tying wv and wc
1.0.0
Implementación para "Vectores de palabras y clasificadores de palabras: un marco de pérdida para el modelado de idiomas"
Este documento intenta utilizar la diversidad de la palabra que significa capacitar a la red neuronal profunda.
En el modelado de idiomas (predicción de la secuencia de la palabra), queremos expresar la diversidad del significado de la palabra.
Por ejemplo, al predecir la palabra junto a "el plátano está delicioso ___", la respuesta es "fruta", pero "dulces", "comida" también está bien. Pero la enseñanza vectorial ordinaria no es adecuada para lograrlo. Porque se ignoró cualquier palabra similar, pero la palabra de respuesta exacta.
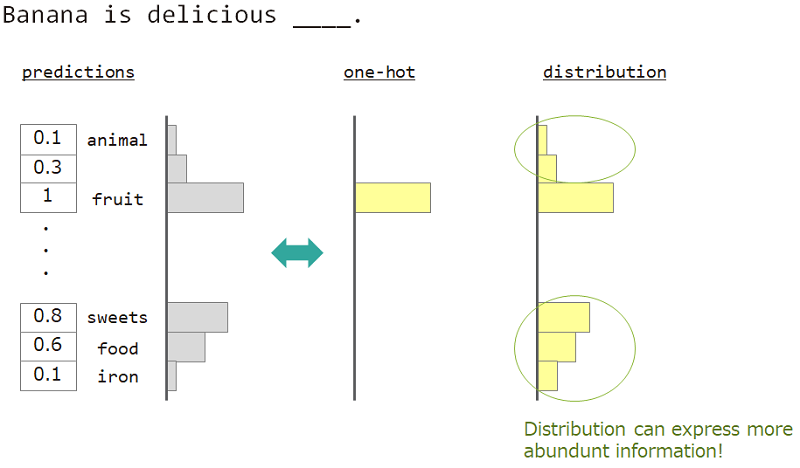
Si podemos usar no un solo candente sino "distribución", podemos enseñar esta variedad.
Entonces usamos "distribución de la palabra" para enseñar el modelo. Esta distribución adquirida de la palabra de respuesta e incrustación de la matriz de búsqueda.


Si usamos esta pérdida de tipo de distribución, entonces podemos probar la equivalencia entre la incrustación de entrada y la matriz de proyección de salida.
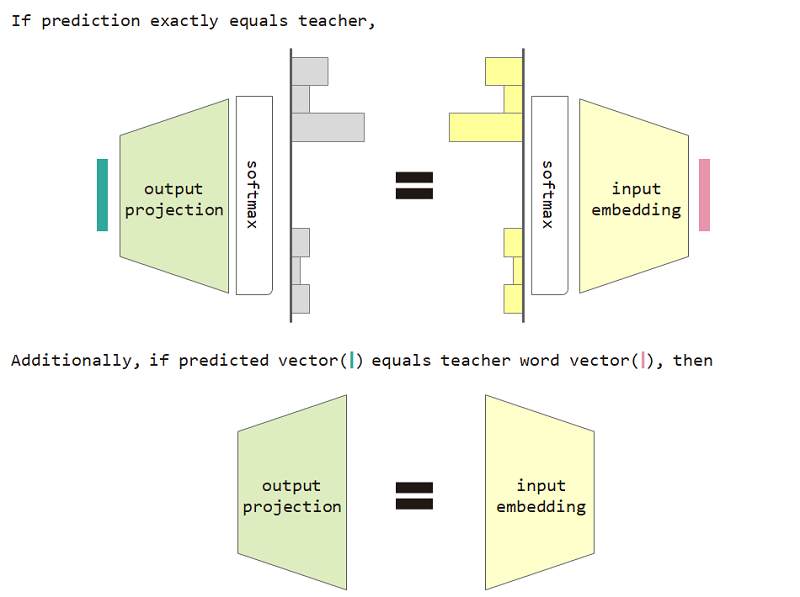
Usar la pérdida del tipo de distribución y la incrustación de entrada y la restricción de equivalencia de proyección de salida mejora la perplejidad del modelo.
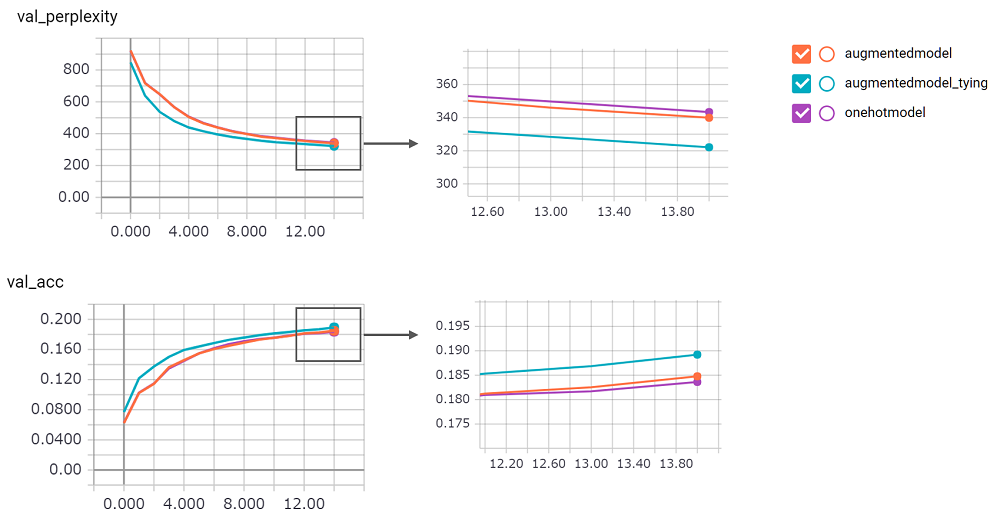
perplexity es grande, no podría confiar en su implementación. ¡Estoy esperando la solicitud de extracción!augmentedmodel funciona mejor que la línea de base ( onehotmodel ), y augmentedmodel_tying supera la línea de base!python train.pyImplementé la versión LSTM de estado. Su resultado según lo siguiente.
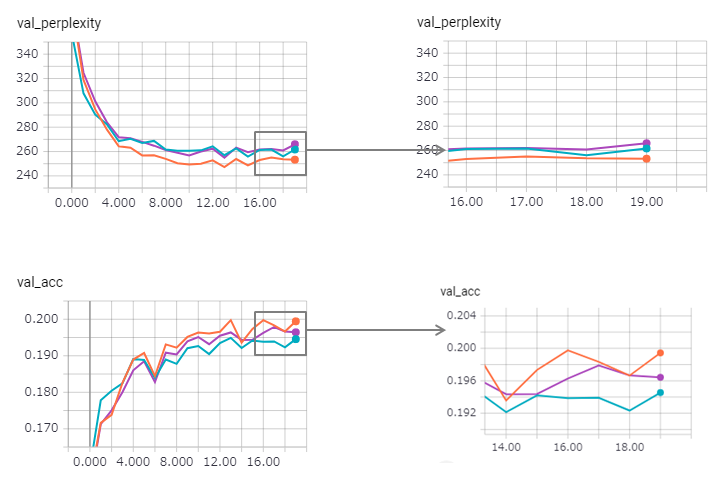
Se mejora la perplejidad (pero Zaggy), y el método de atado pierde un poco su efecto.
Usar LSTM en estado en Keras es demasiado difícil (especialmente reset_states en el conjunto de validación), por lo que puede haber algún límite incluido.
Por cierto, ¡el ejemplo de Pytorch ya usa el método de atado! ¡No tengas miedo de usarlo!


