tying wv and wc
1.0.0
“绑定单词向量和单词分类器:语言建模的损失框架”的实现
本文试图利用单词的多样性来训练深层神经网络。
在语言建模(单词序列的预测)中,我们想表达单词含义的多样性。
例如,当预测“香蕉是美味的___”旁边的单词时,答案是“水果”,但“ sweets”,“食物”也可以。但是,普通的一旋向量教学不适合实现它。因为任何类似的词都被忽略了,但是确切的答案词。
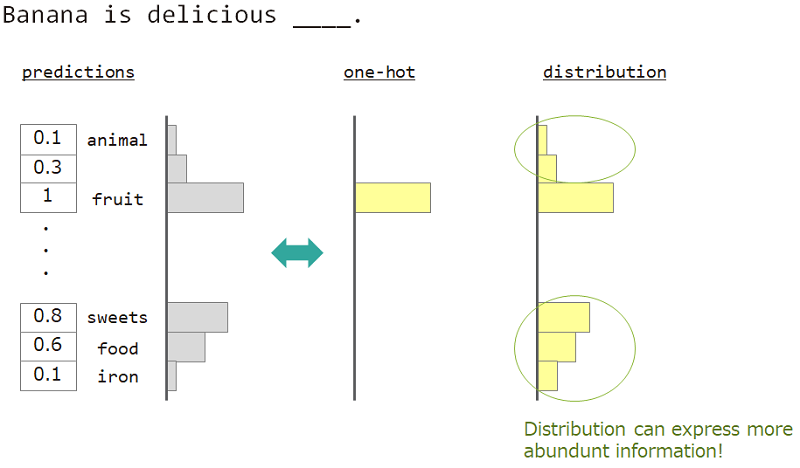
如果我们不能使用一局,而是“分发”,我们可以教这个品种。
因此,我们使用“单词的分布”来教授模型。此分布是从答案单词获得的,并嵌入了查找矩阵。


如果我们使用此分布类型损失,那么我们可以证明输入嵌入和输出投影矩阵之间的等效性。
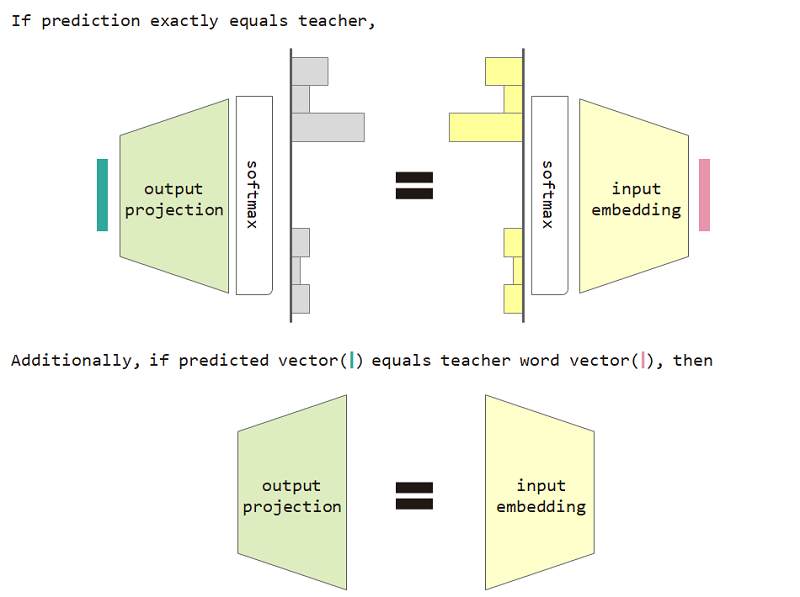
使用分布类型损失和输入嵌入和输出投影等价限制可改善模型的困惑。
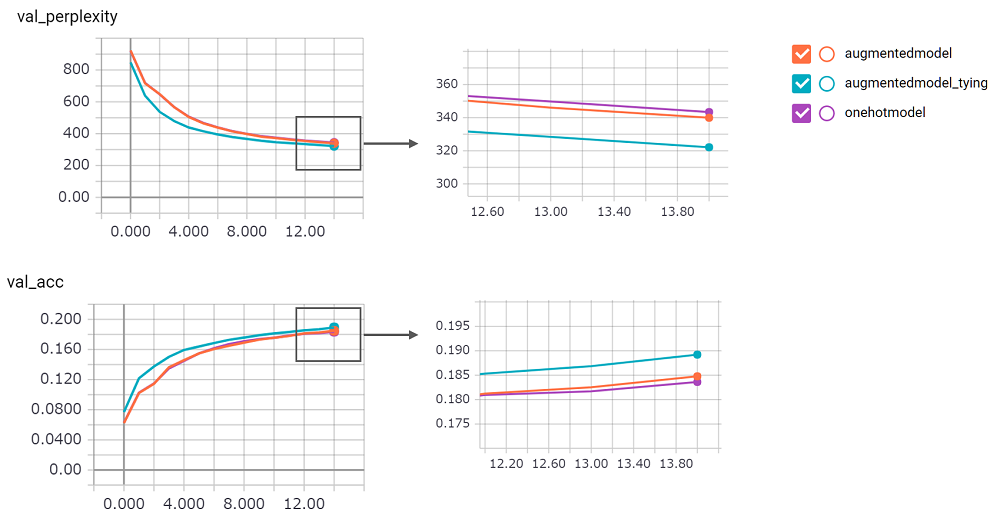
perplexity得分很高,我对其实施不信心。我在等拉请求!augmentedmodel比基线( onehotmodel )更好,并且augmentedmodel_tying表现优于基线!python train.py进行此实验我实施了状态LSTM版本。其结果如下。
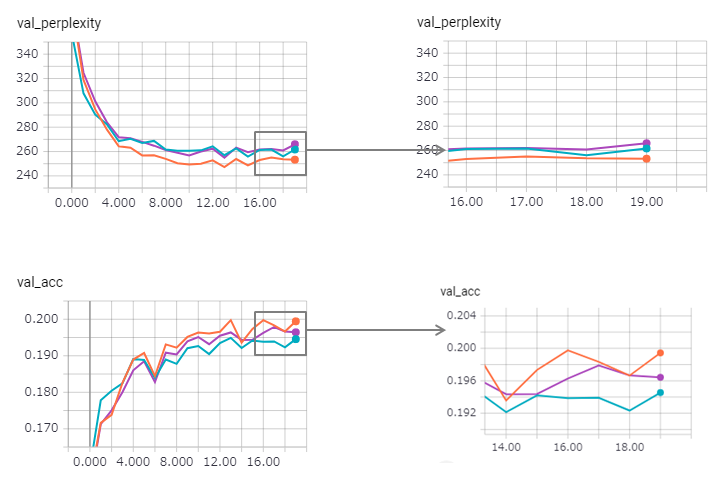
复杂性得到改善(但Zaggy),而绑定的方法略有失去其效果。
在keras中使用状态的LSTM太难了(尤其是验证集中的reset_states ),因此可能包含一定的限制。
顺便说一句,Pytorch示例已经使用了绑定方法!不要害怕使用它!


