tying wv and wc
1.0.0
การใช้งานสำหรับ "การผูกเวคเตอร์คำและตัวแยกประเภทคำ: กรอบการสูญเสียสำหรับการสร้างแบบจำลองภาษา"
บทความนี้พยายามที่จะใช้ความหลากหลายของคำหมายถึงการฝึกอบรมเครือข่ายประสาทลึก
ในการสร้างแบบจำลองภาษา (การทำนายลำดับคำ) เราต้องการแสดงความหลากหลายของความหมายของคำ
ตัวอย่างเช่นเมื่อทำนายคำที่อยู่ถัดจาก "กล้วยอร่อย ___" คำตอบคือ "ผลไม้" แต่ "ขนม", "อาหาร" ก็โอเคเช่นกัน แต่การสอนเวกเตอร์ที่ร้อนแรงหนึ่งครั้งไม่เหมาะที่จะบรรลุเป้าหมาย เพราะคำใด ๆ ที่คล้ายกันถูกละเว้น แต่คำตอบที่แน่นอน
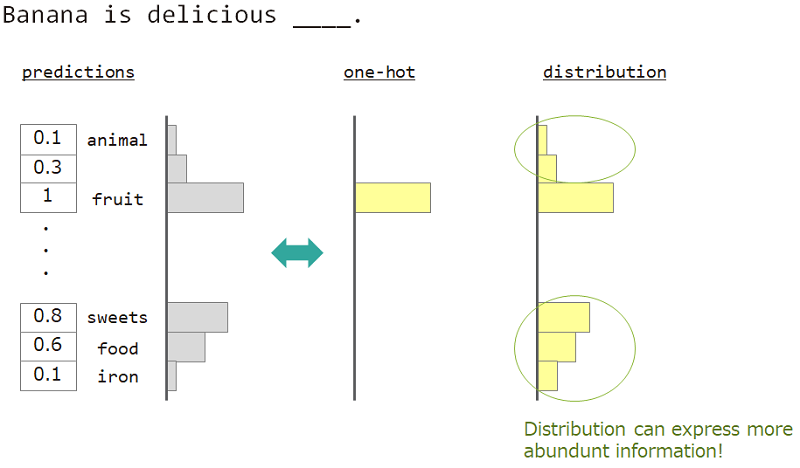
หากเราไม่สามารถใช้ความร้อนได้เพียงครั้งเดียว แต่ "การกระจาย" เราสามารถสอนความหลากหลายนี้ได้
ดังนั้นเราจึงใช้ "การกระจายของคำ" เพื่อสอนแบบจำลอง การกระจายนี้ได้มาจากคำตอบและเมทริกซ์การค้นหาแบบฝัง


หากเราใช้การสูญเสียประเภทการแจกแจงนี้เราสามารถพิสูจน์ความเท่าเทียมกันระหว่างเมทริกซ์การฝังอินพุตและเมทริกซ์การฉายเอาต์พุต
