tying wv and wc
1.0.0
Implementierung für "Word -Vektoren und Wortklassifizierer: Ein Verlust -Framework für die Sprachmodellierung"
Dieses Papier versucht, die Vielfalt des Wortes zu nutzen, um das tiefe neuronale Netzwerk auszubilden.
In der Sprachmodellierung (Vorhersage der Wortsequenz) möchten wir die Vielfalt der Wortbedeutung ausdrücken.
Wenn Sie beispielsweise das Wort neben "Banane ist köstlich ___" vorhersagen, lautet die Antwort "Frucht", aber "Süßigkeiten", "Essen" ist auch in Ordnung. Der normale One-Hot-Vektorunterricht ist jedoch nicht geeignet, um dies zu erreichen. Weil ähnliche Wörter ignoriert wurden, aber das genaue Antwortwort.
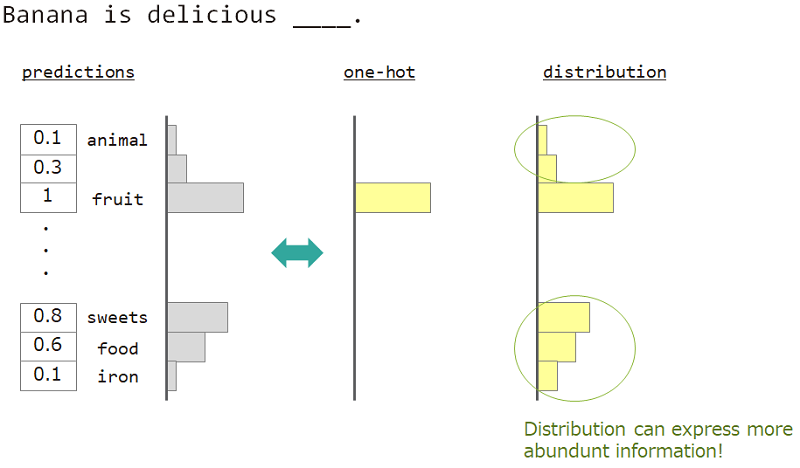
Wenn wir nicht in One heiß, sondern "Verteilung" verwenden können, können wir diese Sorte unterrichten.
Wir verwenden also "Verteilung des Wortes", um das Modell zu lehren. Diese Verteilung wurde aus dem Antwortwort und der Einbettung der Lookup -Matrix erworben.


Wenn wir diesen Verlust des Verteilertyps verwenden, können wir die Äquivalenz zwischen Eingangseinbettung und Ausgangsprojektionsmatrix nachweisen.
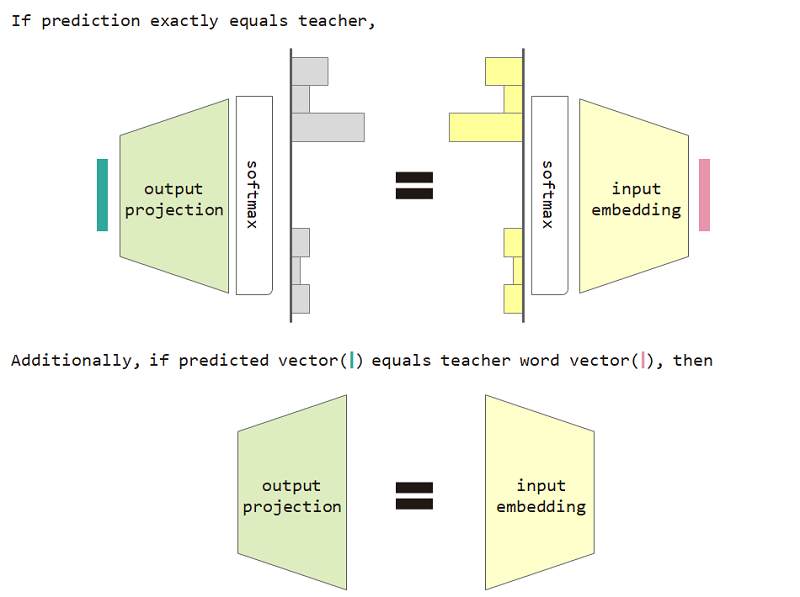
Um den Verlust des Verteilertyps und die Eingangs- und Ausgangsprojektionsäquivalenzbeschränkung zu verwenden, verbessert die Verwirrung des Modells.
