tying wv and wc
1.0.0
「単語ベクトルと単語分類器を結ぶための実装:言語モデリングのための損失フレームワーク」
この論文は、深いニューラルネットワークを訓練するために、単語の意味の多様性を利用しようとします。
言語モデリング(単語シーケンスの予測)では、単語の意味の多様性を表現したいと考えています。
たとえば、「バナナはおいしい___」の隣の単語を予測する場合、答えは「フルーツ」ですが、「お菓子」、「食べ物」も問題ありません。しかし、通常の1ホットのベクター教育は、それを達成するのに適していません。同様の単語は無視されたが、正確な回答語。
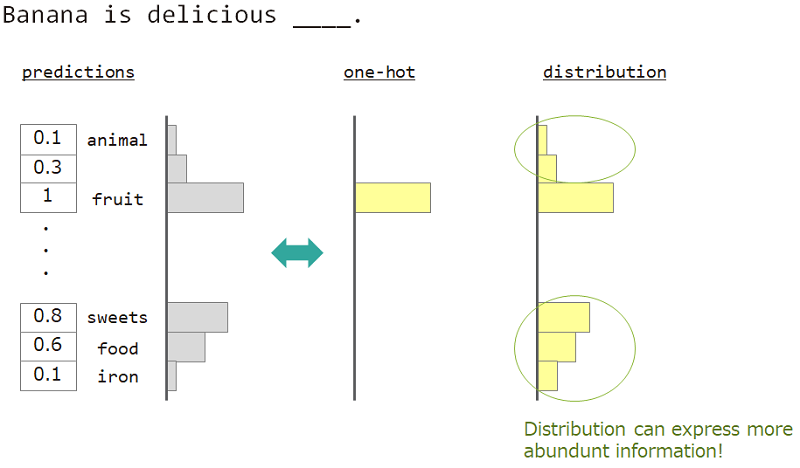
1ホットではなく「分布」を使用できれば、この多様性を教えることができます。
したがって、モデルを教えるために「単語の分布」を使用します。この分布は、回答語から取得し、ルックアップマトリックスを埋め込みました。


この分布タイプの損失を使用すると、入力埋め込みと出力投影マトリックスの等価性を証明できます。
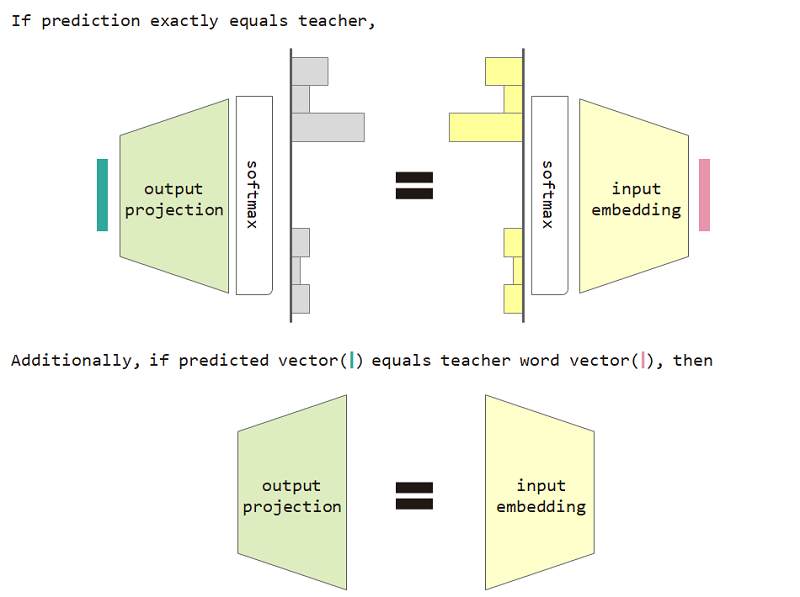
分布タイプの損失と入力埋め込みおよび出力投影等価制限を使用すると、モデルの困惑が向上します。
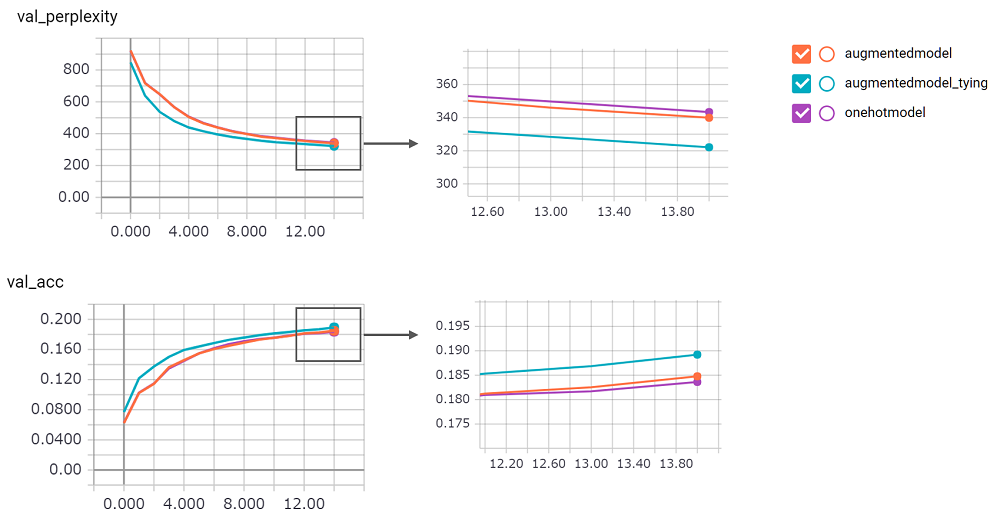
perplexityスコアは大きく、その実装に自信が持てませんでした。プルリクエストを待っています!augmentedmodelベースライン( onehotmodel )よりもうまく機能し、 augmentedmodel_tyingベースラインよりも優れています!python train.pyで実行できますStateful LSTMバージョンを実装しました。その結果は次のとおりです。
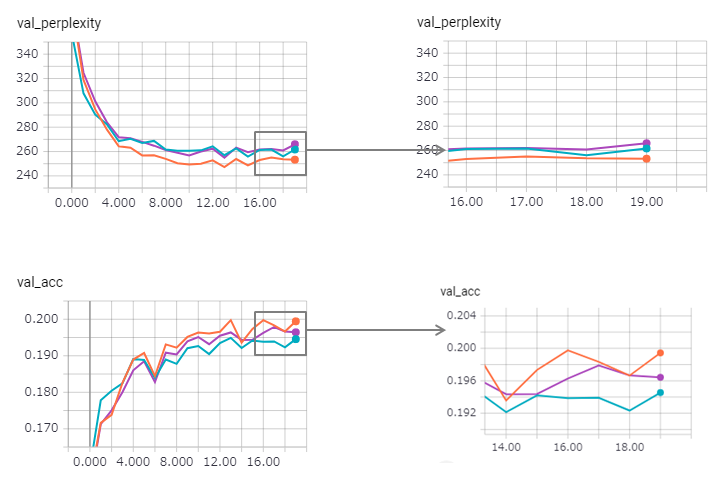
困惑が改善され(ただしZaggy)、タイインメソッドはその効果を少し失います。
KerasでStateful LSTMを使用するには、特に検証セットのreset_states )が難しすぎるため、制限が含まれている可能性があります。
ちなみに、Pytorchの例はすでにタイプ方法を使用しています!それを使うことを恐れないでください!