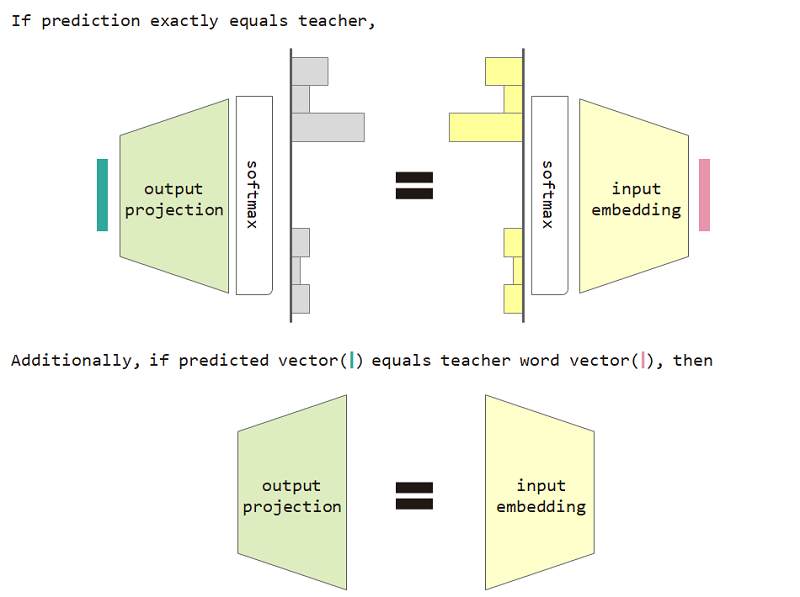
ในการใช้การสูญเสียประเภทการแจกแจงและการฝังอินพุตและการคาดการณ์การฉายภาพความเท่าเทียมกันช่วยเพิ่มความงุนงงของโมเดล
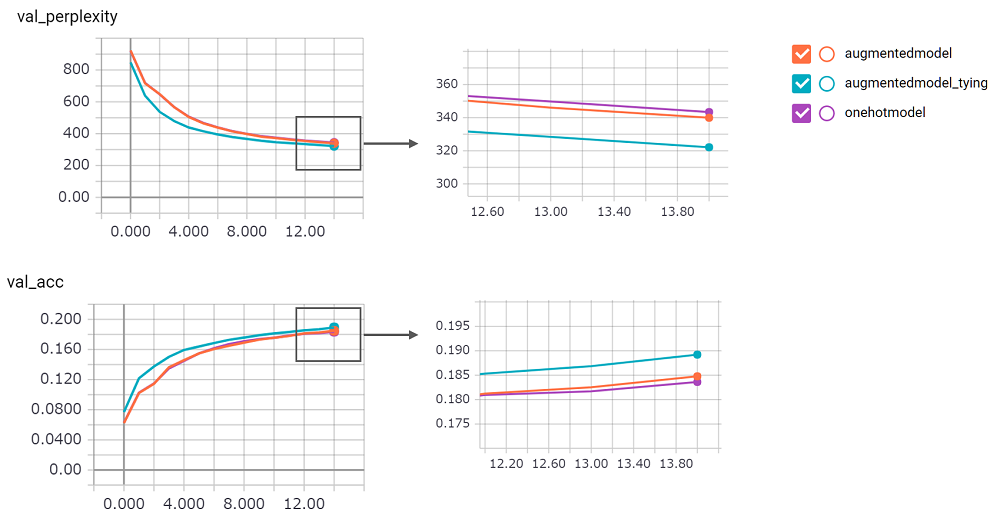
perplexity มีขนาดใหญ่ฉันไม่มั่นใจในการดำเนินการ ฉันกำลังรอคำขอดึง!augmentedmodel ทำงานได้ดีกว่า Baseline ( onehotmodel ) และ augmentedmodel_tying ดีกว่าพื้นฐาน!python train.pyฉันใช้เวอร์ชัน LSTM ที่มีสถานะ ผลลัพธ์ดังต่อไปนี้
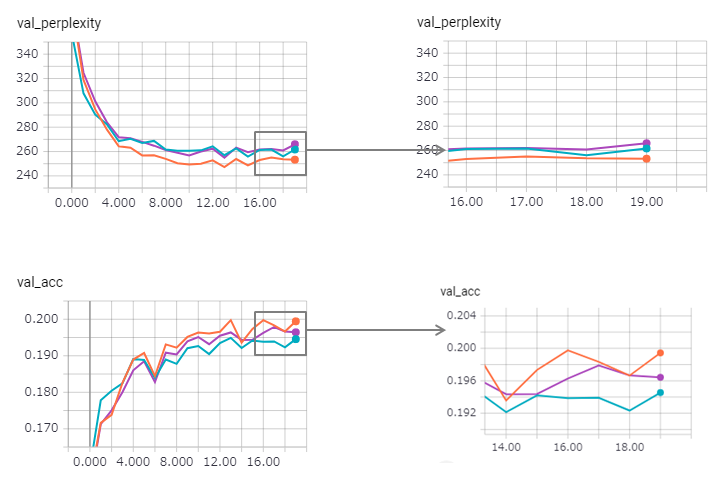
ความงุนงงได้รับการปรับปรุง (แต่ zaggy) และวิธีการผูกจะสูญเสียผลกระทบเล็กน้อย
ในการใช้ LSTM สถานะใน keras นั้นยากเกินไป (โดยเฉพาะอย่างยิ่ง reset_states ในชุดการตรวจสอบความถูกต้อง) ดังนั้นอาจมีข้อ จำกัด อยู่บ้าง
โดยวิธีการตัวอย่างของ Pytorch ใช้วิธีการผูกไว้แล้ว! อย่ากลัวที่จะใช้มัน!


