tying wv and wc
1.0.0
Implementação para "vinculando vetores de palavras e classificadores de palavras: uma estrutura de perda para modelagem de idiomas"
Este artigo tenta utilizar a diversidade de significado de palavras para treinar a profunda rede neural.
Na modelagem de idiomas (previsão da sequência de palavras), queremos expressar a diversidade do significado da palavra.
Por exemplo, ao prever a palavra ao lado de "Banana é deliciosa ___", a resposta é "fruta", mas "doces", "comida" também está ok. Mas o ensino vetorial comum de um quente não é adequado para alcançá-lo. Porque quaisquer palavras semelhantes ignoradas, mas a palavra de resposta exata.
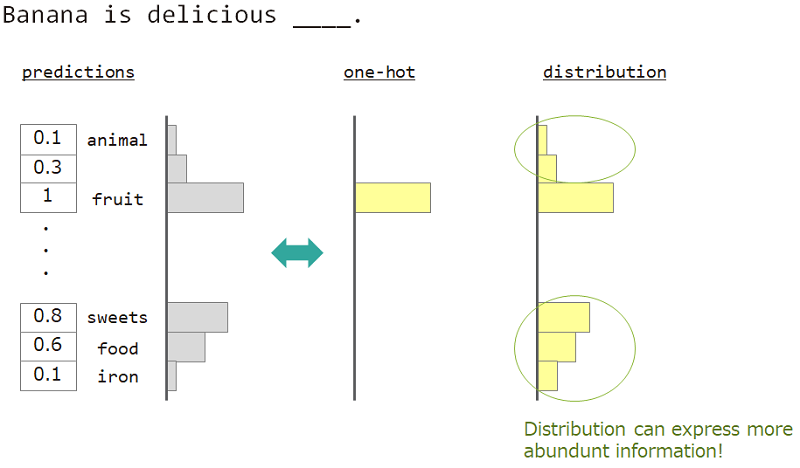
Se pudermos usar não um, mas "distribuição", podemos ensinar essa variedade.
Por isso, usamos "distribuição da palavra" para ensinar o modelo. Esta distribuição adquirida da palavra de resposta e incorporando a matriz de pesquisa.


Se usarmos essa perda de tipo de distribuição, podemos provar a equivalência entre a matriz de incorporação de entrada e projeção de saída.
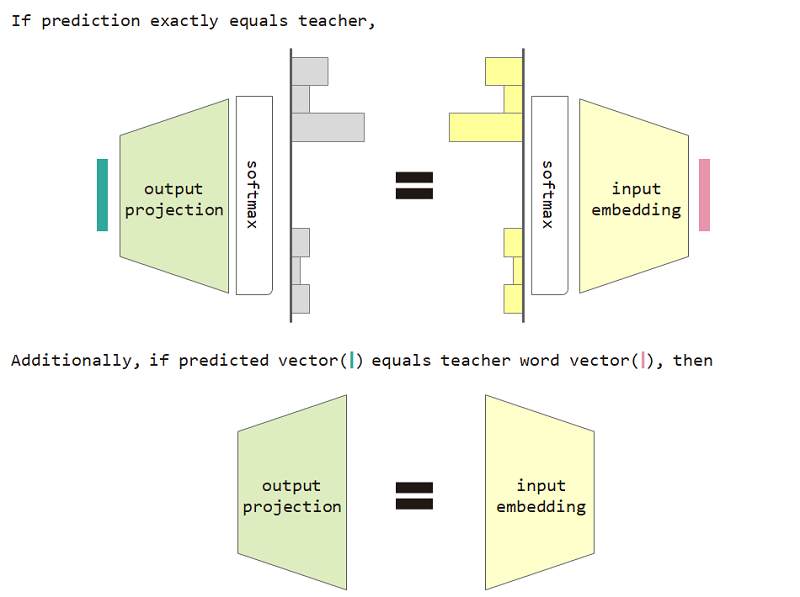
Para usar a restrição de equivalência de projeção e projeção de saída do tipo de distribuição e incorporação de entrada, melhora a perplexidade do modelo.
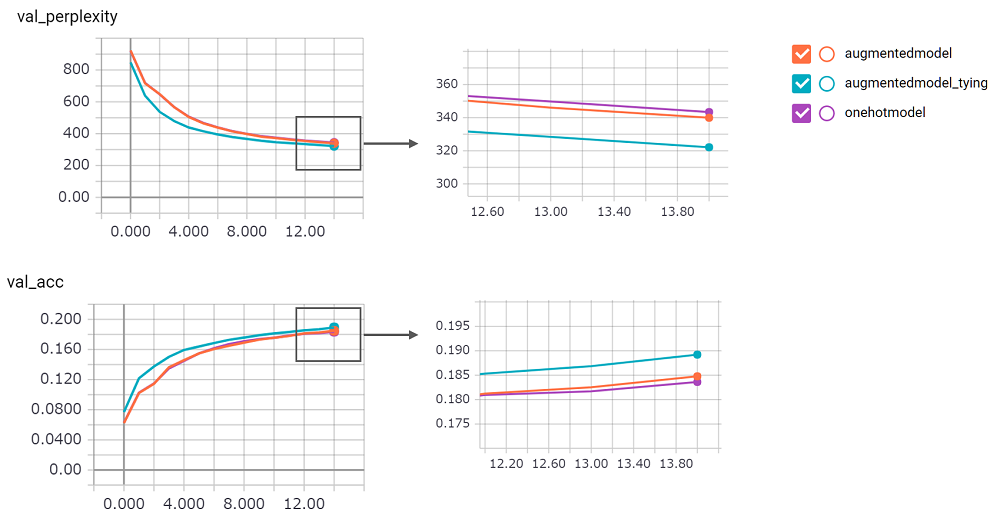
perplexity é grande, eu não poderia confiar em sua implementação. Estou esperando um pedido de puxão!augmentedmodel funciona melhor que a linha de base ( onehotmodel ) e augmentedmodel_tying supera a linha de base!python train.pyEu implementei a versão LSTM Stateful. Seu resultado como seguinte.
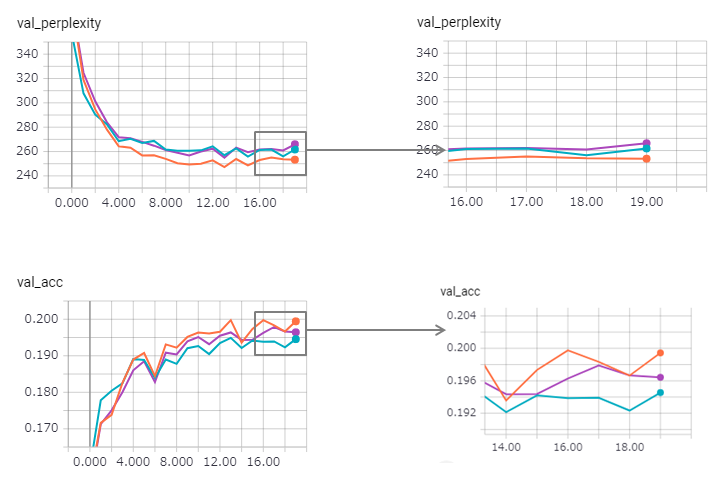
A perplexidade é melhorada (mas Zaggy), e o método de vinculação perde um pouco seu efeito.
Usar o LSTM com estado em Keras é muito difícil (especialmente reset_states no conjunto de validação), portanto, pode haver algum limite incluído.
A propósito, o exemplo de pytorch já usa o método de amarração! Não tenha medo de usá -lo!