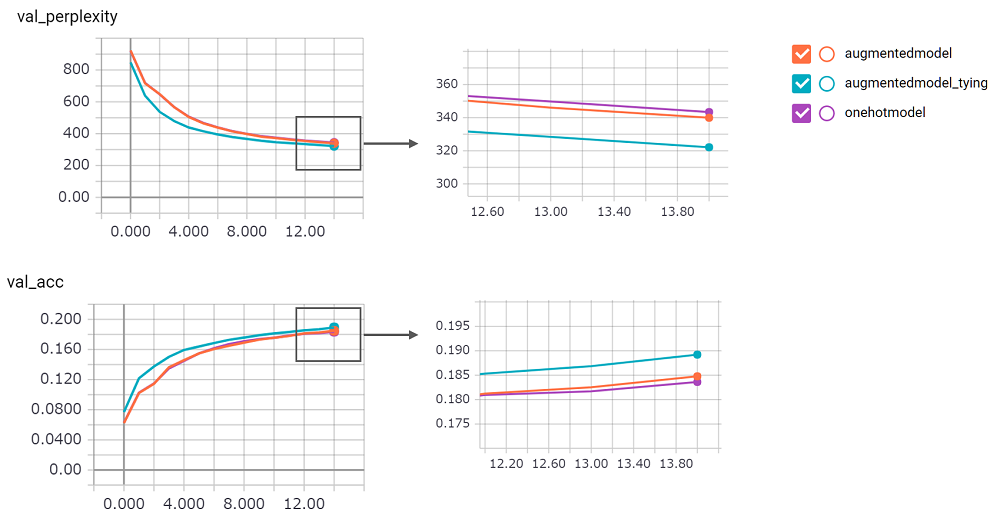
perplexity ist groß, ich konnte kein Vertrauen in seine Umsetzung haben. Ich warte an Pull Anfrage!augmentedmodel funktioniert besser als die Basislinie ( onehotmodel ), und augmentedmodel_tying übertrifft die Basislinie!python train.py durchführenIch habe eine staatliche LSTM -Version implementiert. Sein Ergebnis wie folgt.
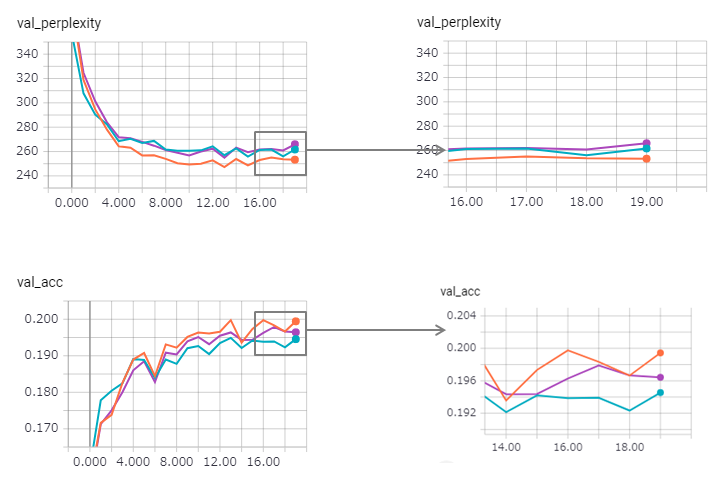
Die Verwirrung wird verbessert (aber zaggy) und die Bindungsmethode verliert ihre Wirkung ein wenig.
Die Verwendung eines staatlichen LSTM in Keras ist zu schwer (insbesondere im Validierungssatz reset_states ), sodass möglicherweise ein gewisses Grenzwert enthalten ist.
Übrigens verwenden Pytorch -Beispiel bereits die Bindungsmethode! Haben Sie keine Angst, es zu benutzen!


