную среды в scripts/*.sh :
# wandb project name, entity, and API key
export WANDB_PROJECT=YOUR_PROJECT_NAME
export WANDB_ENTITY=YOUR_WANDB_ENTITY
export WANDB_API_KEY=YOUR_WANDB_API_KEY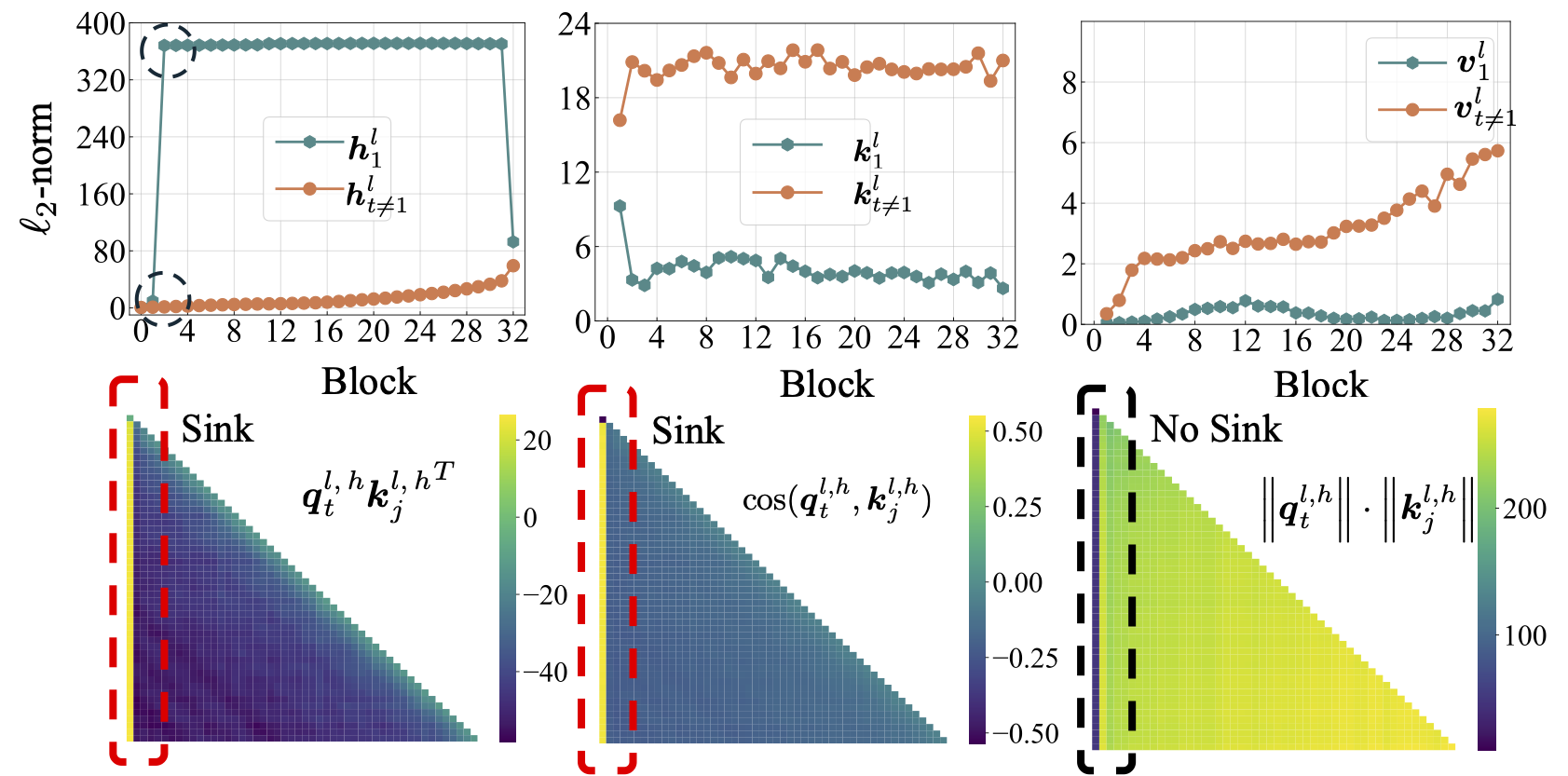
Сначала мы проводим всеобъемлющее исследование LMS с открытым исходным кодом, в том числе Llama2, Llama3, Mistral, GPT2, Pythia и Opt. Мы предоставляем сценарий для расчета метрики раковины внимания для вышеуказанного LMS:
python eval_sink_open_source.pyМы также предоставляем сценарий для вычисления L2-норма скрытых состояний, ключей и значений:
python eval_activations_open_source.py Мы отмечаем, что мы включаем оценки всех 30 LMS с открытым исходным кодом в один сценарий, который может занять много времени для загрузки моделей. Пожалуйста, измените строку 57-63 в eval_sink_open_source.py или строке 104-110 в eval_activations_open_source.py , чтобы оценить конкретные LMS.
