tying wv and wc
1.0.0
"단어 벡터 및 단어 분류기 묶기 구현 : 언어 모델링을위한 손실 프레임 워크"
이 논문은 깊은 신경 네트워크를 훈련시키기 위해 다양한 단어 의미를 활용하려고합니다.
언어 모델링 (단어 시퀀스의 예측)에서 우리는 단어 의미의 다양성을 표현하려고합니다.
예를 들어, "바나나는 맛있는 ___"옆에있는 단어를 예측할 때 대답은 "과일"이지만 "과자", "음식"도 괜찮습니다. 그러나 평범한 일대일 벡터 교육은 그것을 달성하기에 적합하지 않습니다. 비슷한 단어가 무시되었지만 정확한 대답 단어.
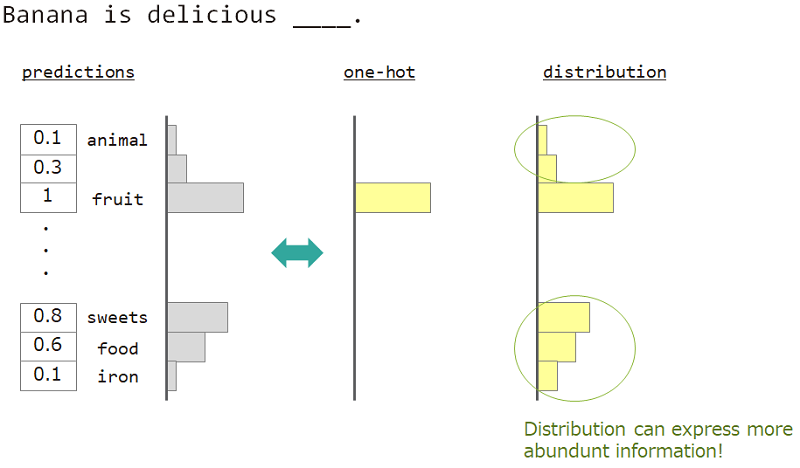
우리가 하나가 아니라 "분포"를 사용할 수 있다면, 우리는이 다양성을 가르 칠 수 있습니다.
그래서 우리는 모델을 가르치기 위해 "단어의 분포"를 사용합니다. 이 분포는 답변 단어 및 임베딩 조회 매트릭스에서 획득했습니다.


이 분포 유형 손실을 사용하면 입력 임베딩과 출력 투영 행렬 간의 동등성을 증명할 수 있습니다.
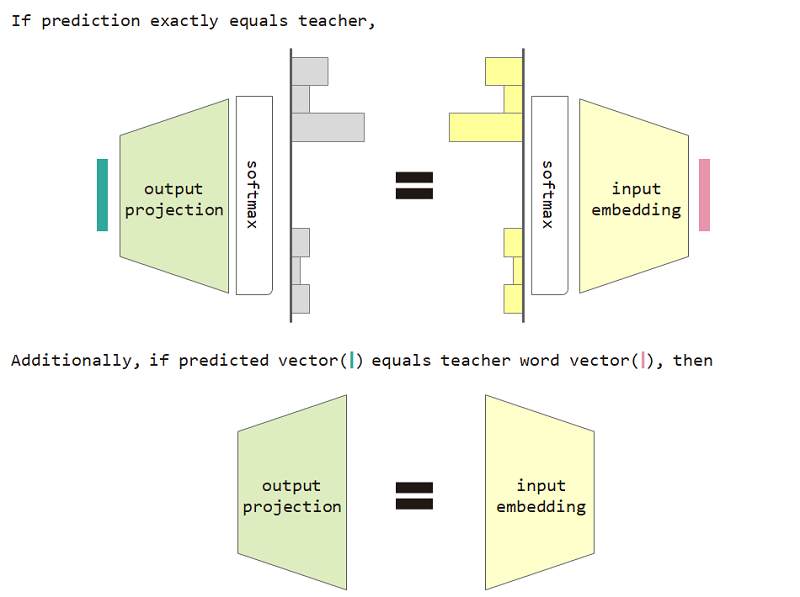
분포 유형 손실 및 입력 임베딩 및 출력 프로젝션 등가 제한을 사용하면 모델의 당혹감이 향상됩니다.
