tying wv and wc
1.0.0
Implementasi untuk "mengikat vektor kata dan pengklasifikasi kata: kerangka kerugian untuk pemodelan bahasa"
Makalah ini mencoba memanfaatkan keragaman makna kata untuk melatih jaringan saraf yang dalam.
Dalam pemodelan bahasa (prediksi urutan kata), kami ingin mengekspresikan keragaman makna kata.
Misalnya, ketika memprediksi kata di sebelah "pisang adalah ___ lezat, jawabannya adalah" buah ", tetapi" permen "," makanan "juga baik -baik saja. Tetapi pengajaran vektor satu-panas biasa tidak cocok untuk mencapainya. Karena kata -kata serupa diabaikan, tetapi kata jawaban yang tepat.
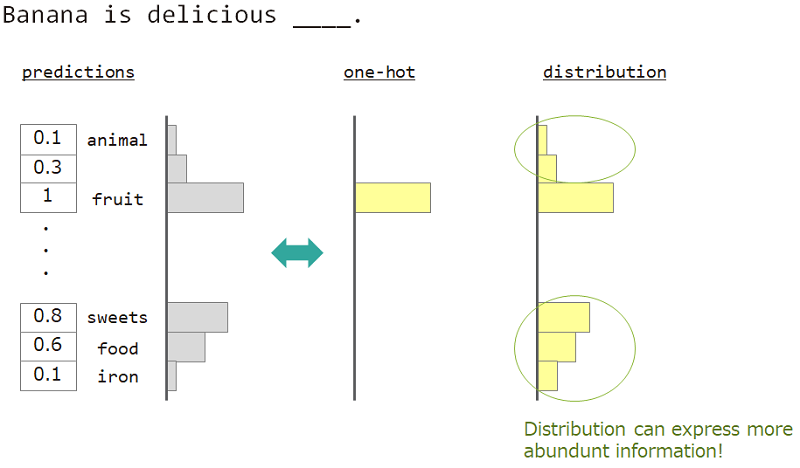
Jika kita dapat menggunakan bukan satu-panas tetapi "distribusi", kita dapat mengajarkan varietas ini.
Jadi kami menggunakan "distribusi kata" untuk mengajarkan model. Distribusi ini diperoleh dari kata jawaban dan matriks pencarian yang menanamkan.


Jika kita menggunakan kehilangan tipe distribusi ini, maka kita dapat membuktikan kesetaraan antara embedding input dan matriks proyeksi output.
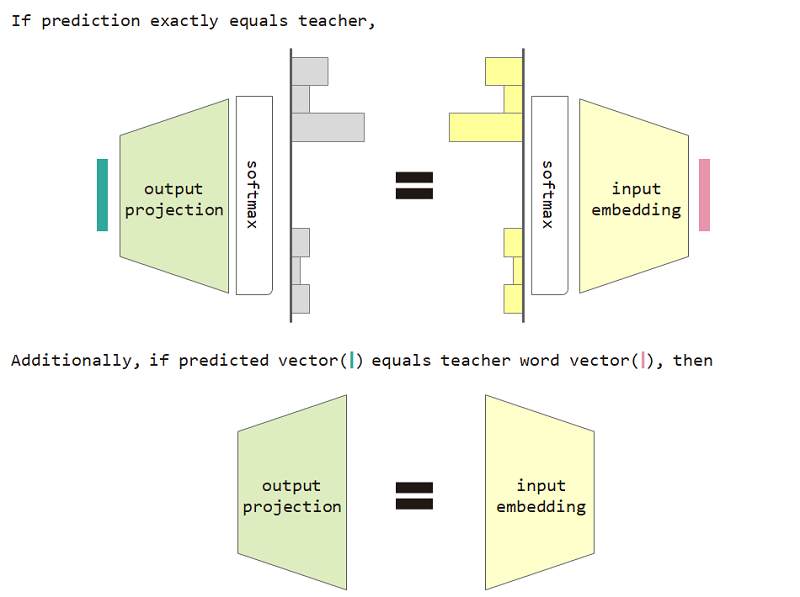
Untuk menggunakan kehilangan tipe distribusi dan penyematan input dan pembatasan kesetaraan proyeksi output meningkatkan kebingungan model.