Мы предварительно готовим серию моделей LLAMA на данных токена 5B, чтобы исследовать, как оптимизация, данные, функция потерь и модель ACHITECTURE в предварительном обучении LM влияют на погружение внимания.
Различные настройки могут привести к различному использованию памяти, а настройки обслуживания не очень совместимы с вниманием. У нас могут быть разные кодовые базы для предварительного обучения модели и вывода в папке lit_gpt . Мы приветствуем вклад сообщества, чтобы сделать код более кратким и эффективным.
Если только дополнительные инструкции, следующие эксперименты требуют 4 графических процессоров с памятью не менее 40 ГБ. Пожалуйста, измените размер микро -партии в configs/*.yaml .
Запустите настройку по умолчанию:
bash scripts/run_defaults_60m.sh Последняя контрольная точка сохраняется на checkpoints/tinyllama_60M/iter-020000-ckpt.pth .
Мы предоставляем все сценарии, чтобы воспроизвести наши экспериментальные результаты в основной статье.
Оптимизация: см. scripts/optimization.md . Вынос: 1. Внимание раковина появляется после того, как LMS эффективно подготовлены. 2. Внимание погружение кажется менее очевидным в LMS, обученных небольшими показателями обучения.
Распределение данных: см. scripts/data_distribution.md . Вынос: 1. Внимание, раковина, появляется после того, как LMS обучаются достаточным учебным данным. 2. Внимание может быть перенесено на другие позиции, а не в первый токен при изменении распределения данных.
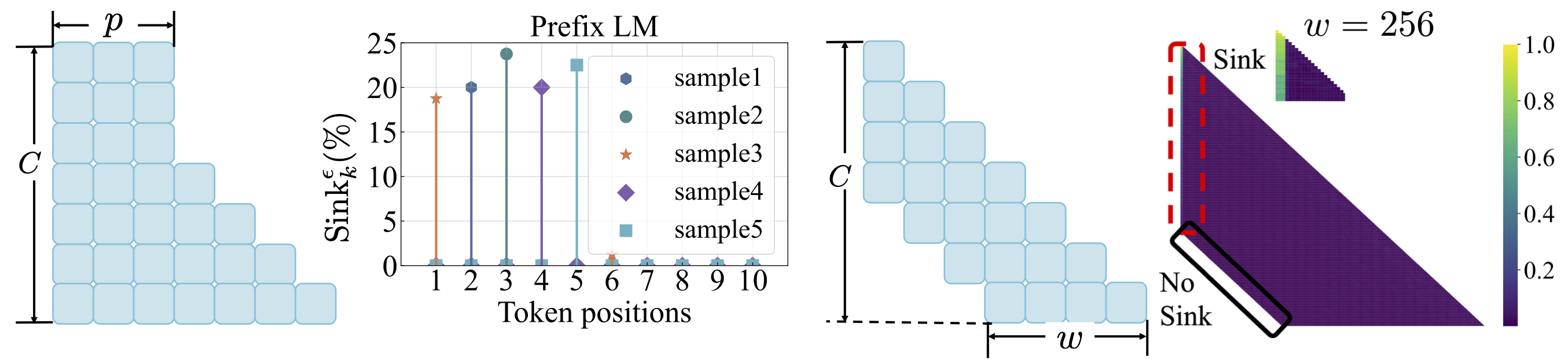
Функция потери: см. scripts/loss_function.md . Вынос: 1. Веса распад поощряет появление внимания. 2. При моделировании языка префикса, тона, погружаясь в токены префикса, а не только первый жетон. 3. С смещенным вниманием к окну, на абсолютном, не является относительным первым токеном, не является относительным. Меньший размер окна предотвращает появление внимания.
scripts/model_architecture.md . Вынос: 1. Позиционное внедрение, дизайн FFN, местоположение LN и многоголовный дизайн не влияют на появление погружения внимания. 2. Внимание погружается в большее похоже на смещения ключевых, сохраняя дополнительное внимание и тем временем не способствует вычислению значений. 3. При расслаблении внутренней зависимости токенов от результатов внимания, то, что погрузка внимания не появляется в LMS. 

Наконец, мы увеличиваем размер модели до параметров 1B и не находим никакого внимания погрузиться и массивные активации. По умолчанию мы используем 8 графических процессоров для запуска следующих сценариев
bash scripts/run_defaults_1b.sh
bash scripts/run_sigmoid_1b.shЕсли вы найдете этот проект полезным в своем исследовании, рассмотрите возможность ссылаться на нашу статью:
@article{gu2024attention,
title={When Attention Sink Emerges in Language Models: An Empirical View},
author={Gu, Xiangming and Pang, Tianyu and Du, Chao and Liu, Qian and Zhang, Fengzhuo and Du, Cunxiao and Wang, Ye and Lin, Min},
journal={arXiv preprint arXiv:2410.10781},
year={2024}
}
Наши коды разработаны на основе Tinyllama и Regmix.