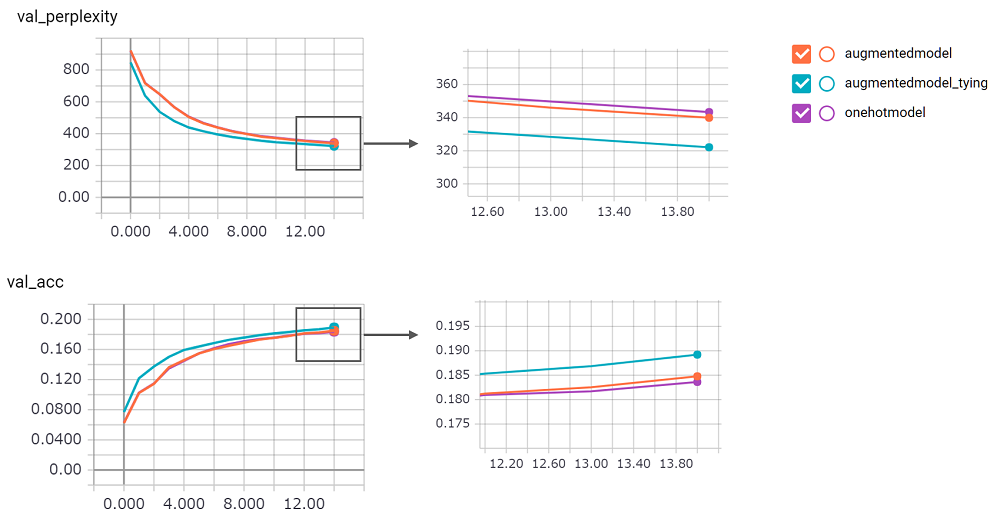
perplexity 점수는 크고 구현에 대한 확신이 없었습니다. 기다리고있는 풀 요청!augmentedmodel 기준선 ( onehotmodel )보다 더 잘 작동하며 augmentedmodel_tying 기준선보다 성능이 우수합니다!python train.py 로이 실험을 실행할 수 있습니다Stateful LSTM 버전을 구현했습니다. 다음과 같은 결과.
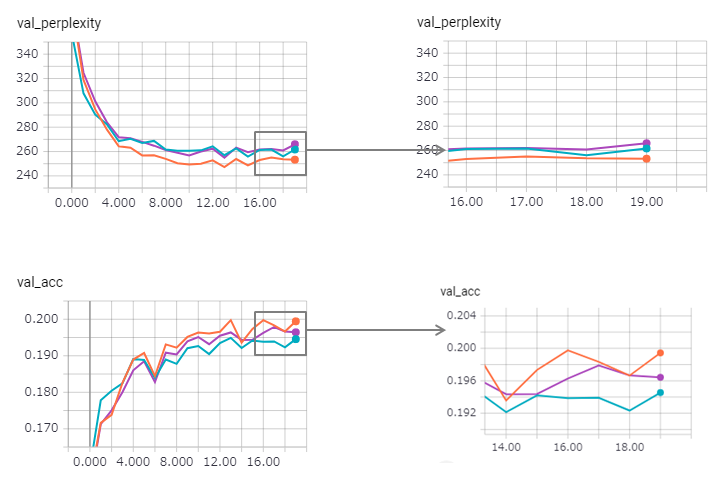
당혹감이 개선되었지만 (Zaggy), 묶는 방법은 그 효과를 약간 잃게됩니다.
Keras에서 Stateful LSTM을 사용하는 것은 너무 어렵 기 때문에 (특히 유효성 검사 세트의 reset_states ) 일부 제한이 포함될 수 있습니다.
그건 그렇고, Pytorch 예제는 이미 묶는 방법을 사용하고 있습니다! 그것을 사용하는 것을 두려워하지 마십시오!