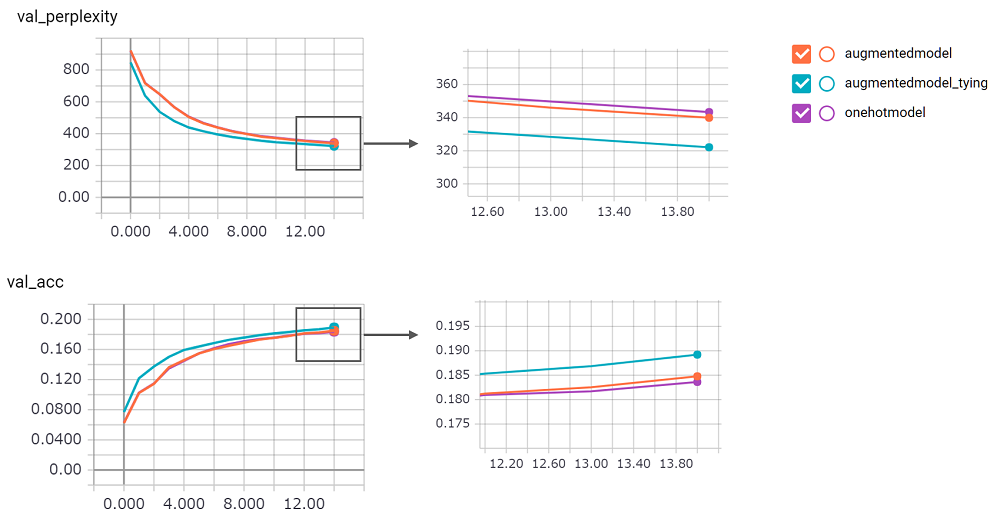
perplexity itu besar, saya tidak bisa memiliki kepercayaan diri implementasinya. Saya menunggu permintaan tarik!augmentedmodel bekerja lebih baik daripada baseline ( onehotmodel ), dan augmentedmodel_tying mengungguli baseline!python train.pySaya menerapkan versi LSTM stateful. Hasilnya sebagai berikut.
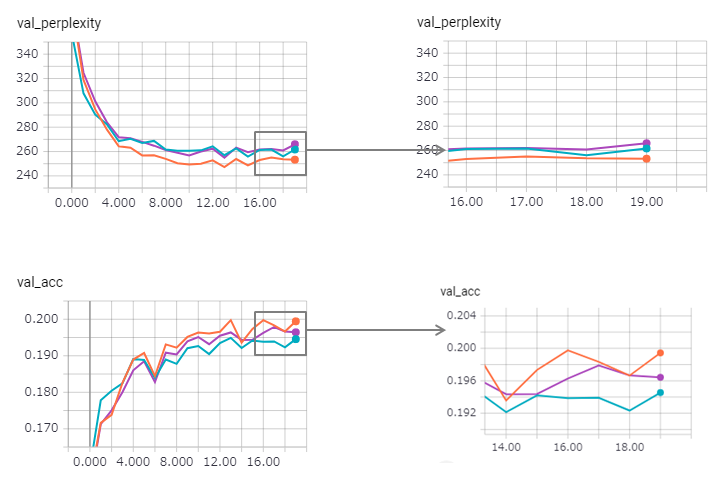
Kebingungan ditingkatkan (tetapi zaggy), dan metode pengikat sedikit kehilangan efeknya.
Untuk menggunakan LSTM stateful di keras terlalu keras (terutama reset_states dalam set validasi), jadi mungkin ada beberapa batas yang disertakan.
Ngomong -ngomong, contoh pytorch sudah menggunakan metode pengikat! Jangan takut menggunakannya!


